自定义控件三部曲之绘图篇(十)——Paint之setXfermode(一)
前言:
不应该一路失望
又一路等待
时间它说
世界还有不同的海
但不要告诉我
现实它很坏
我想看看
自己的能耐
——莫文蔚《境外》
系列文章:
Android自定义控件三部曲文章索引:http://blog.csdn.net/harvic880925/article/details/50995268
一、GPU硬件加速
1、概述
GPU英文全称Graphic Processing Unit,中文翻译为“图形处理器”。与CPU不同,GPU是专门为处理图形任务而产生的芯片。
在GPU出现之前,CPU一直负责着所有的运算工作,CPU的架构是有利于X86指令集的串行架构,CPU从设计思路上适合尽可能快的完成一个任务。但当面对类似多媒体、图形图像处理类型的任务时,就显得力不从心。因为在多媒体计算中通常要求更高的运算密度、多并发线程和频繁地存储器访问;显然当你打游戏时,屏幕上的动画是需要实时刷新的,这些都需要频繁的计算、存取动作;如果CPU不能及时响应,那么屏幕就会显得很卡……你的队友可能会发一句……我等的花都谢了,你咋还不动呢……
为了专门处理多媒体的计算、存储任务,GPU就应运而生了,GPU中自带处理器和存储器,以用来专门计算和存储多媒体任务。
对于Andorid来讲,在API 11之前是没有GPU的概念的,在API 11之后,在程序集中加入了对GPU加速的支持,在API 14之后,硬件加速是默认开启的!我们可以显式地强制图像计算时使用GPU而不使用CPU.
在CPU绘制和GPU绘制时,在流程上是有区别的:
在基于软件的绘制模型下,CPU主导绘图,视图按照两个步骤绘制:
- 让View层次结构失效
- 绘制View层次结构
在基于硬件加速的绘制模式下,GPU主导绘图,绘制按照三个步骤绘制:
- 让View层次结构失效
- 记录、更新显示列表
- 绘制显示列表
可以看到在GPU加速时,流程中多了一项“记录、更新显示列表”,它表示在第一步View层次结构失效后,并不是直接开始逐层绘制,而是首先把这些View的绘制函数作为绘制指令记录一个显示列表中,然后再读取显示列表中的绘制指令调用OpenGL相关函数完成实际绘制。所以在GPU加速时,实际是使用OpenGL的函数来完成绘制的。
所以使用GPU加速的优点显而易见:硬件加速提高了Android系统显示和刷新的速度;
它有缺点也显而易见:
1、 兼容性问题:由于是将绘制函数转换成OpenGL命令来绘制,定然会存在OpenGL并不能完全支持原始绘制函数的问题,所以这就会造成在打开GPU加速时,效果会失效的问题。
2、内存消耗问题:由于需要OpenGL的指令,所以需要把系统中的OpenGL相关的包加载到内存中来,所以单纯OpenGL API调用就会占用8MB,而实际上会占用更多内存;
3、电量消耗问题:多使用了一个部件,当然会更耗电……
下图显示了一些特殊函数硬件加速开始支持的平台等级:(红叉表示任何平台都不支持,不在列表中的默认在API 11就开始支持)
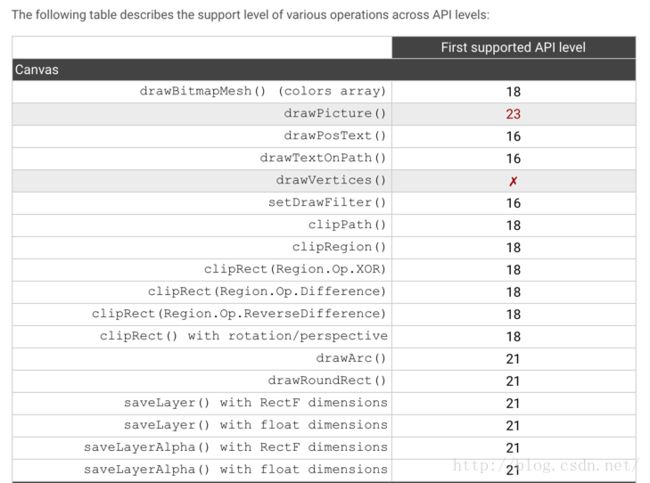


图片摘自《google官方文档:硬件加速》
我再重复一遍,上面我们涉及了两个API等级,在API 11以后,在程序集中加入了对GPU加速的支持,在API 14之后,硬件加速是默认开启的!也就是说在API 11——API 13虽然是支持硬件加速的,但是默认是关闭的。
2、禁用GPU硬件加速方法
那么问题就来了,如果你的APP跑在API 14版本以后,而你洽好要用那些不支持硬件加速的函数要怎么办?
