Hbase入门
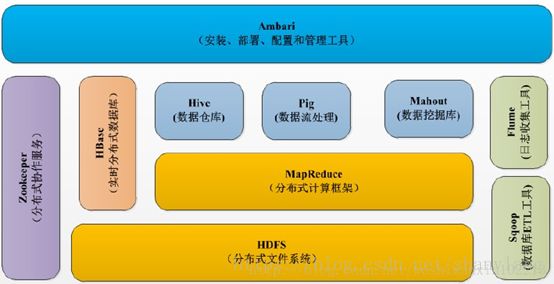
Hadoop1.0时代的生态系统如下:
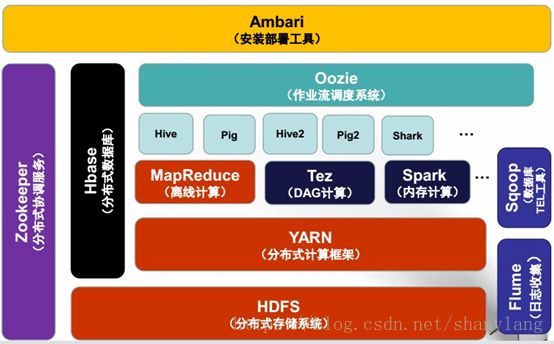
Hadoop2.0时代的生态系统如下:
1. HBase简介
– HBase – Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩、
实时读写的分布式数据库
– 利用Hadoop HDFS作为其文件存储系统,利用Hadoop MapReduce来处理
HBase中的海量数据,利用Zookeeper作为其分布式协同服务
– 主要用来存储非结构化和半结构化的松散数据(列存 NoSQL 数据库)
2. HBase数据模型
l Hbase什么都能存储,但在数据库中存储的都是字节数组(字节数据)。
l Hbase没有更新操作,通过数据戳来进行更新记录版本
Row Key |
Time Stamp |
CF1 |
CF2 |
CF3 |
"com.cnn.www" |
t6 |
|
CF2:q1=val3 |
CF3:q4=val4 |
t5 |
|
|
|
|
t3 |
CF1:q2=val2 |
|
|
2.1. ROW KEY
– 决定一行数据
– 按照字典顺序排序的。
– Row key只能存储64k的字节数据
2.2. Column Family列族 & qualifier列
– HBase表中的每个列都归属于某个列族,列族必须作为表模式(schema)定义的一部分预先给出。如 create ‘test’, ‘course’;
– 列名以列族作为前缀,每个“列族”都可以有多个列成员(column);如course:math,course:english, 新的列族成员(列)可以随后按需、动态加入;
– 权限控制、存储以及调优都是在列族层面进行的;
– HBase把同一列族里面的数据存储在同一目录下,由几个文件保存。
2.3. Timestamp时间戳
– 在HBase每个cell存储单元对同一份数据有多个版本,根据唯一的时间戳来区分每个版本之间的差异,不同版本的数据按照时间倒序排序,最新的数据版本排在最前面。
– 时间戳的类型是 64位整型。
– 时间戳可以由HBase(在数据写入时自动)赋值,此时时间戳是精确到毫秒的当前系统时间。
– 时间戳也可以由客户显式赋值,如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。
2.4. Cell单元格
– 由行和列的坐标交叉决定;
– 单元格是有版本的;
– 单元格的内容是未解析的字节数组;
• 由 {row key, column( =
2.5. HLog(WAL log)
– HLog文件就是一个普通的Hadoop Sequence File,Sequence File 的Key是
HLogKey对象,HLogKey中记录了写入数据的归属信息,除了table和
region名字外,同时还包括 sequence number和timestamp,timestamp是”
写入时间”,sequence number的起始值为0,或者是最近一次存入文件系
统中sequence number。
– HLog SequeceFile的Value是HBase的KeyValue对象,即对应HFile中的
KeyValue。
3. HBase体系架构
3.1. HBase体系架构
– Client
•包含访问HBase的接口并维护cache来加快对HBase的访问
– Zookeeper
•保证任何时候,集群中只有一个master(工作状态的)
•存贮所有Region的寻址入口。
•实时监控Region server的上线和下线信息。并实时通知Master
•存储HBase的schema和table元数据
– Master
•为Region server分配region
•负责Region server的负载均衡
•发现失效的Region server并重新分配其上的region
•管理用户对table的增删改操作
– RegionServer
• Region server维护region,处理对这些region的IO请求
• Region server负责切分在运行过程中变得过大的region
3.2. Hbase存储模型
Region
– HBase自动把表水平划分成多个区域(region),每个region会保存一个表
里面某段连续的数据;每个表一开始只有一个region,随着数据不断插
入表,region不断增大,当增大到一个阀值的时候,region就会等分会
两个新的region(裂变);
–当table中的行不断增多,就会有越来越多的region。这样一张完整的表
