HBase
HBase
- 一 .概述
- 1.概念
- 2.特点
- 3. 发展历程
- 二、HBase的搭建部署
- 1. 准备工作
- 2. HBase的运行模式
- 3. 搭建(完全分布式模式)
- 三、HBase的核心功能模块
- 1. HBase和HDFS的关系
- 2. HBase和MapReduce的关系
- 3. HBase的架构
- 3.1. 模块一:Client
- 3.2. 模块二:Zookeeper
- 3.3. 模块三:HMaster (管理者,不存放元数据)
- 3.4. 模块四:HRegionServer
- 3.5. 总结:
- 四. HBase的使用场景
- 1. 特点:
- 2.使用场景:
- 五.HBase的列式存储和数据模型
- 1. 行式和列式存储
- 2. Rowkey 行健
- 3. 列族、列簇
- 4. 列名、列的修饰符
- 5. 时间戳
- 6. 单元格
- 7. 一行数据( 不止一行 )
- 8. 数据模型
- 9. 案例
- 六. HBase中表结构的设计(rowkey,columnFamily的设计)
- 1. 建表
- 2. rowkey设计
- 3. 列族的设计
- 七.HBase的客户端(Shell客户端:DDL/DML)
- 1. 常见命令
- 2. DDL命令 (HBase一个数据库)
- 3. DML命令
- 4. 运维工具命令
- 八.HBase的Java客户端
- 1. API介绍
- 2. 编码与案例
- 1. DDL
- 2.DML
- 九.MapReduce和HBase的交互
- 1.交互的模式:
- 2.MapReduce操作HBase的API:
- 十. HBase的核心概念
- 1. 存储的基本结构
- 1.1 存储方式:文件格式:HFile
- 1.2 HBase存储的数据类型:
- 1.3 HBase中存储的数据的存储结构:表的形式存储
- 1.4 数据操作的流程
- 2. HBase的HDFS文件介绍
- 3. Region的切割
- 4. compaction合并
- 5. HFile文件格式
- 6. KeyValue介绍
- 7. Load balance 负载均衡 介绍
- 十一、HBase的写入流程和数据的压缩
- 1. HBase的写入流程
- 1.1 写入操作
- 1.2 读取操作
- 2.数据的压缩
- 十二、HBase的优化
- 1. HBase的业务方向:
- 2. 设置:CPU的核数 ,4核+ ,并发的数量100+
- 3. JVM的参数
- 4. compaction和split
- 5. rowkey的设置 (Hbase表中唯一能够建立索引的字段)
- 十三、过滤器
- 1.概念:
- 2.基本思想:
- 3. 使用:
- 十四 案例
- 1. DDL
- 2.DML
- 3. 比较器(comparator)
- 4.过滤器(filter)
- 5. HBase作为输入源
- 6. 作为输出源
- 7. 作为共享源
一 .概述
apache google
HDFS GFS论文
MapReduce Google MapReduce论文
HBase BigTable 论文
HBase数据库,存储数据表,面现列存储
例如:关系数据库表Student
name gender age
zhangsan m 19
lisi w 29
列存储:
rowId1 name zhagnsan
rowId1 gender m
rowId1 age 19
rowId2 name lisi
rowId2 gender w
rowId2 age 29
分布式系统:面向列存储,数据量大,按照rowId进行分组,
分布式的存储到不同的机器上,提高检索效率
1.概念
分布式 可伸缩 的 大数据 存储
Hadoop数据库
large tables – billions of rows X millions of columns : 处理 十亿行 * 百万列的表
开源的、版本化、非关系型数据库
面向列存储的数据库
在HDFS文件系统上构建的数据库
google 使用bigtable在google的文件系统上实现了分布式数据存储
apache 使用Hbase在hadoop集群的HDFS文件系统上实现分布式数据存储
2.特点
搜索引擎:GFS / MapReduce / Hive / HBase
Linear and modular scalability. //线性模块化扩展方式
Strictly consistent reads and writes. //严格一致性读写操作
Automatic and configurable sharding of tables. //自动和可配置的表切割
Automatic failover support between RegionServers. //在区域服务间自动实现容灾
Easy to use Java API for client access. // 提供方便使用的Java API
Block cache and Bloom Filters for real-time queries. //提供了块缓存和过滤器实现 实时的查询
Query predicate push down via server side Filters //通过服务器端的过滤器实现查询预测
Extensible jruby-based (JIRB) shell // shell 交互窗口
-
高可靠性
底层实现是HDFS,分布式集群架构 -
高性能
海量数据处理,查询速度 8000条数据/s
写操作 10万条数据/s
HBase被众多的企业广泛的使用在缓存服务器 -
可伸缩性
Hbase集群,灵活的添加和删除节点,扩展性强
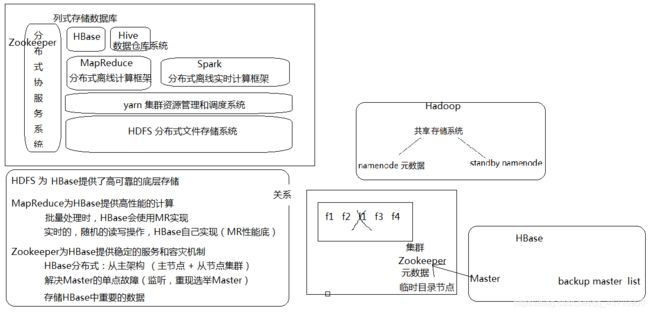
Hbase /HDFS / MapReduce / Zookeeper 关系:
3. 发展历程
思想源于 google 发布的论文 bigtable
HBase是属于Hadoop的一个功能模块(集成到了Hadoop中)
2010年,0.20 --> 0.89
HBase从Hadoop中脱离,需要单独维护,形成独立的项目
二、HBase的搭建部署
1. 准备工作
- JDK的环境搭建
- Zookeeper的环境搭建
- 节点选择:master 作为hbase的主节点
s201 / s203 作为hbase的从节点 - SSH服务(免密登陆)
- 域名系统:hosts /hostname
总结:hadoop集群和zookeeper一定得正常启动
2. HBase的运行模式
-
单机模式:(学习)
本地/独立模式:默认运行模式,使用本地文件系统
所有的服务和zookeeper都运行在一台服务器的一个jvm线程 -
分布式模式:
-
伪分布式模式:(学习)
使用本地文件系统/HDFS文件系统
所有的服务和zookeeper运行在一台服务器上的多个jvm线程 -
完全分布式模式:(商用)
将整个服务分布式的运行在各个节点
使用的HDFS文件系统
-
3. 搭建(完全分布式模式)
1. 下载hbase
2. 移动到linux 中 master节点
3. 解压缩
4. 修改配置文件
1. hbase-env.sh
export JAVA_HOME=/opt/programfile/jdk
2. hbase-site.xml
hbase.cluster.distributed
true
hbase.rootdir
hdfs://master:9000/hbase
hbase.zookeeper.quorum
master,s201,s203
3. regionservers
s201
s203
5. 配置环境变量
vi /etc/profile
export HBASE_HOME=/opt/programfile/hbase
export PATH=$HBASE_HOME/bin:$PATH
export HADOOP_CLASSPATH=$HBASE_HOME/lib/*
hbase----数据----HDFS存储(访问hbase的一些接口和类,依赖jar中)
执行刷新配置:source /etc/profile
6. hbase软件的分发
rsynch2.sh hbase-0.98.9-hadoop2
rsynch2.sh hbase
7. 启动hbase (hadoop集群和zookeeper一定得正常启动)
8. HBase的WebUI验证
http://master:60010
注意:zookeeper中的zoo.cfg 的列表一致:
server.0
server.1
server.3
hadoop的配置文件core-site.xml
fs.defaultFS
hdfs://master:9000
9. 使用hbase shell
进入: hbase shell
hbase> list //查看所有的表信息
hbase> create 'tabName' , '列簇name' //创建表
hbase> exit //退出
三、HBase的核心功能模块
1. HBase和HDFS的关系
HDFS为HBase提供了高可靠的底层存储
查看HDFS上HBase的存储信息:hadoop fs -ls /hbase
hdfs dfs -ls /hbase
HBase和Hive区别:
HBase有自己的处理和存储机制,具有自己的数据结构
2. HBase和MapReduce的关系
MapReduce为HBase提供的高性能的计算能力
HBase进行随机读写查询操作时都不会使用MapReduce(MR的时效性差)
HBase在进行批处理操作时使用MapReduce
3. HBase的架构
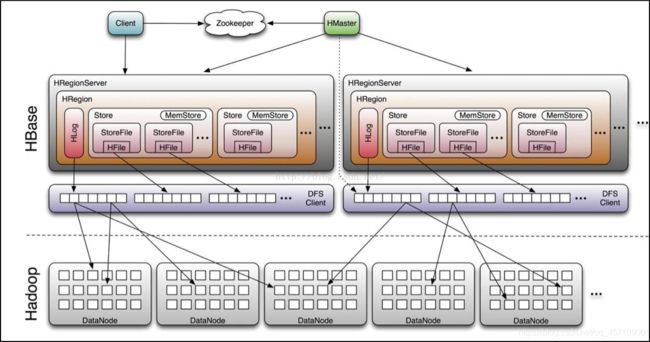
四大模块:Client 客户端、 Zookeeper 、 Hmaster 、 HRegionServer
3.1. 模块一:Client
Client是整个HBase系统的入口
Client可以通过RPC协议和HMaster和HRegionServer进行交互 (和HMaster间接交互)
Client对关系型数据库操作:
数据定义语言:DDL
数据操纵语言:DML
Client对HBase的操作:两种类型
管理类操作:
建表、删除表、修改表… …
client和HMaster进行交互
数据读写类操作:
对数据进行CRUD操作 (HDFS 没有update)
Clinet和HRegionServer进行交互
HBase的客户端的类型:
shell 客户端
Java 客户端
3.2. 模块二:Zookeeper
Zookeeper实现对HBase进行协调工作
Zookeeper:一个高可用的分布式数据管理和系统协调框架
-
存储HBase中的元数据
[replication, meta-region-server, rs, splitWAL, backup-masters, table-lock, region-in-transition, online-snapshot, master, running, recovering-regions, draining, namespace, hbaseid, table] -
实时监控节点状态(HMaster 和 HRegionServer)
启动HBase后,HMaster 和 HRegionServer信息被注册到ZK中
HMaster宕机:ZK从backup-masters选举一个新的HMaster
HregionServer宕机:ZK会将当前子节点的数据和任务移交给其他节点继续执行 -
存储所有的Region的寻址入口
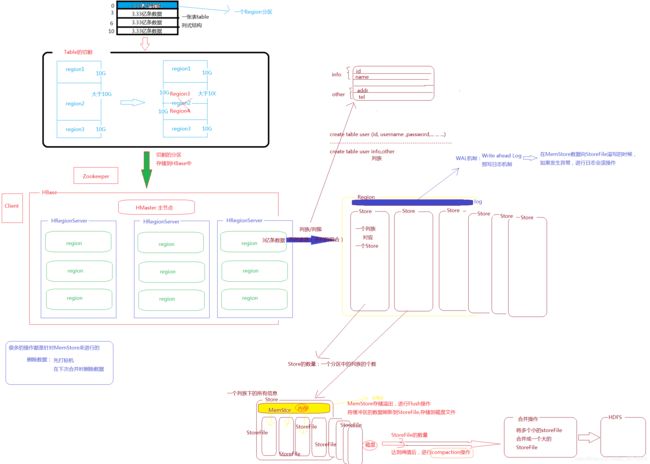
region:区域,分区table和region的关系:一个table可以对应多个region
默认情况下,创建一张表,自动给table分配一个region一个region的大小默认是:10G
一个region中的数据存储溢出时,会进行region的切分,源数据均分给每个分区region : 10G
region1: 5G ,空闲5G的空间
region2: 5G ,空闲5G的空间在HBase中会产生数以万计的region分区:对每个region进行编号存放
获取region:
获取region的寻址地址,此地址默认存储在Zookeeper中 -
保证HBase中只有一个HMaster节点
AtiveHMaster : 1个
BackupHMaster : n个
3.3. 模块三:HMaster (管理者,不存放元数据)
相当于HDFS中的NameNode , HMaster不存放数据
管理table和region
管理table: 对表进行创建、删除、修改、查询
管理region: 对region进行常见的管理操作,分配(有选择的分配region到HregionServer上)
管理HRegionServer的负载均衡:
HBase组织数据:表
Table组织数据:分区region
Region最终存储到子节点:HRegionServer上
调整Region的分布
监听HRegionServer的状态,发现region分布不均,
HMaster会对region进行迁移,调整了region的分布
在HRegionServer宕机,在HRegionServer上的Region数据的迁移工作也是HMaster实现
一个表中的一个大分区region被切分成两个region分区,分配哪个HRegionServer?是由HMaster实现
3.4. 模块四:HRegionServer
region是分布式存储的最小单元
数据存储的组件,相当于HDFS中的DataNode
HRegionServer -----1个子节点
HRegion ----- 1个分区 HRegion ----- 2个分区 HRegion ----- 3个分区 … … (个数:取决于当前数据的规模)
HLog 只有一个
WAL机制:write ahead log , 预写日志机制(日志回滚,保证数据的完整性,一致性)
HStore 1个 , HStore 2个 , HStore 3个 , HStore 4个 … …(个数:创建表时,表中列簇的个数)
MemStore 只有一个,缓存,默认大小是64M,如果缓存中的数据已经存满,触发flush操作
StoreFile 多个
HFile:是HBase最终形成的数据文件
student表
id age name gender — info 一个列簇(包含一系列的列信息)
score class teacher — stu 一个列簇 (包含一系列的列信息)
3.5. 总结:
HBase核心功能模块
Client /Zookeeper /HMaster /HRegionServer
存储元数据 管理节点/主节点 子节点(存储数据、处理数据)
架构的协调 管理table和region(10G)
节点状态的监听 HRegionServer的负载均衡处理
对失效的HRegionServer进行数据和业务的迁移
HRegionServer切割后的新分区的分配
HBase的实时性
HBase直接对缓存进行操作,实时高
例如:add/del操作
add---将数据添加的缓冲memStore中,打上add标记,返回add 结果给Client
del---将需要删除的文件加载的缓冲区memstore,对需要删除的数据打上del标记,此数据对Client不可见
磁盘上数据并没有变更,知道下次compaction合并操作进行时,才根据数据上的标记对数据进行相应的处理
table
Region
RegionServer(多个)
Log (WAL机制)
Region(多个)(列族切割)
Store(多个)
MemStore(64M,溢写操作)
StoreFile(阀值:3,compaction合并操作)
HFile
HRegionServer 是一个子节点,实现向HDFS读写数据,是HBase最核心的模块
HRegionServer内部管理多个HRegion对象(分区)
每个HRegion对应一张Table中的一个Region
一个HRegion由多个HStore组成
每个HStore存储一张Table中的一个列簇(Column Family)信息
HStore是HBase的存储核心:MemStore和StoreFile组成
MemStore : 缓存,用户写入数据先写入到缓存中
StoreFile:当MemStore满了后,会将缓存中的数据Flush到StoreFile中
底层实现是HFile
当StoreFile的文件数量达到一定的数量级时,会触发Compact合并操作
将多个StoreFile合并成一个StoreFile
1. 一张表会按照行的数量级被分割成多个region,每一个分割后的小region选择一个HRegionServer节点来存储
2. 每一个region的内部需要依据列簇进行划分成多个HStore
3. 每一个HStore中的数据最终落地到多个HFile文件中
4. region数量增加到一定的阀值后,会内部切割,超过10G
5. 随着region的分裂,当前管理region的HRegionServer中的分区越来越多,造成负载均衡
6. HMaster会根据当前的HRegionServer上管理的分区region的个数进行负载的均衡的处理
7. region内部的数据具有一个 MemStore, 缓存,用户写入数据先写入到缓存中
当MemStore满了后,会将缓存中的数据Flush到StoreFile中
8. 随着大量的Flush操作,造成StoreFile的数据量很大,需要使用HRegionServer对StoreFile进行合并操作
四. HBase的使用场景
1. 特点:
-
存储海量数据(TP级别)
-
高并发,高吞吐量
朋友圈
股票的监控和实时展示
气象网络和运行轨迹
实时报表
… … -
对数据模型、数据结构进行扩展
HBase : create table stu info列族 other列族
id name pwd -
效率高、进行数据的随机访问(按列访问)
不需要具备 关系型数据库的表的连接、交叉、事务等特性将用户的相关数据通过ETL进行数据的合并,清洗,过滤,最终生成一张 大表宽表 ,存储到HBase中
将常用的字段,归结到一个列簇中
Client可以针对某一个列族进行操作(不会查询其他的列簇)
2.使用场景:
海量数据的存储 + 高并发 + 时效性
搜索引擎(HBase理念---BigTable---搜索引擎产出数据量过大的处理效率低的问题)
新闻类(头条、实时、热点资讯)
气象数据的存储和展示
电信、连通、银行等订单查询业务
朋友圈的信息的发布和展示
五.HBase的列式存储和数据模型
1. 行式和列式存储
行式存储:数据结构式固定的(字段是固定的),每行数据模型都一样
每行需要一个主键
存储的都是具体的数据
列式存储:结构不固定(字段是灵活的)
需要多份主键
不仅要存储具体的数据,才要存储数据的列名,列族等等
关系型数据库结构严谨:列式结构的数据库就不需要维护结构吗?如何维护字段间的结构?
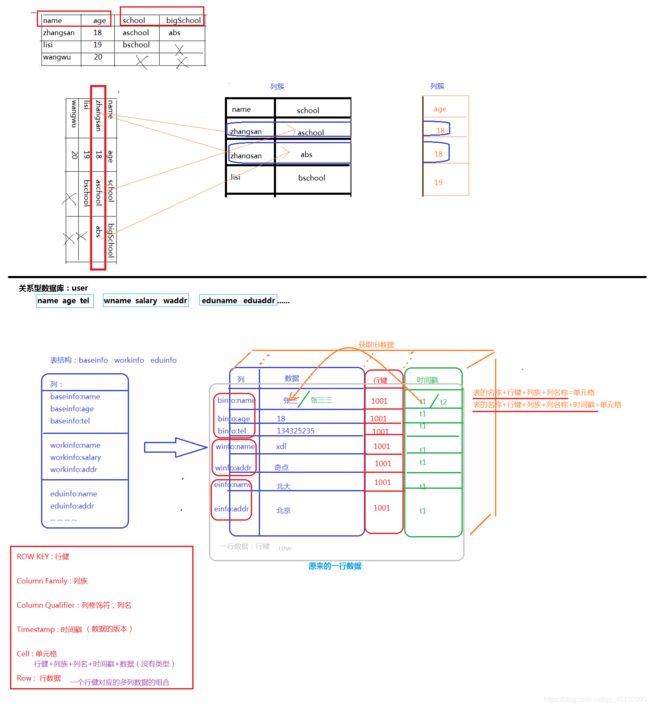
2. Rowkey 行健
维护了数据的结构
当前一条记录的主键
字符串类型:64K,字节数组的形式存储
数据会按照row key的字典顺序排序存储(合理的rowkey设计可以提示数据库的效率)
3. 列族、列簇
Column Family 列的家族组(多个列的合)
必须要在使用前定义
创建表的时候,定义了列族
定位一个单元格数据:列名前需要使用列族标识
列族:列名
例如:获取用户名
baseinfo:username
数据的录入:登陆表
基本信息: (列族: baseInfo)
姓名/年龄/手机号码…
工作经验: (列族: workInfo)
公司1/公司2/公司3/… …
教育经历: (列族: eduInfo)
大学/高中
4. 列名、列的修饰符
列族:列名 , 获取 一列的数据
每一列的名称
5. 时间戳
在数据录入时,数据会被打上一个时间戳,作为此数据 的版本 (一个数据可以存储多个版本)(立体的结构图)
录入数据时自动赋值
一个单元格的数据的展示:使用的最新的时间戳所对应的数据
时间戳使用倒叙的方式排序
避免一个字段的过多版本:管理和存储负担比较大
保存方式一:设置时间,保存最近一周
保存方式二:设置版本数量,设置5个版本
6. 单元格
使用行健、列族、列名、时间戳、数据 的组合称为一个单元格
定位单元格的方式:{rowkey , columnFamily :clomnName , version/timestamp }
单元格中的数据没有类型,字节码
7. 一行数据( 不止一行 )
一个rowkey对象的多个列的数据
row ----rowkey(多列:name,id,gender)----多行数据
8. 数据模型
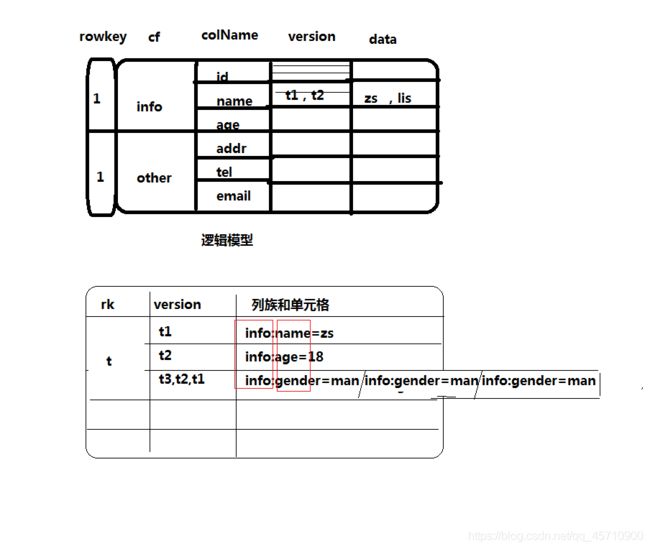
9. 案例
关系型数据库:
商品表:product name,price,time...