那就只好禁用硬件加速喽,针对不同类型的东东,Android给我们提供了不同的禁用方法:
硬件加速分全局(Application)、Activity、Window、View 四个层级
1.在AndroidManifest.xml文件为application标签添加如下的属性即可为整个应用程序开启/关闭硬件加速:
2.在Activity 标签下使用 hardwareAccelerated 属性开启或关闭硬件加速:
3. 在Window 层级使用如下代码开启硬件加速:(Window层级不支持关闭硬件加速)
getWindow().setFlags(
WindowManager.LayoutParams.FLAG_HARDWARE_ACCELERATED,
WindowManager.LayoutParams.FLAG_HARDWARE_ACCELERATED);4.View 级别如下关闭硬件加速:(view 层级上不支持开启硬件加速)
setLayerType(View.LAYER_TYPE_SOFTWARE, null); 或者使用android:layerType=”software”来关闭硬件加速:比如
二、setXfermode(Xfermode xfermode)之AvoidXfermode
这个函数是图像混合里最难的一个了,它的功能也是相当强大的,这个模式叫做图形混合模式。
与setColorFilter一样,派生自Xfermode的有三个类: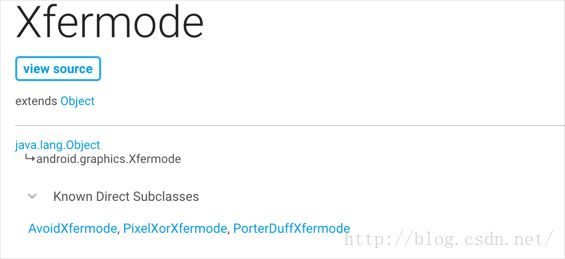
1、概述——基本流程
从上面可以看出,派生自Xfermode的有AvoidXfermode,PixelXorXfermode,PorterDuffXfermode;
从硬件加速不支持的函数列表中,我们可以看到AvoidXfermode,PixelXorXfermode是完全不支持的,而PorterDuffXfermode是部分不支持的。
所以在使用Xfermode时,为了保险起见,我们需要做两件事:
1、禁用硬件加速:
setLayerType(View.LAYER_TYPE_SOFTWARE, null); 2、使用离屏绘制
//新建图层
int layerID = canvas.saveLayer(0,0,width,height,mPaint,Canvas.ALL_SAVE_FLAG);
//TODO 核心绘制代码
//还原图层
canvas.restoreToCount(layerID);有关离屏绘制的原因,这节就先不给大家引申了,后面会单独拉出来两篇文章讲离屏绘制,大家只需要知道,我们需要把绘制的核心代码放在saveLayer()和restoreToCount()之间即可。
下面我们先简单讲解AvoidXfermode的用法,然后写个例子,看下SetXfermode()的使用方法和效果
AvoidXfermode的声明如下:
public AvoidXfermode(int opColor, int tolerance, Mode mode)
当Mode取Mode.TARGET时,它的意义表示将opColor参数所指定的颜色替换成画笔的颜色。
- 第一个参数opColor:一个16进制的AARRGGBB的颜色值;
- 第二个参数tolerance:表示容差,这个概念我们后面再细讲
- 第三个参数mode:取值有两个Mode.TARGET和Mode.AVOID;这里我们先知道Mode.TARGET的意义就可以了,Mode.TARGET表示将指定的颜色替换掉
下面我们还在这个小狗身上做文章,源图片如下:
然后我们把小狗身上白色的地方换成红色
效果图如下:

看下代码实现:
public class MyView extends View {
private Paint mPaint;
private Bitmap mBmp;
public MyView(Context context, AttributeSet attrs) {
super(context, attrs);
mPaint = new Paint();
mBmp = BitmapFactory.decodeResource(getResources(),R.drawable.dog);
setLayerType(View.LAYER_TYPE_SOFTWARE, null);
}
@Override
protected void onDraw(Canvas canvas) {
super.onDraw(canvas);
int width = 500;
int height = width * mBmp.getHeight()/mBmp.getWidth();
mPaint.setColor(Color.RED);
int layerID = canvas.saveLayer(0,0,width,height,mPaint,Canvas.ALL_SAVE_FLAG);
canvas.drawBitmap(mBmp,null,new Rect(0,0,width,height),mPaint);
mPaint.setXfermode(new AvoidXfermode(Color.WHITE,100, AvoidXfermode.Mode.TARGET));
canvas.drawRect(0,0,width,height,mPaint);
canvas.restoreToCount(layerID);
}
}除了禁用硬件加速和离屏绘制,最关键的代码就是在离屏绘制中间的部分:
canvas.drawBitmap(mBmp,null,new Rect(0,0,width,height),mPaint);
