HBase2.0集群部署(Ha)
开始部署HBase
对文档不理解的,想了解更多精彩的,请看对应视频地址:https://edu.csdn.net/course/detail/27060
版本为:hbase-2.0.2-bin.tar.gz
解压改名:
/export/server/hbase
1、配置文件 vim conf/hbase-env.sh
《1》去掉JAVA_HOME前面的注释,改为自己实际的JDK安装路径,和配置hadoop类似
![]()
export JAVA_HOME=/export/server/jdk1.8/
《2》去掉export HBASE_MANAGES_ZK=true前面的注释,并改为export HBASE_MANAGES_ZK=false,配置不让HBase管理Zookeeper
![]()
export HBASE_MANAGES_ZK=false
2、编辑文件 vim conf/hbase-site.xml
在hadoop中保存地址 -->
3、backup-masters(备用节点)生成
cd /export/server/hbase/conf
[root@sparktest141 conf]# vim backup-masters
sparktest141
sparktest145
4、其他配置文件
分别将hadoop配置下的core-site.xml和hdfs-site.xml复制或者做软链接到hbase配置目录下:
cp /export/server/hadoop/etc/hadoop/core-site.xml conf/
cp /export/server/hadoop/etc/hadoop/hdfs-site.xml conf/
软连接hadoop配置,替代上面的拷贝
[root@sparktest141 conf]# ln -s /export/server/hadoop/etc/hadoop/core-site.xml ./conf
[root@sparktest141 conf]# ln -s /export/server/hadoop/etc/hadoop/hdfs-site.xml ./conf
5、解决依赖问题
把相关版本的zookeeper和hadoop的依赖包导入到
hbase/lib下
[root@sparktest141 lib]# pwd
/export/server/hbase/lib
[root@sparktest141 lib]# cp -r /export/server/hadoop/share/hadoop/common/*.jar ./lib
[root@sparktest141 lib]# cp -r /export/server/hadoop/share/hadoop/common/lib/*.jar ./lib
[root@sparktest141 lib]# cp -r /export/server/hadoop/share/hadoop/hdfs/*.jar ./lib
[root@sparktest141 lib]# cp -r /export/server/hadoop/share/hadoop/hdfs/lib/*.jar ./lib
[root@sparktest141 lib]# cp -r /export/server/hadoop/share/hadoop/yarn/*.jar ./lib
[root@sparktest141 lib]# cp -r /export/server/hadoop/share/hadoop/yarn/lib/*.jar ./lib
[root@sparktest141 bin]# cp -r /export/server/zookeeper-3.4.10/*.jar ./lib
[root@sparktest141 bin]# cp -r /export/server/zookeeper-3.4.10/lib/*.jar ./lib
[root@sparktest141 lib]# cp -r /export/server/hadoop/share/hadoop/mapreduce/*.jar ./lib
[root@sparktest141 lib]# cp -r /export/server/hadoop/share/hadoop/mapreduce/lib/*.jar ./lib
6、从节点的配置
执行 vim conf/regionservers
sparktest145
sparktest146
sparktest141
7、拷贝到其他机器
保存之后,配置完毕,将hbase发送至其他数据节点:
[root@sparktest141 server]# scp -r ./hbase root@sparktest145:/export/server/
[root@sparktest141 server]# scp -r ./hbase root@sparktest146:/export/server/
8、网络同步时间
[root@sparktest141 bin]#
[root@sparktest145 bin]#
[root@sparktest146 bin]#
yum install ntpdate
ntpdate cn.pool.ntp.org
9、设置profile
[root@sparktest141 bin]#
[root@sparktest145 bin]#
[root@sparktest146 bin]#
# set hbase path
export PATH=/export/server/hbase/bin:$PATH
cd /export/server/hbase/
[root@sparktest141 hbase]# source/etc/profile
10、启动服务
<1>启动单个主节点
[root@sparktest141 hbase]# bin/hbase-daemon.sh start master
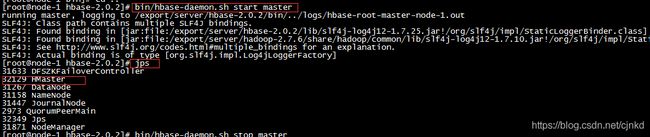
启动成功,在bigdata1会增加进程:HMaster
下面的命令:所有机器上都启动主节点(就算没有配置备用节点,也会启动)
[root@sparktest141 bin]# ./hbase-daemons.sh stop master
<2>启动所有从节点
然后在bigdata2启动regionserver进程,其余4台集群会跟随启动
cd /export/server/hbase/bin
[root@sparktest141 bin]# source /etc/profile
[root@sparktest141 bin]# ./hbase-daemons.sh start regionserver

这里注意跟随启动时,sparktest141到所有机器ssh确保直接进入,如果配置好的免密也最好提前都进一遍,避免需要输入yes而导致错误
同时集群的时间一定同步,否则hbase会启动失败出现NoNode Error的异常
在sparktest141, sparktest145, sparktest146会增加进程:HRegionServer
到这里HBase就部署完毕,并且包含zookeeper集群高可用配置
<3>一次性启动主从节点(备用节点也同时启动)
[root@sparktest141 bin]# ./start-hbase.sh

集群停止,备要节点也会一起停止
./stop-hbase.sh
<4>查看节点是否创建成功
执行命令:./hdfs dfs -ls / 可以查看hbase是否在HDFS文件系统创建成功
看到/hbase节点表示创建成功
[root@sparktest141 sbin]# ./hdfs dfs -ls /

<5>进入Hbase管理界面
然后执行: ./hbase shell 可以进入Hbase管理界面
[root@sparktest141 bin]# pwd
/export/server/hbase/bin
[root@sparktest141 bin]# ./hbase shell

输入 status 查看状态
单个master

多个master

返回状态,表示HBase可以正常使用
输入 quit 可以退出管理,回到命令行
<6>Hbase的Web网页
访问浏览器http://sparktest141:16010可以打开Hbase管理界面
11、hbase新增RegionServer
hbase-daemon.sh start regionserver
启动HRegionServer进程 hbase-daemon.sh start zookeeper
注:
- 新增节点后,会自动平衡数据。
- 新增节点后,必须把该节点加入到文件夹regionservers中,不然下次启动的时候,不会自动启动