店铺表:shop name,addr,regtime...
关系:多对多 product_shop
处理多对多表关系:创建关系表
查询:使用商品表或者店铺表和关系表进行连接查询
列式存储数据库:
rowkey colFamily
product_rk info : name,price,time
p_shop:店铺的信息
rowkey colFamily
shop_rk info : name,addr,regtime
s_product:商品的信息
六. HBase中表结构的设计(rowkey,columnFamily的设计)
1. 建表
指定表名称 + 列族
例如:
create ‘student’ ,‘info’,‘other’ [ rowkey 默认创建此字段]
rowkey在建表时自动创建
添加数据:put 'student' , '1001' , 'info:name' , '张三'
put 'student' , '1001' , 'info:age' , '18'
put 'student' , '1002' , 'info:name' , '李四'
put 'student' , '1002' , 'other:addr' , '北京'
根据rowkey确定row一行
根据列族确定一列,根据列名确定一个单元格
单元格的值根据时间戳确定具体的数值
2. rowkey设计
table-------region
1 ... ...
2 ... ...
3 ... ...
.. .. ...
... ... ..
... .... ...
1亿 ... ...
10G
table-------region1------------------>region2------------------>region3------------------>region4
1 ... ... 112323 ... ...
25 ... ... 456546456 ... ...
48 ... ... 464575 ... ...
5千万... ... 1亿 ... ...
空闲5G 空闲5G
1亿01 ... ...
1亿02 ... ...
1亿03 ... ...
1亿04 ... ...
1亿05 ... ...
RowKey的尽量使用散列的方式进行设计
使数据均匀的分布到不同的region中
RowKey的长度尽量短(节省存储空间,提高存取效率)
RowKey按照字典顺序由低到高存储在数据表中
HBase只能在Rowkey上建立索引
3. 列族的设计
user id name age gender tel addr ... ... ...
create 'user' , '列族1' , '列族2', '列族3'... ... 列族的个数?
table -----------region-----------store1(列族的个 数) -------store2------store3
Flush : 溢写64M (在region中进行的操作)
Compaction:合并,store的个数超过阀值 (在region中进行的操作)
问题:多个列族在执行Fluash和compaction操作时,造成大量IO的负载
原因:一个store的flush和compaction操作是针对一个region操作的
region中的flush和compaction操作是全局进行的
结论:列族的数量尽量少
七.HBase的客户端(Shell客户端:DDL/DML)
1. 常见命令
status 查看当前集群的状态
help 查看所有的命令
version 查看hbase的版本
退格键设置:backpace无效
使用del键: xshell中,选择文件---属性---终端---键盘---delete---ASCII127 ---保存退出
2. DDL命令 (HBase一个数据库)
创建:
create “tableName” , ‘columnFamilyName1’ , “columnFamilyName2”… …
例如:
create ‘user’ ,‘info’ ,‘otherinfo’
查看:
list 罗列多有的表
describe ‘user’ 查看某一个具体的表的信息
表的上下线:
disable ‘user’ 下线表
enable ‘user’ 上线表
exists 'user' 判断表是否存在(不是是否在线)
is_disable 'user' 判断表是否下线
is_enable 'user' 判断表是否上线
删除:删除表,先让表下线
disable ‘user’
drop ‘user’
修改:
alter ‘user’ , NAME=>‘新的列族名称’ //添加新列族
alter ‘user’ , ‘delete’=>‘列族名称’ //删除列族
alter 'user' , {NAME=>'列族的名称' } //添加新列族
alter 'user' , {NAME=>'列族的名称' ,METHOD='delete'} //删除列族
3. DML命令
添加数据:put命令,写入数据
表名称 rowkey 列族 列名 数据
put 'user' ,'zhangsan','workinfo:addr','beijing'
put 'user' ,'zhangsan','workinfo:name','xdl'
put 'user' ,'zhangsan','workinfo:tel','666'
put 'user' ,'zhangsan','addrinfo:name','hebei'
put 'user' ,'lisi','workinfo:addr','tianjing'
put 'user' ,'lisi','addrinfo:name','xxxx'
查看数据:扫描
scan 'user'
get 命令:读取一行数据
get 'user' ,'zhangsan' // 获取rowkey对应的一行数据(包括当前行所对应的所有的列族中的所有的列数据)
get 'user' ,'zhangsan','workinfo' //获取rowkey对应的一行数据的某一个列族中的所有列数据
get 'user' ,'zhangsan','workinfo:name' //tableName+rowkey+columnFamily+columnName ,定位到一个单元格
get 'user' ,'zhangsan','workinfo:name' ,TIMESTAMP=>12423532 //获取单元格中的某一个版本的数据
删除数据:
delete 删除一个单元格
delete 'user','zhangsan','workinfo:addr'
deleteall 删除整行
deleteall 'user','zhangsan'
清空表数据:
truncate 'user'
数据的修改:
put 'user' ,'zhangsan','workinfo:name','ldx23456'
get 'user' ,'zhangsan','workinfo:name' //获取最新的名称
get 'user' ,'zhangsan',{COLUMN=>'workinfo:name',TIMESTAMP=>1562145998062} //获取指定版本的名称
4. 运维工具命令
balance_switch true //开启均衡负载
balance_switch false //关闭均衡负载
解决Region偏移问题
compact合并表或者region
compact ‘user’ //手动对表进行合并
split 拆分region:
split ‘user’
将region进行切割
compact : 小规模合并
storefile文件超过阀值就进行合并操作
major_compact: 大合并
将表中的所有的region中的store中的所有的storefile全部合并成一个大文件
复制和安全:
HBase层面的处理/高可用的操作
八.HBase的Java客户端
1. API介绍
Java类 HBase数据库
HBaseAdmin HBase数据库对象
管理HBase数据库中表信息
提供:创建表、删除表、查询所有表信息,设置表上下线、更新表等操作
HBaseConfiguration HBase数据库的配置对象 ,HBase的配置信息都是在分布式集群上进行设置
hbase-site.xml
HColumnDescriptor 列族的描述对象
维护和管理列族的信息
提供:获取/设置列族的名称,获取/设置列族的属性
HTable HBase中的表对象
使用对表进行DML操作
提供:put/delete/get等等操作
HTableDescriptor HBase中的表对象的描述对象
提供:获取/设置表名称,获取/设置表的属性,添加和删除列族信息
GET/PUT/SCAN/Result DML操作HBase中数据的对象
获取一行的数据
添加一行
查看行的数据
封装了一行的数据
2. 编码与案例
-
创建工厂
-
导入jar包
-
运行方式:
在windows上访问Linux上的HBase:
在当前项目中创建一个source Folder ,在此文件夹中添加配置文件:hbase-site.xml文件修改一下hosts文件:c:\windows\System32\drivers\etc\hosts 192.168.175.200 master 192.168.175.201 s201 192.168.175.202 s203在Linux上执行xx.jar的方式访问HBase:
无需编写相关配置 -
编码
实现DDL操作:创建表、删除表、修改表、设置表(上下线,是否存在)等等实现DML操作:添加数据、删除数据、扫描数据、获取数据等等
1. DDL
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class HBaseDDLClient {
static Configuration config = HBaseConfiguration.create();
public static void main(String[] args) throws Exception, Exception, Exception {
HBaseAdmin admin = new HBaseAdmin(config);
// createHBaseTable(admin);
addHBaseColumnFamily(admin);
}
private static void addHBaseColumnFamily(HBaseAdmin admin) throws IOException {
//1. 调用admin的API中的更改表的方法
admin.addColumn("student", new HColumnDescriptor("eclipse_add_info"));
admin.addColumn("teacher", new HColumnDescriptor("eclipse_add_info"));
System.out.println("add success!!!");
// admin.disableTable(tableName);
// admin.deleteTable(tableName);
}
/**
* 创建表
*
* @param admin
* @throws IOException
*/
private static void createHBaseTable(HBaseAdmin admin) throws IOException {
// 1. 创建一个数据表
// 1.1 获取HBaseAdmin对象
// DDL:创建 表、修改表、上下线... ...
