hbase split操作
转载来自:https://zhuanlan.zhihu.com/p/39648692
HBase - 解析split操作
split操作:意义
HBase数据写入首先会写入缓存,缓存写满会执行一次flush操作,每次flush都会生成一个HFile文件。随着HFile的增多,文件的读取效率势必会降低,HBase采用compact机制不断的对这些文件进行合并,将小文件合并成大文件。然而,对HBase而言,大文件也不是什么好事,原因如下:
1. 数据分布不均匀。同一 region server 上数据文件越来越大,读请求也会越来越多。一旦所有的请求都落在同一个 region server 上,尤其是很多热点数据,必然会导致很严重的性能问题。
2. compaction性能损耗严重。compaction本质上是一个排序合并的操作,合并操作需要占用大量内存,因此文件越大,占用内存越多。另一方面,compaction有可能需要迁移远程数据到本地进行处理(balance之后的compaction就会存在这样的场景),如果需要迁移的数据是大文件的话,带宽资源就会损耗严重。
3. 太大文件读取效率也会受到影响。
另外,HBase的数据写入量也是很惊人的,每天都可能有上亿条的数据写入,因此不做切分的话一个热点region的新增数据量就有可能几十G,用不了多长时间大量读请求就会把单台region server的资源耗光。只有通过切分,一个region变为两个近似相同大小的子region,再通过balance机制均衡到不同 region server上,才能使系统资源使用更加均衡。
split操作:触发条件
通过上面讨论可知,切分操作对于HBase集群的资源均衡至关重要。那集群到底在哪些场景下会执行切分操作呢?这个问题网上有很多答案,但是都很散乱,这里有必要总结一下,见下图:
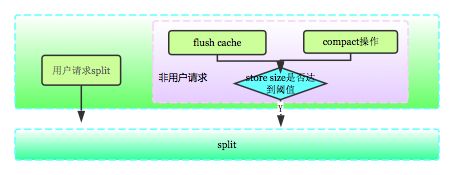
上图中左侧是用户请求split,无论什么情况都可以执行切分。右侧是系统请求split,一般在两种场景下出现:
1. HBase中写请求会先写入memstore,region server 会为每个 region 分配一个默认大小为 128M(可通过hbase.hregion.memstore.flush.size参数配置) 的 memstore,当memstore写满之后,会启动flush刷新到磁盘。flush完成之后会判断是否需要进行切分操作。
2. 系统在很多场景下执行压缩操作(compaction操作),将多个小文件合并成一个大文件。执行完成之后也会判断是否需要进行切分操作。
这两类操作之后都会针对相应region生成一个requestSplit请求,requestSplit首先会执行checkSplit,检测store size是否达到阈值(具体算法见下面分析),如果超过阈值,就进行切分。
检查阈值的算法主要有两种:ConstantSizeRegionSplitPolicy和
IncreasingToUpperBoundRegionSplitPolicy 。 0.94版本中前者是默认算法,0.98版本后者是默认算法,具体含义分别如下:
ConstantSizeRegionSplitPolicy : 系统会遍历region所有store的文件大小,如果有文件大小 > hbase.hregion.max.filesize,就会触发切分操作。
IncreasingToUpperBoundRegionSplitPolicy:0.98版本 的默认策略则是store大小大于一个变化的阀值就允许split。举个例子,当hbase相关split的属性都没有配置,采用默认,一张表刚建立,默认情况只有1个region,那么逻辑上是当这个region的store大小超过 1 * 1 * 1 * flushsize * 2 = 128M * 2 =256M 时,才会允许split,如果达到这个值切分后,会有两个region,其中一个region中的某个store大小大于 2 * 2 * 2 * flushsize * 2 = 2048M 时,则允许split,如此计算下去,直到这个大小超过了hbase.hregion.max.filesize + hbase.hregion.max.filesize *随机小数 * hbase.hregion.max.filesize.jitter才允许split,基本也就固定了,如果粗劣的计算可以把这个hbase.hregion.max.filesize的大小作为最后的阀值,默认是10G,也就说当这个阀值变化到10G,这个阀值就基本上不再变化。
这种思想使得阀值达到一个基本固定的值之前先做了几次split,而这几次split的数据量很少,对HBase的影响也没有那么大,而且相当于数据导入量不大的时候就做了一次“预分region”,在一定意义上减少了以后的热点region的发生。
split操作:执行流程
1. 将一个region切分为两个近似大小的子region,首先要确定切分点。切分操作是基于region执行的,每个region有多个store(对应多个column famliy)。系统首先会遍历所有store,找到其中最大的一个,再在这个store中找出最大的HFile,定位这个文件中心位置对应的rowkey,作为region的切分点。