mPaint.setXfermode(new AvoidXfermode(Color.WHITE,100, AvoidXfermode.Mode.TARGET));
canvas.drawRect(0,0,width,height,mPaint);这段代码只有三句话,看起来很容易理解的样子,其实不然……下面我们就来看看它是怎么来做的吧。
第一句:画一个小狗的bitmap
canvas.drawBitmap(mBmp,null,new Rect(0,0,width,height),mPaint);所以此时的屏幕应该是这样子的:
第二句:是找选区
mPaint.setXfermode(new AvoidXfermode(Color.WHITE,100, AvoidXfermode.Mode.TARGET));这一点与Photoshop是类似的,就是以白色为目标色,容差为100找到对应的选区;
容差是以颜色差异为基础的,任何两个颜色之间的颜色差异是从0-255的范围内的。具体两个颜色之间的差异的的数值为多少是需要靠公式来计算的:《维基百科:颜色差异》
而容差的概念就是指与目标色所能容忍的最大颜色差异,所以容差越大,所覆盖的颜色区域就越大;所以当容差为0时,就表示只选择与目标色一模一样的颜色区域;当容差为100时,就表示与目标色值的颜色差异在100范围内的都是可以的;而由于最大的颜色差异是255,所以当我们的容差是255时,所有的颜色都将被选中;
我们使用Photoshop来演示下:
在Photoshop中,有个魔棒工具,它有一个容差的参数,默认是0;指的是只与目标色一致的颜色。我们分别看下当容差为100和容差为255的区域选择范围:
从效果图中可以看出,当容差为100时,只选中白色周边的颜色,而当容差为255时,会选中全图;
第三句:将目标图像对应选区的图像更新到原图上
在拿到选区以后,我们又画了一个纯红的与小狗图片一样大的图片:
canvas.drawRect(0,0,width,height,mPaint);这句的意思就是把这个纯红色对应选区的图片截取后,覆盖到原图片上面
下面我们使用Photoshop来演示下这个过程:
最后我们再来对比下我们代码产生的效果图:

看起来差不多,但是使用photoshop选中的区域会更多一点。这是为什么呢?
这是因为android中计算颜色差值的算法与photoshop的不一样。
前面我们讲了颜色差异的最大值是255,所以当容差为255时,选区应该是整个小狗图片;所以做出来的效果应该是红色会把整个图片覆盖,效果图应该是如下的:

使用photoshop来演示这个过程如下:

而使用代码出来的情况却是这样的:

对应的代码如下
protected void onDraw(Canvas canvas) {
super.onDraw(canvas);
int width = 500;
int height = width * mBmp.getHeight()/mBmp.getWidth();
mPaint.setColor(Color.RED);
int layerID = canvas.saveLayer(0,0,width,height,mPaint,Canvas.ALL_SAVE_FLAG);
canvas.drawBitmap(mBmp,null,new Rect(0,0,width,height),mPaint);
mPaint.setXfermode(new AvoidXfermode(Color.WHITE,255, AvoidXfermode.Mode.TARGET));
canvas.drawRect(0,0,width,height,mPaint);
canvas.restoreToCount(layerID);
}明显可以看出,红色并没有完全覆盖整个图片,仍然也只是一部分;这就是Android比较蛋疼的地方,做出来的效果与Photoshop不一致,这就因为android中计算颜色差值的算法与photoshop的不一样,photoshop中当容差为255时表示选中所有颜色,而在android中却不是!所以选区的大小也只能靠猜……至于Android是如何来计算两个颜色之间差异的,我也懒得去找了,在现实使用中的地方比较少,一般会用来用一个图片替换另一个图片中的一部分,比如上面的,我们需要把两张图片溶合
我另外做了一张图片,加了些半透明的小红花,图片背景色设为白色;

然后利用代码将第二张图片替换小狗身上的白色位置:
protected void onDraw(Canvas canvas) {
super.onDraw(canvas);
int width = 500;
int height = width * mBmp.getHeight()/mBmp.getWidth();
mPaint.setColor(Color.RED);
int layerID = canvas.saveLayer(0,0,width,height,mPaint,Canvas.ALL_SAVE_FLAG);
canvas.drawBitmap(mBmp,null,new Rect(0,0,width,height),mPaint);
mPaint.setXfermode(new AvoidXfermode(Color.WHITE,100, AvoidXfermode.Mode.TARGET));
canvas.drawBitmap(BitmapFactory.decodeResource(getResources(),R.drawable.flower_2),null,new Rect(0,0,width,height),mPaint);
canvas.restoreToCount(layerID);
}效果图如下:
就效果图来看,替换效果还是可以的。
2、canvas脏区域更新原理
