ClickHouse安装及数据结构
ClickHouse安装及结构说明
一、ClickHouse安装方式
- 源码编译安装
- Docker安装
- RPM包安装
为了方便使用,一般采用RPM包方式安装,其他两种方式这里不做说明。
二、下载安装包
官方没有提供rpm包,但是Altinity第三方公司提供了。
地址:https://packagecloud.io/altinity/clickhouse
三、配置文件
安装好rmp包后,默认配置文件在/etc/clickhouse-server/目录下,主要涉及以下3种配置文件,也可以自定义配置文件位置,如果修改了目录记得连带修改启动脚本。
- 默认启动脚本,注意,这个名字虽然叫server,其实是个shell脚本
vi /etc/init.d/clickhouse-server
12 CLICKHOUSE_USER=clickhouse
13 CLICKHOUSE_GROUP=${CLICKHOUSE_USER}
14 SHELL=/bin/bash
15 PROGRAM=clickhouse-server
16 GENERIC_PROGRAM=clickhouse
17 EXTRACT_FROM_CONFIG=${GENERIC_PROGRAM}-extract-from-config
18 SYSCONFDIR=/data/clickhouse
19 CLICKHOUSE_LOGDIR=/data/clickhouse/logs
20 CLICKHOUSE_LOGDIR_USER=root
21 CLICKHOUSE_DATADIR_OLD=/data/clickhouse
22 LOCALSTATEDIR=/data/clickhouse/lock
23 BINDIR=/usr/bin
24 CLICKHOUSE_CRONFILE=/etc/cron.d/clickhouse-server
25 CLICKHOUSE_CONFIG=$SYSCONFDIR/config.xml
26 LOCKFILE=$LOCALSTATEDIR/$PROGRAM
27 RETVAL=0
29 CLICKHOUSE_PIDDIR=/var/run/$PROGRAM
30 CLICKHOUSE_PIDFILE="$CLICKHOUSE_PIDDIR/$PROGRAM
config.xml 全局信息配置文件
query_log
users.xml 用户信息配置文件
metrika.xml 集群信息配置文件
四、ClickHouse常用架构
- 单实例
无需过多解释,就是单机部署,安装好rpm包后,简单修改配置文件即可启动;
单实例不建议线上使用,只做功能测试;
MergeTree,引擎适用于单机实例,查询性能非常高。
- 分布式+高可用集群
ClickHouse引擎有十几个,不同引擎实现不同功能,实现分布式高可用主要通过以下两种引擎:
ClickHouse分布式通过配置文件来实现,同一集群配置多个分片,每个节点,都配置同样的配置文件;而高可用需要借助zookeeper来实现,ReplicatedMergeTree里共享同一个ZK路径的表,会相互同步数据。
ReplicatedMergeTree,复制引擎,基于MergeTree,实现数据复制,即高可用;
Distributed,分布式引擎,本身不存储数据,将数据分发汇总。
五、分布式高可用集群架构
以下是2个分片、2个副本集的架构,zookeeper机器可以跟ClickHouse共用,但是如果压力较大,IO消耗较多,可能会延迟,建议分开。
| role |
shard1 |
shard2 |
| replica |
192.168.1.1 |
192.168.1.3 |
| replica |
192.168.1.2 |
192.168.1.4 |
zookeeper集群:
| index |
node |
| 1 |
192.168.1.5 |
| 2 |
192.168.1.6 |
| 3 |
192.168.1.7 |
六、安装zookeeper集群,至少3台
1、下载安装包,建议3.4.9之后的版本
http://archive.apache.org/dist/zookeeper/
2、解压
tar zxf /usr/local/test/clickhouse/zookeeper-3.4.13.tar.gz -C /usr/local
mv /usr/local/zookeeper-3.4.13 /usr/local/zookeeper
3、创建目录:
mkdir /data/zookeeper/data
mkdir /data/zookeeper/logs
4、指定节点号
echo '1' > /data/zookeeper/data/myid
5、zookeeper配置文件
/usr/local/zookeeper/conf/zoo.cfg
| tickTime=2000 |