// 1.2 创建HTableDescriptor
// 指定创建的表的表名称和表中含有的列族
@SuppressWarnings("deprecation")
HTableDescriptor tableDesc = new HTableDescriptor("student".getBytes());
// 设置列族
String[] columnFamilys = { "user", "work", "edu" };
for (int i = 0; i < columnFamilys.length; i++) {
tableDesc.addFamily(new HColumnDescriptor(columnFamilys[i].getBytes()));
}
if (admin.tableExists("student".getBytes())) {
System.out.println("table is exists!");
} else {
admin.createTable(tableDesc);
System.out.println("create table success!");
}
}
}
2.DML
import java.io.IOException;
import java.io.InterruptedIOException;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.RetriesExhaustedWithDetailsException;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.util.Bytes;
public class HBaseDMLClient {
static Configuration config = HBaseConfiguration.create();
public static void main(String[] args) throws Exception, Exception, Exception {
putDatas();
// deleteDataCell();
// deleteDataRow();
// deleteDataColumnFamily();
// getDataCell();
// getDataRow();
scanDatas();
}
private static void scanDatas() throws IOException, InterruptedIOException, RetriesExhaustedWithDetailsException {
// 1. 获取表对象,对表进行各种操作:put/delete/get等等
HTable htable = new HTable(config, "teacher");
Scan scan = new Scan();
ResultScanner scanner = htable.getScanner(scan );
for (Result result : scanner) {
List kv = result.list();
for (KeyValue keyValue : kv) {
System.out.println("Family"+Bytes.toString(keyValue.getFamily()));
System.out.println(""+Bytes.toString(keyValue.getQualifier()));
System.out.println(""+Bytes.toString(keyValue.getValue()));
System.out.println(""+keyValue.getTimestamp());
System.out.println(" ---------------------");
}
System.out.println("**********************");
}
}
private static void getDataCell() throws IOException, InterruptedIOException, RetriesExhaustedWithDetailsException {
// 1. 获取表对象,对表进行各种操作:put/delete/get等等
HTable htable = new HTable(config, "teacher");
Get get = new Get("10003".getBytes());
// 2. 设置查询的参数
get.addColumn("userinfo".getBytes(), "uname".getBytes());
// 3. 执行查询操作
Result result = htable.get(get);
List list = result.listCells();
// 4. 展示结果数据
for (Cell cell : list) {
String family = new String(cell.getFamily());
String colName = new String(cell.getQualifier());
String value = new String(cell.getValue());
System.out.println("family:" + family);
System.out.println("colName:" + colName);
System.out.println("value:" + value);
System.out.println(
"valueNew:" + Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));
System.out.println("timestamp:" + cell.getTimestamp());
System.out.println("===================");
}
}
private static void getDataRow() throws IOException, InterruptedIOException, RetriesExhaustedWithDetailsException {
// 1. 获取表对象,对表进行各种操作:put/delete/get等等
HTable htable = new HTable(config, "teacher");
// 2. 设置查询的参数
Get get = new Get("10001".getBytes());
// 3. 获取数据
Result result = htable.get(get);
// 4. 数据的展示
List| cells = result.listCells();
for (Cell cell : cells) {
String family = new String(cell.getFamily());
String colName = new String(cell.getQualifier());
String value = new String(cell.getValue());
System.out.println(
"family:" + Bytes.toString(cell.getFamilyArray(), cell.getFamilyOffset(), cell.getFamilyLength()));
System.out.println("colName:"
+ Bytes.toString(cell.getQualifierArray(), cell.getQualifierOffset(), cell.getQualifierLength()));
System.out.println(
"valueNew:" + Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));
System.out.println("timestamp:" + cell.getTimestamp());
System.out.println("===================");
}
}
private static void deleteDataCell()
throws IOException, InterruptedIOException, RetriesExhaustedWithDetailsException {
// 1. 获取表对象,对表进行各种操作:put/delete/get等等
HTable htable = new HTable(config, "teacher");
// 封装了删除的具体参数
Delete delete = new Delete("10002".getBytes());
delete.deleteColumn("userinfo".getBytes(), "uname".getBytes());
// 2. 调用HTable,DML方法
htable.delete(delete);
System.out.println("delete success !!");
}
private static void deleteDataRow()
throws IOException, InterruptedIOException, RetriesExhaustedWithDetailsException {
HTable htable = new HTable(config, "teacher");
// 封装了删除的具体参数
Delete delete = new Delete("10002".getBytes());
htable.delete(delete);
System.out.println("delete success !!");
}
private static void deleteDataColumnFamily()
throws IOException, InterruptedIOException, RetriesExhaustedWithDetailsException {
HTable htable = new HTable(config, "teacher");
// 封装了删除的具体参数
Delete delete = new Delete("10001".getBytes());
delete.deleteFamily("workinfo".getBytes());
htable.delete(delete);
System.out.println("delete ColumnFamily success !!");
}
/**
* 添加数据
*
* @throws IOException
* @throws InterruptedIOException
* @throws RetriesExhaustedWithDetailsException
*/
private static void putDatas() throws IOException, InterruptedIOException, RetriesExhaustedWithDetailsException {
// 1. 添加数据
// 1.1 获取表对象,对表进行各种操作:put/delete/get等等
HTable htable = new HTable(config, "teacher");
// 上传操作的对象
Put put = new Put("10004".getBytes());// rowkey
put.add("userinfo".getBytes(), "uname".getBytes(), "zhaoliu".getBytes());
put.add("userinfo".getBytes(), "uage".getBytes(), "10".getBytes());
put.add("userinfo".getBytes(), "utel".getBytes(), "111235346".getBytes());
put.add("userinfo".getBytes(), "ugender".getBytes(), "man".getBytes());
put.add("eduinfo".getBytes(), "ename".getBytes(), "beida".getBytes());
put.add("eduinfo".getBytes(), "eaddr".getBytes(), "beijing".getBytes());
put.add("workinfo".getBytes(), "wname".getBytes(), "baidu".getBytes());
put.add("workinfo".getBytes(), "waddr".getBytes(), "beijing".getBytes());
put.add("eclipse_add_info".getBytes(), "eclipse_version".getBytes(), "2.3.2".getBytes());
// 1.2执行put操作
htable.put(put);
System.out.println("put success!!");
}
}
| | 九.MapReduce和HBase的交互
1.交互的模式:
HBase输入结果给MapReduce: 利用MR计算框架使用物理机器的并行处理
MapReduce输入结果给HBase: 利用HBase高效、快速的处理能力
2.MapReduce操作HBase的API:
TableInputFormat 将HBase中表格的数据转换成MapReduce可以读取的格式
TableOutputFormat 将mapReduce格式的数据转换为HBase表的格式
TableMapper Mapper类的扩展类,所有以HBase作为输入源的Mapper都需要继承此类
TableReducer Reducer类的扩展类,所有以HBase作为输出源的Reducer都需要继承此类
TableMapReduceUtil 设置TableMapper和TableReduce的工具类
执行jar包:
hadoop jar Main.jar meiyou /teacher/results/ mrtohbasetb
创建表:mrtohbasetb
注意:jar打包时,选中export java source file and resource,再打包
十. HBase的核心概念
1. 存储的基本结构
1.1 存储方式:文件格式:HFile
HBase和HDFS共同协作来完成文件数据的存储操作的
HBase中BLOCKSIZE => '65536' /1024 = 64k
HDFS中BLOCKSIZE => 128 M
HBase中具有自己的文件的组织结构(数据块),最终数据块还是存储到HDFS上的数据块中。
HBase具有自己的文件格式:HFile
1.2 HBase存储的数据类型:
HLog: WAL日志文件
Regions: 实际存储的数据文件
HBase中对文件进行操作都是由HRegionServer完成的
1.3 HBase中存储的数据的存储结构:表的形式存储
系统表:
1.元数据表:hbase:meta
存储所有用户表的region的相关信息的
2.root表:hbase:root
存储了meta表的信息
只能含有一个region信息,
1.x+的版本中数据迁移到zk中
3.zookeeper:
存储了Root表的地址信息
请求-----zookeeper-----root------meta(加载到内存)------regions
上述操作的流程是一个层级目录的B+的结构
meta表中的所有数据会加载到内存中进行维护
客户端将历史操作的信息进行缓存
4.命名空间表:hbase:namespace
对表进行管理(分组管理,类似于数据库)
系统默认定义的namespace:
hbase: 系统内建表
default: 用户未指定命名空间时创建表的位置
命名空间的操作:
create_namespace 'xxname' 创建命名空间
describe_namespace 'xxname' 查看命名空间
drop_namespace 'xxname' 删除命名空间
list_namespace 列出所有的命名空间
用户表:
直接创建和生成的表
在创建表时,可以指定表所属的命名空间
1.4 数据操作的流程
客户端查询数据:
1. 连接zookeeper,从zk中获取root表的地址,获取root表所在的HRegionSever服务器
2. 从root表中获取操作数据(rowkey)范围内的meta信息,进而查找到数据所在的HRegionServer
3. 从meta表中存储的region中胡群殴rowkey所对应的region地址
从HRegionServer中的region中获取用户需要操作的rowkey对应的数据
zookeeper-----root-----meta 三层目录(B+树)
在HBase启动时HMaster负责将所有的Region分配给HRegionServer服务器(包含了root表和meta表的region信息)
2. HBase的HDFS文件介绍
HBase上的数据最终存储在HDFS上:
在HDFS上自动创建一个目录/hbase ,存储HBase上的所有数据
查看HBase在HDFS上存储的所有数据:hdfs dfs -ls -R /hbase
此目录下的文件:
一:直接存储在HBase根目录下的
WAL Log 文件
表数据文件
二:存储在表数据文件中的
表的命名空间
Region
region分区信息
列族信息 (每一张表的每一个列族有会具有一个单独的目录)
结构体系
HRegionServer
Region (切割)
Store(个数:列族)
StoreFile
3. Region的切割
在Region中的某一个HStoreFile文件大小超过一定的阀值后,此区分被切割两份
原来Region中的数据被平分
hbase.hregion.max.filesize
10737418240
Maximum HStoreFile size. If any one of a column families' HStoreFiles has
grown to exceed this value, the hosting HRegion is split in two.
切割的过程:
meta表中更新更改切割出来的新的region元数据
meta表删除原来被切割的region的元数据
region被切分的默认条件是:HStoreFile的大小超过10G
region
storefile1,storefile1,storefile1,storefile1
-------------------------------------------->merge
memstore---->生成新的storefile---->storeFile的数据量一直在增加 ------>split阀值:10G
----->storeFile的个数一直在增加 ------>merge阀值:3个
4. compaction合并
Memstore存储的数据达到一定的阀值:64k,不断的将其数据内容flush到磁盘,形成storefile文件
storefile文件的越来越多, 当storefile文件的个数达到一定的阀值后,进行storefile文件的合并,
合并成规模更少,内容更大的文件(storefile内容一直在增加,到一定的阀值,split)
合并的类型:
minor compaction:小合并
针对一个store,其内部的storefile的数量达到一定的阀值:进行小合并
min: 3 (触发合并操作的必要条件)
store
---memstore
---storefile
hbase.hstore.compactionThreshold
3
If more than this number of HStoreFiles in any one HStore
(one HStoreFile is written per flush of memstore) then a compaction
is run to rewrite all HStoreFiles files as one. Larger numbers
put off compaction but when it runs, it takes longer to complete.
max: 10
hbase.hstore.compaction.max
10
Max number of HStoreFiles to compact per 'minor' compaction.