上面我们讲到“第三句:将目标图像对应选区的图像更新到原图上”时讲到,在拿到选区以后,把第二张图片所对应的选区的图片直接截取后,覆盖到原图片上面
其实,这个“覆盖”是不正确的,其实Android在绘图时会先检查该画笔Paint对象有没有设置Xfermode,如果没有设置Xfermode,那么直接将绘制的图形覆盖Canvas对应位置原有的像素;如果设置了Xfermode,那么会按照Xfermode具体的规则来更新Canvas中对应位置的像素颜色。
所以对于AvoidXfermode而言,这个规则就是先把把目标区域(选区)中的颜色值先清空,然后再把目标颜色给替换上;
我们再来做个示例,我们把Activity的背景色设置为纯蓝色,而我们如果把选区设置为透明色以后,结果会怎样
(1)、先将Activity的背景色设置为纯蓝色
(2)、然后将选区填充为纯透明
public class MyView extends View {
private Paint mPaint;
private Bitmap mBmp;
public MyView(Context context, AttributeSet attrs) {
super(context, attrs);
mPaint = new Paint();
mBmp = BitmapFactory.decodeResource(getResources(),R.drawable.dog);
setLayerType(View.LAYER_TYPE_SOFTWARE, null);
}
@Override
protected void onDraw(Canvas canvas) {
super.onDraw(canvas);
int width = 500;
int height = width * mBmp.getHeight()/mBmp.getWidth();
int layerID = canvas.saveLayer(0,0,width,height,mPaint,Canvas.ALL_SAVE_FLAG);
canvas.drawBitmap(mBmp,null,new Rect(0,0,width,height),mPaint);
mPaint.setXfermode(new AvoidXfermode(Color.WHITE,100, AvoidXfermode.Mode.TARGET));
//将画笔设置为纯透明
mPaint.setARGB(0x00,0xff,0xff,0xff);
canvas.drawRect(0,0,width,height,mPaint);
canvas.restoreToCount(layerID);
}
}
效果图如下:
这段代码不难理解,所以正是由于把选区改为了全透明,所以才露出底部Activity的背景色。
所以这也证明了,我们提到的canvas的脏区域更新原理:
如果没有设置Xfermode,那么直接将绘制的图形覆盖Canvas对应位置原有的像素;如果设置了Xfermode,那么会按照Xfermode具体的规则来更新Canvas中对应位置的像素颜色。
所以对于AvoidXfermode而言,这个规则就是先把把目标区域(选区)中的颜色值先清空,然后再把目标颜色给替换上;
3、AvoidXfermode
在讲解了AvoidXfermode的绘图流程和脏区域更新原理后,这里就开始具体的来看看AvoidXfermode这个函数了;
AvoidXfermode类已经在API 16弃用了,但目前还没有能替代它的方法,所以API 16以上的平台还是支持的。如果大家想在API 16以上使用这个类,唯一需要注意的是它不支持硬件加速,所以记得禁用硬件加速就可以了;
AvoidXfermode的声明如下:
public AvoidXfermode(int opColor, int tolerance, Mode mode)这个声明前面我们已经讲过了:
- 第一个参数opColor:一个16进制的AARRGGBB的颜色值;
- 第二个参数tolerance:表示容差,这个概念我们后面再细讲
- 第三个参数mode:取值有两个Mode.TARGET和Mode.AVOID;Mode.TARGET表示将指定的颜色替换掉,这个我们已经前面演示过了,而Mode.AVOID的意思就是Mode.TARGET所选区域的取反。
下面我们来演示下Mode.AVOID的用法
@Override
protected void onDraw(Canvas canvas) {
super.onDraw(canvas);
int width = 500;
int height = width * mBmp.getHeight()/mBmp.getWidth();
mPaint.setColor(Color.RED);
int layerID = canvas.saveLayer(0,0,width,height,mPaint,Canvas.ALL_SAVE_FLAG);
canvas.drawBitmap(mBmp,null,new Rect(0,0,width,height),mPaint);
mPaint.setXfermode(new AvoidXfermode(Color.WHITE,100, AvoidXfermode.Mode.AVOID));
canvas.drawRect(0,0,width,height,mPaint);
canvas.restoreToCount(layerID);
}效果图如下:
明明我们说了,是选中除了指定选区以后的所有区域;我们知道容差为100的白色选区在小狗的身上,那对这个选区取反,不应该除了小狗的白色,其它都设置为红色吗?
应该是下面这个样子才对啊!