基本时间单位, 毫秒值 |
| initLimit=30000 |
tickTime的倍数,follower和leader之间的最长心跳时间 |
| syncLimit=10 |
tickTime的倍数,leader和follower之间发送消息, 请求和应答的最大时间 |
| dataDir=/export/data/zookeeper/data |
数据目录 |
| dataLogDir=/export/data/zookeeper/logs |
日志目录,如果没设定,默认和dataDir相同 |
| clientPort=2181 |
监听client连接的端口号 |
| maxClientCnxns=2000 |
zookeeper最大连接 |
| maxSessionTimeout=60000000 |
最大的会话超时时间 |
| autopurge.snapRetainCount=10 |
保留的文件数目,默认3个 |
| autopurge.purgeInterval=1 |
自动清理snapshot和事务日志,清理频率,单位是小时 |
| globalOutstandingLimit=200 |
等待处理的最大请求数量 |
| preAllocSize=131072 |
日志文件大小Kb,切换快照生成日志 |
| snapCount=3000000 |
两次事务快照之间可执行事务的次数,默认的配置值为100000 |
| leaderServes=yes |
leader是否接受client请求,默认为yes即leader可以接受client的连接,当节点数为>3时,建议关闭 |
| server.1=192.168.1.5:2888:3888 |
2888 leader\follower传输信息端口,3888推举端口 |
| server.2=192.168.1.6:2888:3888 |
2888 leader\follower传输信息端口,3888推举端口 |
| server.3=192.168.1.7:2888:3888 |
2888 leader\follower传输信息端口,3888推举端口 |
6、启动
/usr/local/zookeeper/bin/zkServer.sh [start\status\stop]
七、安装clickhouse
1、下载并安装上面rpm安装包
2、参考配置上面的配置文件
如果采用上面的配置文件需要创建目录
3、mkdir -p /data/clickhouse/tmp /data/clickhouse/logs /data/clickhouse/lock/
4、修改权限
chown clickhouse.clickhouse -R /data/clickhouse
5、启动(有两种方式)
/etc/init.d/clickhouse-serve start
或
clickhouse-server --daemon --config-file=/etc/clickhouse-server/config.xml
6、登录验证
clickhouse-client -u default --password password -h127.0.0.1
7、目录结构
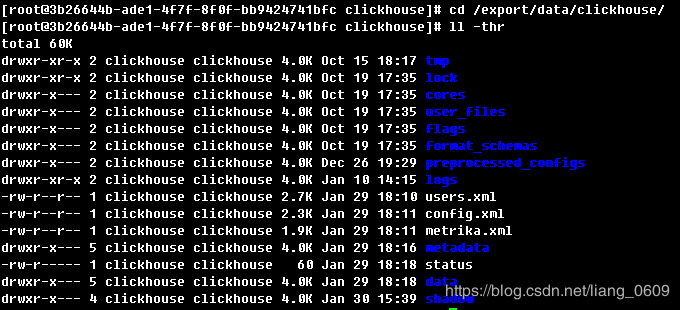
Metadata:元数据目录,.sql文件
Data:数据目录
Logs:日志目录,错误日志再次目录下
其他目录暂时无需了解
8、数据文件
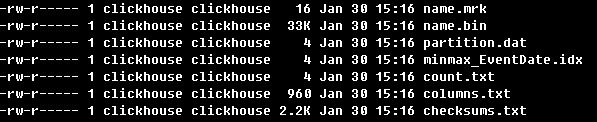
在items表的每一个part子目录中,存放如下文件下面这些文件:
columns.txt:记录列信息
count.txt:记录总数
checksums.txt:数据校验
.bin:每列都有,存储实际数据
.mrk文件:bin数据文件中,索引粒度偏移量(index_granularity (usually, N = 8192)
minmax_EventDate.idx:时间字段索引
primary.idx:存储主键信息,存储在内存中
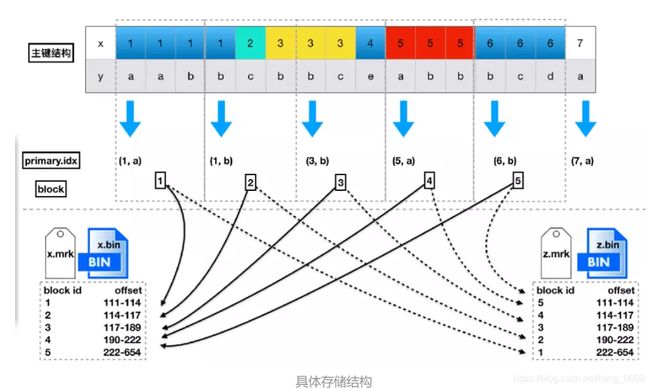
这里展示了mrk文件和primary文件的具体结构,可以看到,数据是按照主键排序的,并且会每隔一定大小分隔出很多个block。每个block中也会抽出一个数据作为索引,放到primary.idx和各列的mrk文件中。
而利用mergetree进行查询时,最关键的步骤就是定位block,这里会根据查询的列是否在主键内有不同的方式。根据主键查询时性能会较好,但是非主键查询时,由于按列存储的关系,虽然会做一次全扫描,性能也没有那么差。所以索引在clickhouse里并不像mysql那么关键。实际使用时一般需要添加按日期的查询条件,保障非主键查询时的性能。
找到对应的block之后,就是在block内查找数据,获取需要的行,再拼装需要的其他列数据。