问题: 5G + 5k 合并
50M + 5k 合并
合并操作:从磁盘读数据到内存,在内存合并进行写磁盘操作
一个大文件和一个小文件进行合并操作,开销巨大
解决:
设置阀值,超过阀值不参与合并(避免超大文件和小文件进行合并)
问题:设置阀值后,在阀值之外的storefile无法参与合并
解决:大合并
major compaction:大合并
针对一个region中所有的store中所有的storefile,将其合并成一个storefile文件
自动触发时间间隔:24小时,耗时
在合并操作中,当前region处理阻塞状态,无法被访问
LSM和B+树比较:
b+没有合并机制,存在大量的小文件,数据量级达到GB+,
读写效率极低,相当于随机访问磁盘
5. HFile文件格式
table
region... ...
Store... ...
StoreFile ... ...
HFile
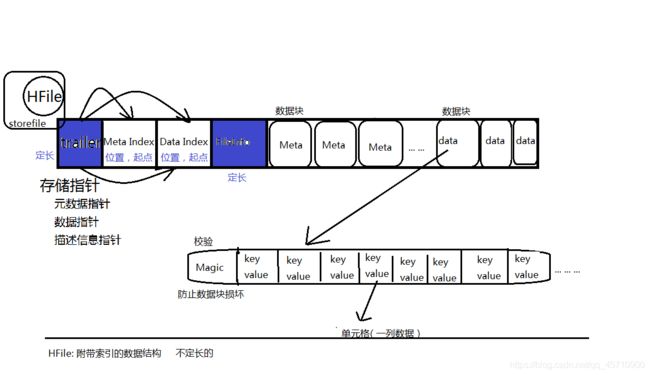
总结: StoreFile是对HFile的轻量级的封装
Hfile文件不定长
trailer中的指针指向数据块的起始位置(Data index ,Meta index)
Data Index 和Meta Index 块 存储每一个Data块和Meta块的起始位置
每一个Data块都是以一个Magic开始,存储一组随机数,防止数据损坏
每一个Data块中的数据都是一组组key-value的形式数据
6. KeyValue介绍
Hfile文件中的keyvalue本质上就是一个字节数组
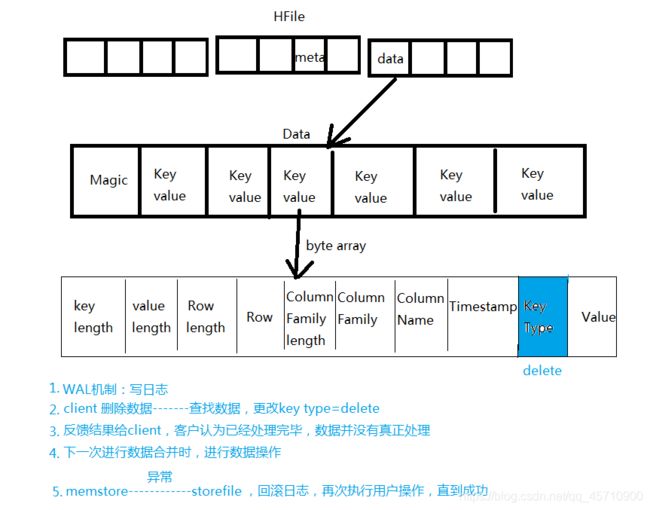
总结:keyvalue是一个byte数组
开始位置,存储key和value的长度
行健的长度:row length
行健:row
列族长度:columnfamily length
列族:columnfamily
列名称:column Quailifier
时间戳:timestamp
key数据类型:keytype
数据:value
WAL机制:write log at first ,then write data
对数据进行操作前,先写日志。
7. Load balance 负载均衡 介绍
概念:
HMaster负责HRegionServer的负载均衡(HMaster负责region的分发)
周期性的操作,通过负载均衡实现Region分配到RegionServer上
默认情况下:负载均衡是开启状态
算法:如何判断各个regionserver节点上region的个数是否均衡?
1. 计算均衡值的标准范围:
region的总个数
regionserver的个数
求平均值:每一个regionserver上应该存储在的region的个数
求最大最小值:
2. 遍历所有的regionServer
针对region个数小于最小值的regionserver节点,后续新的region分配时,优先考虑此节点进行分配
直到当前regionserver中region的个数大于等于最小值
针对region个数大于最大值的regionserver节点,后续新的region分配时,不考虑此节点,
将当前节点上的region迁移到其他节点,直到当前节点中分区的个数小于或者等于最大值
3. 循环步骤1和步骤2
直到当前Hbase集群上所有的regionServer上的region的个数都在min和max值之间,停止均衡负载操作
此时集群已经处于一种负载均衡的状态
案例:三台HRegionServer,每台上的分区个数分别为: 15 10 5
HRegionServer1 HRegionServer2 HRegionServer3
region总个数:30
regionserver总个数:3
平均值:10
权重:10+10*0.2 = 12
hbase.regions.slop
0.2
Rebalance if any regionserver has average + (average * slop) regions.
最大值: 12 = avg*(1+0.2)
最小值: 8 = avg*(1-0.2)
十一、HBase的写入流程和数据的压缩
1. HBase的写入流程
1.1 写入操作
put 'tbname' ,'rowkeyname','columnfamilyName:columnName','datas'
客户端:
发送写请求
提交请求
等待结果
服务器端:
获取region
准备写入数据
请求锁
更新时间戳
写入memstore
操作磁盘
更新WAL
1. client访问zookeeper,从root中获取meta信息,从meta中获取region信息
2. 根据用户输入的路径:命名空间+表名称+行健 ,去meta中查找响应的region信息
3. 定位到具体的Hregionserver
4. 将用户的写操作存入HLog中和Memstore中
5. 在Memstore中将数据溢写成多少StoreFile文件
在溢写的过程中,有数据丢失,通过HLog中记录的用户操作,再次执行用户的操作
6. 当溢写的多个storefile文件的数量达到一定的阀值时,进行compaction合并操作,将多个小文件合成一个大文件
7. 当前storefile中存储的数据量达到一定的阀值时,进行split操作,由HMaster将拆分的region分发给HRegionServer
使用均衡负载
1.2 读取操作
get /scan
1. client先范文zookeeper,获取region的位置信息,定位到regionserver
2. 根据用户指定的路径,找到对象的region和单元格
3. 先从Memstore中查找数据,如果不存在,在到storefile文件读
三层的的类B+树的检索模式:
一层:检索存储在zk上,保存的root和meta信息
二层:到root表中查找匹配meta表的region信息(regionServer的信息)
三层:到meta表中查找用户表的region信息 (用户表的地址信息)
2.数据的压缩
HBase支持的压缩算法:
算法 压缩比 压缩时间
GZIP : 10% (压缩到) 20M /s
LZO: 20% 130M/s
SNAPPY: 22% 170M/s
ZIPPy:
结论:
SNAPPY/ZIPPy耗时短 预先安装
GZIP最耗时 自带的
LZO比GZIP快 预先安装
GZIP压缩率最高
LZO居中
SNAPPY/ZIPPY压缩最低
配置:
创建表的时候指定压缩算法:
create 'tbName' , { NAME=>'columnFamilyName',COMMPRESSION=>'GZ'}
修改表的压缩算法:
alert 'tbName' , { NAME=>'userInfo',COMMPRESSION=>'comPName'}
十二、HBase的优化
依赖HDFS的存储特性
1. HBase的业务方向:
Read读方向:
集群偏向于读,将hfile.block.cache.size参数的数值调大
Write写方向:
集群偏向于写,将hfile.block.cache.size参数的数值调小
//设置读缓存的heap空间的大小,StoreFile/HFile/Memstore
hfile.block.cache.size
0.4 # 40 %
Percentage of maximum heap (-Xmx setting) to allocate to block cache
used by HFile/StoreFile. Default of 0.4 means allocate 40%.
Set to 0 to disable but it's not recommended; you need at least
enough cache to hold the storefile indices.
2. 设置:CPU的核数 ,4核+ ,并发的数量100+
RPC Server的实例个数。主节点HMaster能够受理的Handler的数量
hbase.regionserver.handler.count
30
Count of RPC Listener instances spun up on RegionServers.
Same property is used by the Master for count of master handlers.
3. JVM的参数
JVM进行调优
JVM的堆空间,大小建议设置成物理主机的二分之一
开发工具:JDK1.7+
4. compaction和split
阀值的设置
5. rowkey的设置 (Hbase表中唯一能够建立索引的字段)
主键:
自然主键(没有含义),自然增长的一个序列(一系列的序号): id , num ... ...