有这个疑问的,应该是对Photoshop比较熟练的同学。在PhotoShop中确实是,对选区取反,是以全图的基准的。
而在Android中确不是!前面我们讲了,Android里计算容差与Photoshop的不同,在Photoshop中容差为255时表示全图选区,而在Android中的选区却不是全图!就是因为在计算颜色差值计算时的差异导致的。
所以在Android中我们得到的反选效果图是这样的:

不过它确实是取反了,因为小狗位置的白色是没有被填充的,通过与上面Mode.TARGET的效果图对比,可以明显看出区别。
正是由于在颜色差值计算时的差异,所以做出来的效果与Photoshop不一致,所以选区的大小也只能靠猜……这点是相当蛋疼
源码在文章底部给出
三、setXfermode(Xfermode xfermode)之PixelXorXfermode
与AvoidXfermode一样也在API 16过时了,它是一个简单的异或运算(op ^ src ^ dst),返回的alpha值始终等于255,所以对操作颜色混合不是特别的有效;
这个类的用法难度不大,而且基本上用不到,这里就不再细讲了,大家有兴趣的话,可以尝试一下。
四、setXfermode(Xfermode xfermode)之PorterDuffXfermode
1、概述
PorterDuffXfermode的构造函数如下:
public PorterDuffXfermode(PorterDuff.Mode mode)它只有一个参数PorterDuff.Mode,对于PorterDuff.Mode大家应该比较熟悉,我们在讲解setColorFilter时已经用过它:
mPaint.setColorFilter(new PorterDuffColorFilter(Color.RED, PorterDuff.Mode.OVERLAY));前面我们讲过PorterDuff.Mode表示混合模式,枚举值有18个,表示各种图形混合模式,有:
Mode.CLEAR
Mode.SRC
Mode.DST
Mode.SRC_OVER
Mode.DST_OVER
Mode.SRC_IN
Mode.DST_IN
Mode.SRC_OUT
Mode.DST_OUT
Mode.SRC_ATOP
Mode.DST_ATOP
Mode.XOR
Mode.DARKEN
Mode.LIGHTEN
Mode.MULTIPLY
Mode.SCREEN
Mode.OVERLAY
Mode.ADD上面每一个模式都对应着一个算法: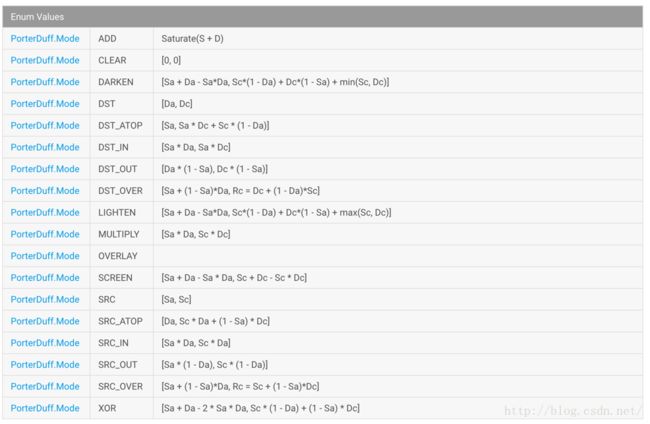
摘自《google:PorterDuff.Mode》
比如LIGHTEN的计算方式为[Sa + Da - Sa*Da, Sc*(1 - Da) + Dc*(1 - Sa) + max(Sc, Dc)],其中Sa全称为Source alpha表示源图的Alpha通道;Sc全称为Source color表示源图的颜色;Da全称为Destination alpha表示目标图的Alpha通道;Dc全称为Destination color表示目标图的颜色,在每个公式中,都会被分为两部分[……,……],其中“,”前的部分为“Sa + Da - Sa*Da”这一部分的值代表计算后的Alpha通道而“,”后的部分为“Sc*(1 - Da) + Dc*(1 - Sa) + max(Sc, Dc)”这一部分的值代表计算后的颜色值,图形混合后的图片就是依据这个公式来对DST和SRC两张图像中每一个像素进行计算,得到最终的结果的。
Google给我们了一张图,显示的是两个图形一圆一方通过一定的计算产生不同的组合效果,其中圆形是底部的目标图像,方形是上方的源图像。

在上面的公式中涉及到一个概念,目标图DST,源图SRC。那什么是源图,什么是目标图呢?我们简单举例子来说明一下:
public class MyView extends View {
private int width = 400;
private int height = 400;
private Bitmap dstBmp;
private Bitmap srcBmp;
private Paint mPaint;
public MyView(Context context, AttributeSet attrs) {
super(context, attrs);
dstBmp = makeDst(width,height);
srcBmp = makeSrc(width,height);
mPaint = new Paint();
}
@Override
protected void onDraw(Canvas canvas) {
super.onDraw(canvas);
int layerID = canvas.saveLayer(0,0,width*2,height*2,mPaint,Canvas.ALL_SAVE_FLAG);
canvas.drawBitmap(dstBmp, 0, 0, mPaint);
mPaint.setXfermode(new PorterDuffXfermode(PorterDuff.Mode.SRC_IN));
canvas.drawBitmap(srcBmp, width/2, height/2, mPaint);
mPaint.setXfermode(null);
canvas.restoreToCount(layerID);
}
static Bitmap makeDst(int w, int h) {
Bitmap bm = Bitmap.createBitmap(w, h, Bitmap.Config.ARGB_8888);
Canvas c = new Canvas(bm);
