hadoop中关于shuffle机制的源码分析
今天我们来分析一些MR中shuffle阶段的流程源码分析
shuffle阶段处于mapper之后reducer之前,是在mapTask的后半部分和reduceTask的前半部分
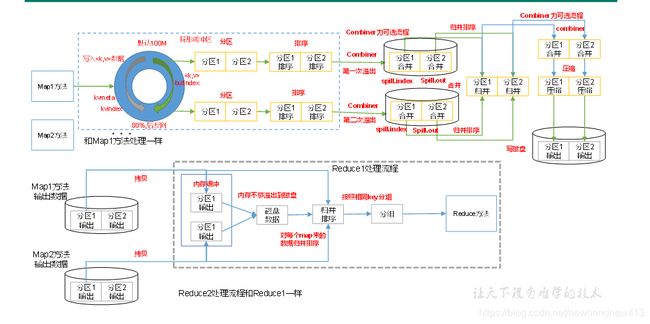
一、MapTask中的shuffle阶段
Mapper中调用context.write()方法后
mapper的write方法一直进入到MapTask类中的write方法,然后

默认分区方法是HashPartitioner类中的方法
public int getPartition(K key, V value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
MapTask类中有个内部类
MapOutputBuffer<K extends Object, V extends Object>
implements MapOutputCollector<K, V>, IndexedSortable
其中创建collector时调用init方法,就是调用的MapOutputBuffer的init初始化方法来初始化一些内容,包括环形缓冲区,默认大小为100M,softLimit为80M
collect方法中会对输入的key和value以及分区数量进行校验,然后对缓冲区中剩余的大小进行判断
bufferRemaining = softLimit;
private static final int NMETA = 4; // num meta ints
private static final int METASIZE = NMETA * 4; // size in bytes
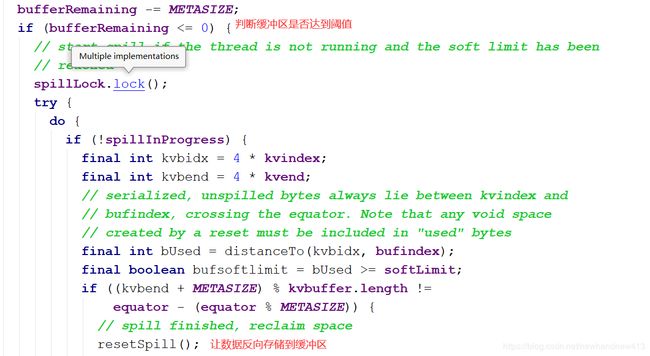
startSpill();然后进行溢写操作
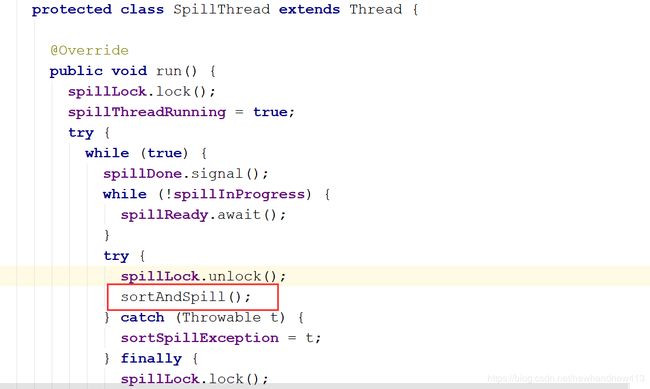
会有一个spillThread线程对其进行监视,一有响应就被唤醒,并进行一次sortAndSpill()

不满足进行下列操作,先将key、value序列化操作,然后是将kv数据和元数据写入到缓冲区中(具体操作详见源码)
Mapper类中run方法
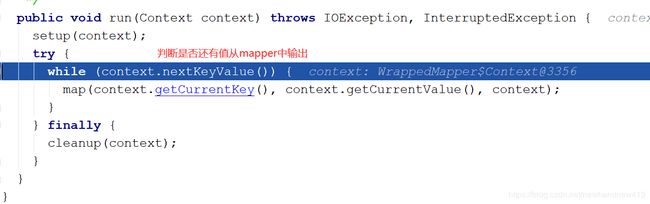
一直重复到mapper中没有值
最后进入到MapOutputBuffer中的runNewMapper方法中,此时要对input和output流进行关闭,


flush()方法中对剩余数据进行处理
resetSpill();
sortAndSpill();
sorter.sort(MapOutputBuffer.this, mstart, mend, reporter);
mergeParts();对溢写的相同分区的文件进行归并排序合成一个文件
二、ReduceTask中的shuffle阶段
主要是 copy -> merge -> sort
(1)Copy阶段:每个ReduceTask都会远程拷贝每个MapTask生成的文件中的对应区的数据,并针对某一片数据,如果其大小超过一定阈值,则写到磁盘上,否则直接放到内存中。
(2)Merge阶段:在远程拷贝数据的同时,ReduceTask启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或磁盘上文件过多。
Merge有3种形式,分别是内存到内存,内存到磁盘,磁盘到磁盘。默认情况下第一种形式不启用,第二种Merge方式一直在运行(spill阶段)直到结束,然后启用第三种磁盘到磁盘的Merge方式生成最终的文件。
(3)Sort阶段:按照MapReduce语义,用户编写reduce()函数输入数据是按key进行聚集的一组数据。为了将key相同的数据聚在一起,Hadoop采用了基于排序的策略。由于各个MapTask已经实现对自己的处理结果进行了局部排序,因此,ReduceTask只需对所有数据进行一次归并排序即可。