业务主键(具有特定的含义):学生的学号,用户的身份证,商品的商品编号... ...
rowkey行健:
建议使用业务主键:推荐结合时间
uid + timestamp : 查询某个月份的账单,年份
timestamp : 查询某个时间段的账单
uid : 查看所有订单
十三、过滤器
BLOOMFILTER => ‘ROW’ 是一个列族的属性
在分布式系统中,HBase的查询性能在有过滤器的情况下,性能能够提升50%
1.概念:
Bloom filter 是由 Howard Bloom 在 1970 年提出的二进制向量数据结构,
它具有很好的空间和时间效率,被用来检测一个元素是不是集合中的一个成员。
2.基本思想:
判断一个元素是否在一个集合中
常见的ArrayList,Linked等,变量整个集合,获取结果数据
数据量增加,消耗的存储空间增大,检索效率降低
Bloom filter使用的是HASH表的数据结构,通过一个hash函数将一个元素映射到一个位矩阵中(矩阵中的一个点)
查看当前点的数值是否是1来判断当前结合中是否存在此元素
优点:
存储效率,查询时间高于一般的算法
Hbase中创建的表:
columnFamily 上都使用了: Bloom filter
类型 : 在每列上单独启动的(None/row/rowcol)
row:rowkey的hash值在每次插入行时被添加到布隆中
行健路径错误,直接被过滤
rowcol:rowkey+columnFamily+columnName 的hash值存储到布隆中
单元格路径错误,直接被过滤
none:不使用过滤器
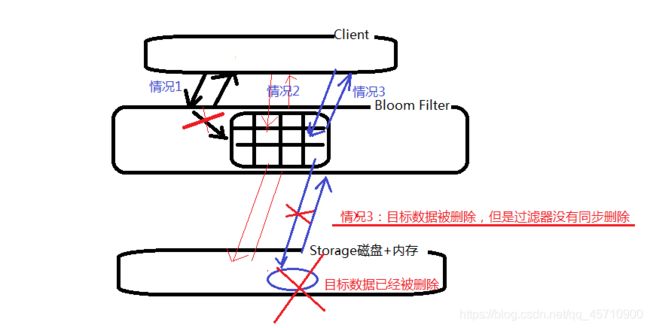
特点:如果过滤器中存在此数据,磁盘上不一定存在
如果过滤器中不存在此数据,磁盘上页一定不存在此数据
3. 使用:
alert 'tbName' , { NAME=>'userInfo',BLOOMFILTER=>'NONE/ROW/ROWCOL'}
describe 'tbName'
get 'tbName' ,'userInfo1'
get 'tbName' ,'userInfo:age1'
十四 案例
1. DDL
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class HBaseDDLClient {
static Configuration config = HBaseConfiguration.create();
public static void main(String[] args) throws Exception, Exception, Exception {
HBaseAdmin admin = new HBaseAdmin(config);
// createHBaseTable(admin);
addHBaseColumnFamily(admin);
}
private static void addHBaseColumnFamily(HBaseAdmin admin) throws IOException {
//1. 调用admin的API中的更改表的方法
admin.addColumn("student", new HColumnDescriptor("eclipse_add_info"));
admin.addColumn("teacher", new HColumnDescriptor("eclipse_add_info"));
System.out.println("add success!!!");
// admin.disableTable(tableName);
// admin.deleteTable(tableName);
}
/**
* 创建表
*
* @param admin
* @throws IOException
*/
private static void createHBaseTable(HBaseAdmin admin) throws IOException {
// 1. 创建一个数据表
// 1.1 获取HBaseAdmin对象
// DDL:创建 表、修改表、上下线... ...
// 1.2 创建HTableDescriptor
// 指定创建的表的表名称和表中含有的列族
@SuppressWarnings("deprecation")
HTableDescriptor tableDesc = new HTableDescriptor("student".getBytes());
// 设置列族
String[] columnFamilys = { "user", "work", "edu" };
for (int i = 0; i < columnFamilys.length; i++) {
tableDesc.addFamily(new HColumnDescriptor(columnFamilys[i].getBytes()));
}
if (admin.tableExists("student".getBytes())) {
System.out.println("table is exists!");
} else {
admin.createTable(tableDesc);
System.out.println("create table success!");
}
}
}
2.DML
import java.io.IOException;
import java.io.InterruptedIOException;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.RetriesExhaustedWithDetailsException;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.util.Bytes;
public class HBaseDMLClient {
static Configuration config = HBaseConfiguration.create();
public static void main(String[] args) throws Exception, Exception, Exception {
putDatas();
// deleteDataCell();
// deleteDataRow();
// deleteDataColumnFamily();
// getDataCell();
// getDataRow();
scanDatas();
}
private static void scanDatas() throws IOException, InterruptedIOException, RetriesExhaustedWithDetailsException {
// 1. 获取表对象,对表进行各种操作:put/delete/get等等
HTable htable = new HTable(config, "teacher");
Scan scan = new Scan();
ResultScanner scanner = htable.getScanner(scan );
for (Result result : scanner) {
List kv = result.list();
for (KeyValue keyValue : kv) {
System.out.println("Family"+Bytes.toString(keyValue.getFamily()));
System.out.println(""+Bytes.toString(keyValue.getQualifier()));
System.out.println(""+Bytes.toString(keyValue.getValue()));
System.out.println(""+keyValue.getTimestamp());
System.out.println(" ---------------------");
}
System.out.println("**********************");
}
}
private static void getDataCell() throws IOException, InterruptedIOException, RetriesExhaustedWithDetailsException {
// 1. 获取表对象,对表进行各种操作:put/delete/get等等
HTable htable = new HTable(config, "teacher");
Get get = new Get("10003".getBytes());
// 2. 设置查询的参数
get.addColumn("userinfo".getBytes(), "uname".getBytes());
// 3. 执行查询操作
Result result = htable.get(get);
List list = result.listCells();
// 4. 展示结果数据
for (Cell cell : list) {
String family = new String(cell.getFamily());
String colName = new String(cell.getQualifier());
String value = new String(cell.getValue());
System.out.println("family:" + family);
System.out.println("colName:" + colName);
System.out.println("value:" + value);
System.out.println(
"valueNew:" + Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));
System.out.println("timestamp:" + cell.getTimestamp());
System.out.println("===================");
}
}
private static void getDataRow() throws IOException, InterruptedIOException, RetriesExhaustedWithDetailsException {
// 1. 获取表对象,对表进行各种操作:put/delete/get等等
HTable htable = new HTable(config, "teacher");
// 2. 设置查询的参数
Get get = new Get("10001".getBytes());
// 3. 获取数据
Result result = htable.get(get);
// 4. 数据的展示
List| cells = result.listCells();
for (Cell cell : cells) {
String family = new String(cell.getFamily());
String colName = new String(cell.getQualifier());
String value = new String(cell.getValue());
System.out.println(
"family:" + Bytes.toString(cell.getFamilyArray(), cell.getFamilyOffset(), cell.getFamilyLength()));
System.out.println("colName:"
+ Bytes.toString(cell.getQualifierArray(), cell.getQualifierOffset(), cell.getQualifierLength()));
System.out.println(
"valueNew:" + Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));
System.out.println("timestamp:" + cell.getTimestamp());
System.out.println("===================");
}
}
private static void deleteDataCell()
throws IOException, InterruptedIOException, RetriesExhaustedWithDetailsException {
// 1. 获取表对象,对表进行各种操作:put/delete/get等等
HTable htable = new HTable(config, "teacher");
// 封装了删除的具体参数
Delete delete = new Delete("10002".getBytes());
delete.deleteColumn("userinfo".getBytes(), "uname".getBytes());
// 2. 调用HTable,DML方法
htable.delete(delete);
System.out.println("delete success !!");
}
private static void deleteDataRow()
throws IOException, InterruptedIOException, RetriesExhaustedWithDetailsException {
HTable htable = new HTable(config, "teacher");
// 封装了删除的具体参数
Delete delete = new Delete("10002".getBytes());
htable.delete(delete);
System.out.println("delete success !!");
}
private static void deleteDataColumnFamily()
throws IOException, InterruptedIOException, RetriesExhaustedWithDetailsException {
HTable htable = new HTable(config, "teacher");
// 封装了删除的具体参数
Delete delete = new Delete("10001".getBytes());
delete.deleteFamily("workinfo".getBytes());
htable.delete(delete);
System.out.println("delete ColumnFamily success !!");
}
/**
* 添加数据
*
* @throws IOException
* @throws InterruptedIOException
* @throws RetriesExhaustedWithDetailsException
*/
private static void putDatas() throws IOException, InterruptedIOException, RetriesExhaustedWithDetailsException {
// 1. 添加数据
// 1.1 获取表对象,对表进行各种操作:put/delete/get等等
HTable htable = new HTable(config, "teacher");
// 上传操作的对象
Put put = new Put("10004".getBytes());// rowkey
put.add("userinfo".getBytes(), "uname".getBytes(), "zhaoliu".getBytes());
put.add("userinfo".getBytes(), "uage".getBytes(), "10".getBytes());
put.add("userinfo".getBytes(), "utel".getBytes(), "111235346".getBytes());
put.add("userinfo".getBytes(), "ugender".getBytes(), "man".getBytes());
put.add("eduinfo".getBytes(), "ename".getBytes(), "beida".getBytes());
put.add("eduinfo".getBytes(), "eaddr".getBytes(), "beijing".getBytes());
put.add("workinfo".getBytes(), "wname".getBytes(), "baidu".getBytes());
put.add("workinfo".getBytes(), "waddr".getBytes(), "beijing".getBytes());
put.add("eclipse_add_info".getBytes(), "eclipse_version".getBytes(), "2.3.2".getBytes());
// 1.2执行put操作
htable.put(put);
System.out.println("put success!!");
}
}
| | 3. 比较器(comparator)
public class HBaseComparatorDemo {
public static void main(String[] args) throws Exception {
//方式一:用户自定义规则,使用正则表达式
// getDatas("teacher", "userinfo", "uname", "[A-Za-z]*");
//方式二:子字符串比较器,规则固定
// getDatas2("teacher", "userinfo", "uname", "si");
//zhangsan 、lisi、wangwu、zhaoliu
//select * from teacher where uname like "%ng%";
//方式三:二进制前串比较器,规则固定
getDatas3("teacher", "userinfo", "uname", "zha");
}
/**
* 使用正则比较器,实现数据的匹配和 过滤操作
*
* @param tbName
* @param columnFamily
* @param columnName
* @param regExpStr
* @throws Exception
*/
public static void getDatas3(String tbName, String columnFamily, String columnName, String regExpStr)
throws Exception {
// 1. 创建扫描器对象
Scan scan = new Scan();
/**
* 参数一:正则表达式
*/
// RegexStringComparator compara = new RegexStringComparator(regExpStr);
// SubstringComparator subCompara = new SubstringComparator(regExpStr);
BinaryPrefixComparator binaryPrefixCompara = new BinaryPrefixComparator(Bytes.toBytes(regExpStr));
/**
* 参数一:列族 参数二:列名 参数三:比较规则 参数四:比较器对象(正则表达式的比较器)