Paint p = new Paint(Paint.ANTI_ALIAS_FLAG);
p.setColor(0xFFFFCC44);
c.drawOval(new RectF(0, 0, w, h), p);
return bm;
}
static Bitmap makeSrc(int w, int h) {
Bitmap bm = Bitmap.createBitmap(w, h, Bitmap.Config.ARGB_8888);
Canvas c = new Canvas(bm);
Paint p = new Paint(Paint.ANTI_ALIAS_FLAG);
p.setColor(0xFF66AAFF);
c.drawRect(0, 0,w,h, p);
return bm;
}
}效果图如下: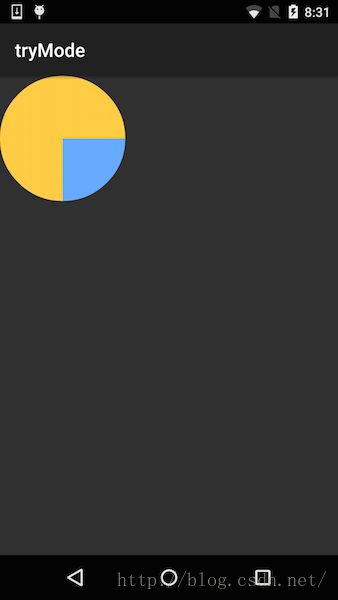
首先是新建一个目标bitmap图像:
static Bitmap makeDst(int w, int h) {
Bitmap bm = Bitmap.createBitmap(w, h, Bitmap.Config.ARGB_8888);
Canvas c = new Canvas(bm);
Paint p = new Paint(Paint.ANTI_ALIAS_FLAG);
p.setColor(0xFFFFCC44);
c.drawOval(new RectF(0, 0, w, h), p);
return bm;
}首先,新建一个空白的bitmap:
Bitmap bm = Bitmap.createBitmap(w, h, Bitmap.Config.ARGB_8888);这个空白bitmap上每个像素的值都是0x00000000;即全透明
然后在bitmap上绘图:
Paint p = new Paint(Paint.ANTI_ALIAS_FLAG);
p.setColor(0xFFFFCC44);
c.drawOval(new RectF(0, 0, w, h), p);在这个bitmap上画一个圆;
然后新建一个源图像
static Bitmap makeSrc(int w, int h) {
Bitmap bm = Bitmap.createBitmap(w, h, Bitmap.Config.ARGB_8888);
Canvas c = new Canvas(bm);
Paint p = new Paint(Paint.ANTI_ALIAS_FLAG);
p.setColor(0xFF66AAFF);
c.drawRect(0, 0,w,h, p);
return bm;
}与上面目标图像bitmap的原理一样,还是新建一个空白bitmap,然后再在这个bitmap上画一个矩形;
然后看最关键的绘图部分:
protected void onDraw(Canvas canvas) {
super.onDraw(canvas);
int layerID = canvas.saveLayer(0,0,width*2,height*2,mPaint,Canvas.ALL_SAVE_FLAG);
canvas.drawBitmap(dstBmp, 0, 0, mPaint);
mPaint.setXfermode(new PorterDuffXfermode(PorterDuff.Mode.SRC_IN));
canvas.drawBitmap(srcBmp, width/2, height/2, mPaint);
mPaint.setXfermode(null);
canvas.restoreToCount(layerID);
}在离屏绘制的saveLayer()和restoreToCount()函数之间的代码才是核心:
canvas.drawBitmap(dstBmp, 0, 0, mPaint);
mPaint.setXfermode(new PorterDuffXfermode(PorterDuff.Mode.SRC_IN));
canvas.drawBitmap(srcBmp, width/2, height/2, mPaint);先画目标图像:圆形bitmap
canvas.drawBitmap(dstBmp, 0, 0, mPaint);然后设置图像混合模式:
mPaint.setXfermode(new PorterDuffXfermode(PorterDuff.Mode.SRC_IN));最后在源图像上生成结果图并更新到目标图像上
canvas.drawBitmap(srcBmp, width/2, height/2, mPaint);这句话虽然只有一句,但它的信息量却是非常大的。
它会在源图像所在区域与目标图像运算,在得到结果以后,将结果覆盖到目标图像上。整个过程如下:
首先在两个矩形的所在位置:
然后是源图像计算结果的覆盖过程:
其中蓝色小块是源图像所在区域与目标图像经过运算的结果(有关这个结果为什么是一小块蓝色,下篇会具体讲),在得到结果以后,把结果对应区域的图像先清空,然后把结果覆盖上去。(还记得我们在讲解canvas脏数据更新的时候提到,如果没有xfermode就直接覆盖上去,如果有xfermode则先清空对应的区域,然后再覆盖上去);
这里还需要强调一点,源图像在运算时,只是在源图像所在区域与对应区域的目标图像做运算。所以目标图像与源图像不相交的地方是不会参与运算的!这一点非常重要!不相交的地方不会参与运算,所以不相交的地方的图像也不会是脏数据,也不会被更新,所以不相交地方的图像也永远显示的是目标图像。
2、Google的误导
大家仔细看我们示例代码的结果,同样是SRC_IN模式,为什么我们的结果与google的图像不一样呢?