2. 找到切分点之后,切分线程会初始化一个SplitTransaction对象,从字面上就可以看出来split流程是一个类似‘事务’的过程,之所以称为类似’事务’,因为它不满足事务的很多特性,比如隔离性。但它却尝试使用写journal的方式实现数据的原子性和一致性。整个过程分为三个阶段:prepare - execute - (rollback) ,操作模版如下:

1)prepare阶段:在内存中初始化两个子region,具体是生成两个HRegionInfo对象,包含tableName、regionName、startkey、endkey等。同时会生成一个transaction journal,这个对象用来记录切分的进展,具体见rollback阶段。
2)execute阶段:切分的核心操作。见下图(来自
Hortonworks):

- region server 更改ZK节点 /region-in-transition 中该region的状态为SPLITING。
- master检测到region状态改变。
- region在存储目录下新建临时文件夹.split保存split后的daughter region信息。
- parent region关闭数据写入并触发flush操作,将写入region的数据全部持久化到磁盘。
- 在.split文件夹下新建两个子文件夹,称之为daughter A、daughter B,并在文件夹中生成引用文件,分别指向父region中对应文件。
- 将daughter A、daughter B拷贝到HBase根目录下,形成两个新的region。
- parent region通知修改 hbase.meta 表后下线,不再提供服务。
- 开启daughter A、daughter B两个子region。
- 通知修改 hbase.meta 表,正式对外提供服务。
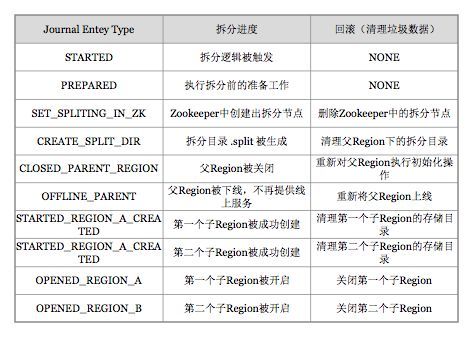
3)rollback阶段:如果execute阶段出现异常,则执行rollback操作。为了实现回滚,整个切分过程被分为很多子阶段,回滚程序会根据当前进展到哪个子阶段清理对应的垃圾数据。代码中使用 JournalEntryType 来表征各个子阶段,具体见下图:
split操作:流程疑点
1. 为什么Reference文件先在.split临时文件夹下生成之后再移到子region数据目录,而不是直接就生成在子region数据目录?
类似于prepare-commit机制,prepare阶段处理一些相对比较重的操作(生成reference文件),如果出错只需要将临时文件清除即可。commit阶段只需要处理轻量级操作,move操作相对比较轻,不易出错。试想,如果直接在子region数据目录生成reference文件,一旦出错,不容易处理垃圾文件数据。
2. split之后是否会马上触发major compact操作?
会,切分操作会在子region打开的时候针对每个store异步执行一次major compaction。这次compaction会将父region的文件重写到对应的两个子region。
3. split之后是否会显式调用系统负载均衡函数?
不会。balance操作是系统定时执行的,系统每隔一段时间就会检查集群负载是否不均衡(集群平均负载 > (1 + slop) * maxLoad 或者 集群平均负载 < (1 - slop) * minLoad)),如果不均衡,才会执行balance操作。
split操作:影响
1. 因为split操作实际上并没有进行store file的物理拆分,而只是逻辑拆分,所以可以在秒级完成。
2. 在上述操作流程中,父region关闭而子region未开启,此时客户端请求会
抛出NotServingRegionException,客户端对此场景应当采用尝试机制。
3. split操作之后会进行一次major compaction操作,将原region中的数据文件重写到新region的storefile中,合并重写完成会自动用新生成的storefile替换原来的引用文件,这个过程会消耗大量的磁盘IO资源。
split操作:最佳实践
1. 对于预估数据量较大的表,需要在创建表的时候根据rowkey执行 region 的预分配。通过region预分配,数据会被均衡到多台机器上,这样可以一定程度解决热点应用数据量剧增导致的性能问题。
2. 建议关闭线上自动split操作。
这一方面可以避免’拆分合并风暴’,当用户的 region 大小以恒定的速度保持增长时,或者在某些巧合的场景下,大量 region 可能会在同一时间发生split,因为这个过程会重写拆分之后的 region ,这将引起磁盘IO上升。手动拆分可以控制执行时间,在不同的region上交互执行,这样可以尽可能分散IO压力,避免风暴。
另一方面,手动拆分可以控制哪些 region 可用。试想,某天运维人员碰到一个问题想对问题现场进行跟踪,转眼没看,发现 region 已经被拆分了,现场被毁了,那种感觉岂不是很不好。手动拆分就可以避免这种奇葩场景。
实践方法:可以将配置文件中‘hbase.hregion.max.filesize’设置为一个较大的值(比如200G), 这样系统就不会触发自动split操作。