*/
Filter filter = new SingleColumnValueFilter(Bytes.toBytes(columnFamily), Bytes.toBytes(columnName),
CompareOp.EQUAL, binaryPrefixCompara);
// 2. 设置过滤器
scan.setFilter(filter);
// 3. 创建表对象
HTable hTable = new HTable(HBaseConfiguration.create(), tbName);
// 4. 扫描数据表
ResultScanner result = hTable.getScanner(scan);
// 5. 输出数据
for (Result result2 : result) {
for (KeyValue dataKV : result2.list()) {
// key:定位到cell的路径
if ("uname".equals(new String(dataKV.getQualifier()))) {
System.out.println("rowkey:" + new String(dataKV.getRow()));
System.out.println("columnFamily:" + new String(dataKV.getFamily()));
System.out.println("columnName:" + new String(dataKV.getQualifier()));
System.out.println("timestamp:" + new Date(dataKV.getTimestamp()));
System.out.println("timestamp:" + new String(dataKV.getValue()));
}
}
System.out.println("-----------------------------------");
}
}
/**
* 使用正则比较器,实现数据的匹配和 过滤操作
*
* @param tbName
* @param columnFamily
* @param columnName
* @param regExpStr
* @throws Exception
*/
public static void getDatas2(String tbName, String columnFamily, String columnName, String regExpStr)
throws Exception {
// 1. 创建扫描器对象
Scan scan = new Scan();
/**
* 参数一:正则表达式
*/
// RegexStringComparator compara = new RegexStringComparator(regExpStr);
SubstringComparator subCompara = new SubstringComparator(regExpStr);
/**
* 参数一:列族 参数二:列名 参数三:比较规则 参数四:比较器对象(正则表达式的比较器)
*/
Filter filter = new SingleColumnValueFilter(Bytes.toBytes(columnFamily), Bytes.toBytes(columnName),
CompareOp.EQUAL, subCompara);
// 2. 设置过滤器
scan.setFilter(filter);
// 3. 创建表对象
HTable hTable = new HTable(HBaseConfiguration.create(), tbName);
// 4. 扫描数据表
ResultScanner result = hTable.getScanner(scan);
// 5. 输出数据
for (Result result2 : result) {
for (KeyValue dataKV : result2.list()) {
// key:定位到cell的路径
if ("uname".equals(new String(dataKV.getQualifier()))) {
System.out.println("rowkey:" + new String(dataKV.getRow()));
System.out.println("columnFamily:" + new String(dataKV.getFamily()));
System.out.println("columnName:" + new String(dataKV.getQualifier()));
System.out.println("timestamp:" + new Date(dataKV.getTimestamp()));
System.out.println("timestamp:" + new String(dataKV.getValue()));
}
}
System.out.println("-----------------------------------");
}
}
/**
* 使用正则比较器,实现数据的匹配和 过滤操作
*
* @param tbName
* @param columnFamily
* @param columnName
* @param regExpStr
* @throws Exception
*/
public static void getDatas(String tbName, String columnFamily, String columnName, String regExpStr)
throws Exception {
// 1. 创建扫描器对象
Scan scan = new Scan();
/**
* 参数一:正则表达式
*/
RegexStringComparator compara = new RegexStringComparator(regExpStr);
/**
* 参数一:列族 参数二:列名 参数三:比较规则 参数四:比较器对象(正则表达式的比较器)
*/
Filter filter = new SingleColumnValueFilter(Bytes.toBytes(columnFamily), Bytes.toBytes(columnName),
CompareOp.EQUAL, compara);
// 2. 设置过滤器
scan.setFilter(filter);
// 3. 创建表对象
HTable hTable = new HTable(HBaseConfiguration.create(), tbName);
// 4. 扫描数据表
ResultScanner result = hTable.getScanner(scan);
// 5. 输出数据
for (Result result2 : result) {
for (KeyValue dataKV : result2.list()) {
// key:定位到cell的路径
// if ("uname".equals(new String(dataKV.getFamily()))) {
System.out.println("rowkey:" + new String(dataKV.getRow()));
System.out.println("columnFamily:" + new String(dataKV.getFamily()));
System.out.println("columnName:" + new String(dataKV.getQualifier()));
System.out.println("timestamp:" + new Date(dataKV.getTimestamp()));
System.out.println("timestamp:" + new String(dataKV.getValue()));
// }
}
System.out.println("-----------------------------------");
}
}
}
4.过滤器(filter)
public class HBaseFilterDemo {
public static void main(String[] args) throws Exception {
// getDatas1("teacher", "userinfo", "uname", "lisi");
// getDatas2("teacher", "userinfo");// 过滤列族
// getDatas4("teacher", "uage");// 过滤列名
getDatas5("teacher", "w");// 过滤列名 workinfo列族
}
/**
* 列名前缀过滤器
* 匹配类名:以指定的字符串开头
*
* @param tbName
* @param columnFamilyName
* @param columnName
* @param exp
* @throws Exception
*/
public static void getDatas5(String tbName, String exp) throws Exception {
// 1. 创建扫描器对象
Scan scan = new Scan();
ColumnPrefixFilter filter = new ColumnPrefixFilter(Bytes.toBytes(exp));
// 2. 设置过滤器
scan.setFilter(filter);
// 3. 创建表对象
HTable hTable = new HTable(HBaseConfiguration.create(), tbName);
// 4. 扫描数据表
ResultScanner result = hTable.getScanner(scan);
// 5. 输出数据
for (Result result2 : result) {
for (KeyValue dataKV : result2.list()) {
// if ("uname".equals(new String(dataKV.getQualifier()))) {
System.out.println("rowkey:" + new String(dataKV.getRow()));
System.out.println("columnFamily:" + new String(dataKV.getFamily()));
System.out.println("columnName:" + new String(dataKV.getQualifier()));
System.out.println("timestamp:" + new Date(dataKV.getTimestamp()));
System.out.println("timestamp:" + new String(dataKV.getValue()));
// }
}
System.out.println("-----------------------------------");
}
}
/**
* 列名过滤器
*
* @param tbName
* @param columnFamilyName
* @param columnName
* @param exp
* @throws Exception
*/
public static void getDatas4(String tbName, String exp) throws Exception {
// 1. 创建扫描器对象
Scan scan = new Scan();
QualifierFilter filter = new QualifierFilter(CompareOp.EQUAL, new BinaryComparator(Bytes.toBytes(exp)));
// 2. 设置过滤器
scan.setFilter(filter);
// 3. 创建表对象
HTable hTable = new HTable(HBaseConfiguration.create(), tbName);
// 4. 扫描数据表
ResultScanner result = hTable.getScanner(scan);
// 5. 输出数据
for (Result result2 : result) {
for (KeyValue dataKV : result2.list()) {
// if ("uname".equals(new String(dataKV.getQualifier()))) {
System.out.println("rowkey:" + new String(dataKV.getRow()));
System.out.println("columnFamily:" + new String(dataKV.getFamily()));
System.out.println("columnName:" + new String(dataKV.getQualifier()));
System.out.println("timestamp:" + new Date(dataKV.getTimestamp()));
System.out.println("timestamp:" + new String(dataKV.getValue()));
// }
}
System.out.println("-----------------------------------");
}
}
/**
* 列族过滤器
*
* @param tbName
* @param columnFamilyName
* @param columnName
* @param exp
* @throws Exception
*/
public static void getDatas3(String tbName, String exp) throws Exception {
// 1. 创建扫描器对象
Scan scan = new Scan();
FamilyFilter filter = new FamilyFilter(CompareOp.EQUAL, new BinaryComparator(Bytes.toBytes(exp)));
// 2. 设置过滤器
scan.setFilter(filter);
// 3. 创建表对象
HTable hTable = new HTable(HBaseConfiguration.create(), tbName);
// 4. 扫描数据表
ResultScanner result = hTable.getScanner(scan);
// 5. 输出数据
for (Result result2 : result) {
for (KeyValue dataKV : result2.list()) {
// if ("uname".equals(new String(dataKV.getQualifier()))) {
System.out.println("rowkey:" + new String(dataKV.getRow()));
System.out.println("columnFamily:" + new String(dataKV.getFamily()));
System.out.println("columnName:" + new String(dataKV.getQualifier()));
System.out.println("timestamp:" + new Date(dataKV.getTimestamp()));
System.out.println("timestamp:" + new String(dataKV.getValue()));
// }
}
System.out.println("-----------------------------------");
}
}
/**
* 列值过滤器
*
* @param tbName
* @param columnFamilyName
* @param columnName
* @param exp
* @throws Exception
*/
public static void getDatas2(String tbName, String exp) throws Exception {
// 1. 创建扫描器对象
Scan scan = new Scan();
// 全匹配:exp == data
// Filter filter = new
// SingleColumnValueFilter(Bytes.toBytes(columnFamilyName),
// Bytes.toBytes(columnName),
// CompareOp.NOT_EQUAL, Bytes.toBytes(exp));
/**
* 键值过滤器 : 过滤列族 键值:columnFamily
*
* 参数一:比较的规则:小于,大于... ... 参数二:具体比较参数,columnFamily
*/
Filter filter = new ValueFilter(CompareOp.NOT_EQUAL, new BinaryComparator(Bytes.toBytes(exp)));
// 2. 设置过滤器
scan.setFilter(filter);
// 3. 创建表对象
HTable hTable = new HTable(HBaseConfiguration.create(), tbName);
// 4. 扫描数据表
ResultScanner result = hTable.getScanner(scan);
// 5. 输出数据
for (Result result2 : result) {
for (KeyValue dataKV : result2.list()) {
if ("uname".equals(new String(dataKV.getQualifier()))) {
System.out.println("rowkey:" + new String(dataKV.getRow()));
System.out.println("columnFamily:" + new String(dataKV.getFamily()));
System.out.println("columnName:" + new String(dataKV.getQualifier()));
System.out.println("timestamp:" + new Date(dataKV.getTimestamp()));
System.out.println("timestamp:" + new String(dataKV.getValue()));
}
}
System.out.println("-----------------------------------");
}
}
/**
* 列值过滤器
*
* @param tbName
* @param columnFamilyName
* @param columnName
* @param exp
* @throws Exception
*/
public static void getDatas1(String tbName, String columnFamilyName, String columnName, String exp)
throws Exception {
// 1. 创建扫描器对象
Scan scan = new Scan();
// 全匹配:exp == data