google给出的SRC_IN的结果是这样的

而我们的运算结果确是这样的:

在Android\sdk\samples\android-XX\legacy\ApiDemos\src\com\example\android\apis\graphics\Xfermodes.java中可以找到google所给图像的源码:(我仿照上面的示例,对源码进行更改,只演示SRC_IN的合成样式,具体源码大家可以从上面路径查找)
public class Xfermodes extends View {
// create a bitmap with a circle, used for the "dst" image
static Bitmap makeDst(int w, int h) {
Bitmap bm = Bitmap.createBitmap(w, h, Bitmap.Config.ARGB_8888);
Canvas c = new Canvas(bm);
Paint p = new Paint(Paint.ANTI_ALIAS_FLAG);
p.setColor(0xFFFFCC44);
c.drawOval(new RectF(0, 0, w*3/4, h*3/4), p);
return bm;
}
// create a bitmap with a rect, used for the "src" image
static Bitmap makeSrc(int w, int h) {
Bitmap bm = Bitmap.createBitmap(w, h, Bitmap.Config.ARGB_8888);
Canvas c = new Canvas(bm);
Paint p = new Paint(Paint.ANTI_ALIAS_FLAG);
p.setColor(0xFF66AAFF);
c.drawRect(w/3, h/3, w*19/20, h*19/20, p);
return bm;
}
private int width = 400;
private int height = 400;
private Bitmap dstBmp;
private Bitmap srcBmp;
private Paint mPaint;
public Xfermodes(Context context,AttributeSet attrs) {
super(context,attrs);
srcBmp = makeSrc(width, height);
dstBmp = makeDst(width, height);
mPaint = new Paint();
}
@Override
protected void onDraw(Canvas canvas) {
canvas.drawColor(Color.WHITE);
int layerID = canvas.saveLayer(0,0,width*2,height*2,mPaint,Canvas.ALL_SAVE_FLAG);
canvas.drawBitmap(dstBmp, 0, 0, mPaint);
mPaint.setXfermode(new PorterDuffXfermode(PorterDuff.Mode.SRC_IN));
canvas.drawBitmap(srcBmp, 0, 0, mPaint);
mPaint.setXfermode(null);
canvas.restoreToCount(layerID);
}
}效果图如下:
我们从代码中分析下,google是如何来得到这个图像的。
看源码中,他也是通过makeDst(int w, int h)和makeSrc(int w, int h)生成两个bitmap,一圆一方,但仔细看他的代码,就会发现问题
先看makeDst(int w, int h)
static Bitmap makeDst(int w, int h) {
Bitmap bm = Bitmap.createBitmap(w, h, Bitmap.Config.ARGB_8888);
Canvas c = new Canvas(bm);
Paint p = new Paint(Paint.ANTI_ALIAS_FLAG);
p.setColor(0xFFFFCC44);
c.drawOval(new RectF(0, 0, w*3/4, h*3/4), p);
return bm;
}这段函数是用来生成圆形的目标图像的,它首先生成一个宽度为w,高度为h的空白图像:
Bitmap bm = Bitmap.createBitmap(w, h, Bitmap.Config.ARGB_8888);然后在这个空白图像上画圆形:
c.drawOval(new RectF(0, 0, w*3/4, h*3/4), p);现在问题来了,它这里bitmap的宽和高是w和h,但画的圆形的大小却是new RectF(0, 0, w*3/4, h*3/4)!并没有完全填满bitmap,画出来的效果图是这样的: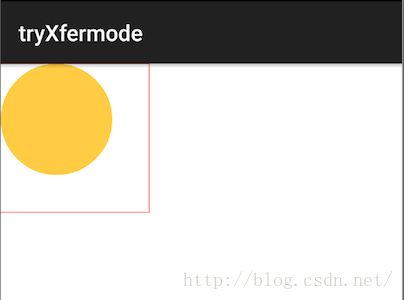
其中红色矩形区域是整个bitmap的大小。
然后再看makeSrc(int w, int h)
static Bitmap makeSrc(int w, int h) {
Bitmap bm = Bitmap.createBitmap(w, h, Bitmap.Config.ARGB_8888);
Canvas c = new Canvas(bm);
Paint p = new Paint(Paint.ANTI_ALIAS_FLAG);
p.setColor(0xFF66AAFF);
c.drawRect(w/3, h/3, w*19/20, h*19/20, p);
return bm;
}
这里同样是新建一个宽度为w和高度为h的空白图像:
Bitmap bm = Bitmap.createBitmap(w, h, Bitmap.Config.ARGB_8888);然后再在这个空白bitmap上画一个矩形:
c.drawRect(w/3, h/3, w*19/20, h*19/20, p);大家注意到了没,它同样是比空白bitmap小的,它竟然是从(w/3, h/3)开始画,right和bottom的坐标在( w*19/20, h*19/20)!这个比bitmap小太多了,我们来看下它的图像
同样,红色框表示bitmap的位置。从中可以看到明显矩形框只占整个bitmap的其中小部分
最后我们来看看是如何将这两个bitmap绘出来的
protected void onDraw(Canvas canvas) {
canvas.drawColor(Color.WHITE);
int layerID = canvas.saveLayer(0,0,width*2,height*2,mPaint,Canvas.ALL_SAVE_FLAG);
canvas.drawBitmap(dstBmp, 0, 0, mPaint);
mPaint.setXfermode(new PorterDuffXfermode(PorterDuff.Mode.SRC_IN));
canvas.drawBitmap(srcBmp, 0, 0, mPaint);
mPaint.setXfermode(null);
canvas.restoreToCount(layerID);
}最最关键的是看这里:
canvas.drawBitmap(dstBmp, 0, 0, mPaint);
mPaint.setXfermode(new PorterDuffXfermode(PorterDuff.Mode.SRC_IN));
canvas.drawBitmap(srcBmp, 0, 0, mPaint);注意,这两个bitmap的大小都是width和height,而且都是从(0,0)位置开始绘制的!!!!这说明这两个bitmap是完全重合的!!!!
所以它的合成过程是这样的:
即两个同样大小的bitmap合并。正是由于这两个bitmap所在位置和大小是完全一样的,所以在以源图像所在区域与目标图像做计算时,是将两个图像完全重合计算的,而不是像我们前面示例中那样,只有一部分相交区域。所以google这么做是对开发者的误导,利用两个完全不同的完全相同大小的图片,只在其中一部分画矩形和圆形,但在做计算时却是以整个bitmap大小来做计算的,这显然是不正确的。
最后,仿照示例代码,在(0,0,width,height)画一个圆形,然后在(width/2,height/2,3*width/2,3*height/2)的位置画一个矩形,然后应用各个Mode样式结果如下:
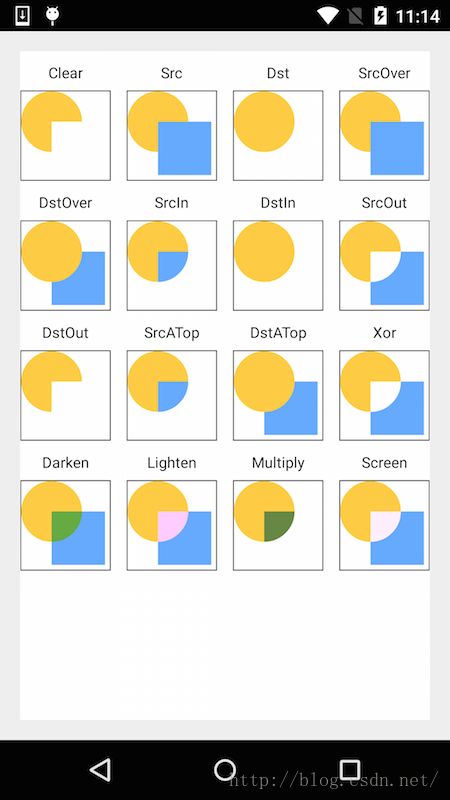
这个才是正确的合成结果,google给出的是错误的!
这部分理解起来比较困难,我会把对应的代码分别给出,大家多对照下区别就可以理解了。
下篇将分别给大家讲解各个Mode的原理及应用。
源码内容
1、示例代码
2、google示例代码(只演示src_in)
3、google改进代码
如果本文有帮到你,记得加关注哦
源码下载地址:http://download.csdn.net/detail/harvic880925/9505910
请大家尊重原创者版权,转载请标明出处:http://blog.csdn.net/harvic880925/article/details/51264653 谢谢
如果你喜欢我的文章,你可能更喜欢我的公众号