Filter filter = new SingleColumnValueFilter(Bytes.toBytes(columnFamilyName), Bytes.toBytes(columnName),
CompareOp.NOT_EQUAL, Bytes.toBytes(exp));
// 2. 设置过滤器
scan.setFilter(filter);
// 3. 创建表对象
HTable hTable = new HTable(HBaseConfiguration.create(), tbName);
// 4. 扫描数据表
ResultScanner result = hTable.getScanner(scan);
// 5. 输出数据
for (Result result2 : result) {
for (KeyValue dataKV : result2.list()) {
if ("uname".equals(new String(dataKV.getQualifier()))) {
System.out.println("rowkey:" + new String(dataKV.getRow()));
System.out.println("columnFamily:" + new String(dataKV.getFamily()));
System.out.println("columnName:" + new String(dataKV.getQualifier()));
System.out.println("timestamp:" + new Date(dataKV.getTimestamp()));
System.out.println("timestamp:" + new String(dataKV.getValue()));
}
}
System.out.println("-----------------------------------");
}
}
}
5. HBase作为输入源
main
/**
*
* @author zkpk
*
* HBase 作为输入源,从HBase表中读取数据,使用MapReduce计算完成之后,将数据存储到HDFS中
*
*/
public class Main {
static final Log LOG = LogFactory.getLog(Main.class);
//JobName
public static final String NAME = "Member Test1";
//HDFS system file
public static final String TEMP_INDEX_PATH = "/tmp/member_user";
//HBase作为输入源的HBase中的表 member_user
public static String inputTable = "member_user";
/**
* @param args
*/
public static void main(String[] args)throws Exception {
//1.获得HBase的配置信息
Configuration conf = HBaseConfiguration.create();
//conf = new Configuration();
//2.创建全表扫描器scan对象
Scan scan = new Scan();
scan.setBatch(0);
scan.setCaching(10000);
scan.setMaxVersions();
scan.setTimeRange(System.currentTimeMillis() - 3*24*3600*1000L, System.currentTimeMillis());
//3.配置scan,添加扫描的条件,列族和列族名
scan.addColumn(Bytes.toBytes("info"), Bytes.toBytes("age"));
//4.设置hadoop的推测执行为fasle
conf.setBoolean("mapred.map.tasks.speculative.execution", false);
conf.setBoolean("mapred.reduce.tasks.speculative.execution", false);
//5.设置HDFS的存储HBase表中数据的路径
Path tmpIndexPath = new Path(TEMP_INDEX_PATH);
FileSystem fs = FileSystem.get(conf);
//判断该路径是否存在,如果存在则首先进行删除
if(fs.exists(tmpIndexPath)){
fs.delete(tmpIndexPath,true);
}
//6.创建job对象
Job job = new Job(conf,NAME);
//设置执行JOB的类
job.setJarByClass(Main.class);
//job.setMapperClass(MemberMapper.class);
//设置TableMapper类的相关信息,即对MemberMapper类的初始化设置
//(hbase输入源对应的表, 扫描器, 负责整个计算的逻辑,输出key的类型,输出value的类型,job )
//TableMapReduceUtil.initTableMapperJob(table, scan, mapper, outputKeyClass, outputValueClass, job);
TableMapReduceUtil.initTableMapperJob(inputTable, scan, MemberMapper.class, Text.class, Text.class, job);
//设置作业的Reduce任务个数为0
job.setNumReduceTasks(0);
//设置从HBase表中经过MapReduece计算后的结果以文本的格式输出
job.setOutputFormatClass(TextOutputFormat.class);
//设置作业输出结果保存到HDFS的文件路径
FileOutputFormat.setOutputPath(job, tmpIndexPath);
//开始运行作业
boolean success = job.waitForCompletion(true);
System.exit(success?0:1);
}
}
mapper
/**
*
* @author zkpk
*
* HBase 中的表 作为 输入源
* 扩展自Mapper类,所有以HBase作为输入源的Mapper类需要继承该类
*/
public class MemberMapper extends TableMapper{
private Text k = new Text();
private Text v = new Text();
public static final String FIELD_COMMON_SEPARATOR="\u0001";
@Override
protected void setup(Context context) throws IOException ,InterruptedException {
}
@Override
public void map(ImmutableBytesWritable row, Result columns,
Context context) throws IOException ,InterruptedException {
String value = null;
//获得行键值
String rowkey = new String(row.get());
//一行中的所有 列族
byte[] columnFamily = null;
//一行中的所有列名
byte[] columnQualifier = null;
long ts = 0L;
try{
//遍历一行中的所有列
for(KeyValue kv : columns.list()){
//单元格的值
value = Bytes.toStringBinary(kv.getValue()); // 25
//获得一行中的所有列族
columnFamily = kv.getFamily(); //info
//获得一行中的所有列名
columnQualifier = kv.getQualifier();
//获取单元格的时间戳
ts = kv.getTimestamp();
if("25".equals(value)){
k.set(rowkey);
v.set(Bytes.toString(columnFamily)+FIELD_COMMON_SEPARATOR+Bytes.toString(columnQualifier)
+FIELD_COMMON_SEPARATOR+value+FIELD_COMMON_SEPARATOR+ts);
context.write(k, v);
break;
}
}
}catch(Exception e){
e.printStackTrace();
System.err.println("Error:"+e.getMessage()+",Row:"+Bytes.toString(row.get())+",Value"+value);
}
};
}
6. 作为输出源
/**
*
* HBase作为输出源
* 将HDFS上的数据经过Mapreduce计算然后输出到HBase数据库中
* @author zkpk
*
*/
public class Main extends Configured implements Tool{
static final Log LOG = LogFactory.getLog(Main.class);
@Override
public int run(String[] args) throws Exception {
if(args.length !=3){
LOG.info("Usage: 3 parameters needed!");
System.exit(1);
}
//输入源HDFS文件的存储路径
String path = args[0]; //
//输出到HBase中的表名
String input = args[1]; //HDFS文件系统中数据的路径
String table = args[2]; //HBase中的表
//获得HBase的配置信息
Configuration conf = HBaseConfiguration.create();
//创建作业
Job job = new Job(conf, "Input from file"+input+" into table"+table);
job.setJarByClass(Main.class);
job.setMapperClass(MemberMapper.class);
//设置作业的完成后的输出结果类型为一个表
job.setOutputFormatClass(TableOutputFormat.class);
//设置job完成后结果输出到表的名
job.getConfiguration().set(TableOutputFormat.OUTPUT_TABLE, table);
//设置输出到表的Map key和value的 类型
job.setOutputKeyClass(ImmutableBytesWritable.class);
job.setOutputValueClass(Writable.class);
job.setNumReduceTasks(0);
//设置hdfs作为输入源文件的路径
FileInputFormat.addInputPath(job, new Path(input));
//开启作业
return job.waitForCompletion(true)?0:1;
}
/**
* @param args
*/
public static void main(String[] args)throws Exception {
//1.获得HDFS的配置信息
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
for(int i=0;iMR计算
/**
*
* HBase作为输出源
* 将HDFS上的数据经过Mapreduce计算然后输出到HBase数据库中
* @author zkpk
*
*/
public class MemberMapper extends Mapper {
//定义列族
private byte[] family = null;
//定义列名
private byte[] qualifier = null;
//定义单元格存放的值
private byte[] val = null;
//定义行键
private String rowkey = null;
//定义时间戳
private long ts = System.currentTimeMillis();
protected void map(LongWritable key, Text value, Context context) throws java.io.IOException ,InterruptedException {
try{
String lineString = value.toString();
String[] arr = lineString.split("\t",-1);
if(arr.length==2){
//给行键进行赋值
rowkey = arr[0];
String[] vals = arr[1].split("\u0001", -1);
if(vals.length==4){
family = vals[0].getBytes();
qualifier = vals[1].getBytes();
val = vals[2].getBytes();
ts = Long.parseLong(vals[3]);
Put put = new Put(rowkey.getBytes(),ts);
put.add(family, qualifier, val);
context.write(new ImmutableBytesWritable(rowkey.getBytes()), put);
}
}
}catch(Exception e){
e.printStackTrace();
}
};
}
注意:
HBase作为输出源的时候,在打包的时候一定要把lib下面的包一起打上,否则,会报错误!!
事先要创建好 member_part2表
hadoop jar HBaseOutputSourceTest.jar XXX /user/zkpk/part2 member_part2
yarn.application.classpath
7. 作为共享源
/**
* HBase作为共享源
* 将HBase中一张表的统计结果输出到HBase的另一张表中。
* @author zkpk
*
*/
public class Main {
static final Log Log = LogFactory.getLog(Main.class);
public static final String NAME = "Example Test";
public static final String inputTable = "member";
public static final String outputTable = "member-stat";
public static final String TMP_INDEX_PATH = "/tmp/member2";
/**
* @param args
*/
public static void main(String[] args)throws Exception {
Configuration conf = HBaseConfiguration.create();
Scan scan = new Scan();
scan.addColumn(Bytes.toBytes("info"), Bytes.toBytes("age"));
conf.setBoolean("mapred.map.tasks.speculative.execution", false);
conf.setBoolean("mapred.reduce.tasks.speculative.execution", false);
Path tmpIndexPath = new Path(TMP_INDEX_PATH);
FileSystem fs = FileSystem.get(conf);
if(fs.exists(tmpIndexPath)){
fs.delete(tmpIndexPath, true);
}
Job job = new Job(conf, NAME);
job.setJarByClass(Main.class);
job.setMapperClass(com.mr.publicsource.MemberMapper.class);
//从HBase中读取数据,并
TableMapReduceUtil.initTableMapperJob(inputTable, scan, MemberMapper.class, Text.class, Text.class, job);
TableMapReduceUtil.initTableReducerJob(outputTable, IdentityTableReducer.class, job);
int success = job.waitForCompletion(true)?0:1;
System.exit(success);
}
}
Mapper
public class MemberMapper extends Mapper {
//定义列族
private byte[] family = null;
//定义列名
private byte[] qualifier = null;
//定义单元格存放的值
private byte[] val = null;
//定义行键
private String rowkey = null;
//定义时间戳
private long ts = System.currentTimeMillis();
protected void map(LongWritable key, Text value, Context context) throws java.io.IOException ,InterruptedException {
try{
String lineString = value.toString();
String[] arr = lineString.split("\t",-1);
if(arr.length==2){
//给行键进行赋值
rowkey = arr[0];
String[] vals = arr[1].split("\u0001", -1);
if(vals.length==4){
family = vals[0].getBytes();
qualifier = vals[1].getBytes();
val = vals[2].getBytes();
ts = Long.parseLong(vals[3]);
Put put = new Put(rowkey.getBytes(), ts);
put.add(family, qualifier, val);
context.write(new ImmutableBytesWritable(rowkey.getBytes()), put);
}
}
}catch(Exception e){
e.printStackTrace();
}
};
}