被保存在多个Regionserver 上。
3.3. HBase数据模型
Memstore 与 storefile
–一个region由多个store组成,一个store对应一个CF(列族)
– store包括位于内存中的memstore和位于磁盘的storefile写操作先写入memstore,当memstore中的数据达到某个阈值,hregionserver会启动flashcache进程写入storefile,每次写入形成单独的一个storefile
–当storefile文件的数量增长到一定阈值后,系统会进行合并(minor、majorcompaction),在合并过程中会进行版本合并和删除工作(majar),形成更大的storefile
–当一个region所有storefile的大小和数量超过一定阈值后,会把当前的region分割为两个(等分分割),并由hmaster分配到相应的regionserver服务器,实现负载均衡
–客户端检索数据,先在memstore找,找不到再找storefile
– HRegion是HBase中分布式存储和负载均衡的最小单元。最小单元就表示不同的HRegion可以分布在不同的 HRegion server上。
– HRegion由一个或者多个Store组成,每个store保存一个columns family。
–每个Strore又由一个memStore和0至多个StoreFile组成。如图:StoreFile以HFile格式保存在HDFS上。
4. Hbase集群安装
4.1. standalone
1.hbase-env.sh中配置JAVA_HOME,是否启用hbase自带的zookeeper
export JAVA_HOME=/usr/java/jdk1.8.0_162/ export HBASE_CLASSPATH=/usr/hbase/hbase-1.3.1/conf #启动hbase自动的zookeeper export HBASE_MANAGES_ZK=true |
2.配置hbase-site.xml如下
|
3. 配置hbase环境变量
#编辑/etc/profile
vi /etc/profile #添加如下内容 export HBASE_HOME=/usr/hbase/hbase-1.3.1/ export PATH=$JAVA_HOME/bin:$HBASE_HOME/bin:$PATH #保存使环境变量立即生效 source /etc/profile |
4.2. Hbase集群安装
|
Zookeeper |
Hbase-master |
Hbase-RegionServer |
Hadoop |
node1(192.168.60.155) |
1 |
1 |
1 |
1 |
Node2(192.168.60.156) |
1 |
|
1 |
1 |
Node3(192.168.60.157) |
1 |
|
1 |
1(master) |
Node4(192.168.60.158) |
|
1 |
|
|
4.2.1. 前提
4.2.1.1. 静态ip配置
4.2.1.1.1. 修改vim/etc/sysconfig/network-scripts/ifcfg-ens33配置文件
修改BOOTPROTO="static"为静态
删除UUID项
添加以下内容:
IPADDR=192.168.60.158
NETMASK=255.255.255.0
GATEWAY=192.168.60.2
ZONE=public
TYPE="Ethernet" PROXY_METHOD="none" BROWSER_ONLY="no" BOOTPROTO="static" DEFROUTE="yes" IPV4_FAILURE_FATAL="no" IPV6INIT="yes" IPV6_AUTOCONF="yes" IPV6_DEFROUTE="yes" IPV6_FAILURE_FATAL="no" IPV6_ADDR_GEN_MODE="stable-privacy" NAME="ens33" DEVICE="ens33" ONBOOT="yes" IPADDR=192.168.60.158 NETMASK=255.255.255.0 GATEWAY=192.168.60.2 ZONE=public |
4.2.1.1.2. 重启网关
命令:service network restart
Centos 7 启动网络服务,命令:systemctlstart network.service或systemctl start network
4.2.1.2. 修改域名设置
4.2.1.2.1. Centos7下修改方式:
第一步:修改/etc/sysconfig/network文件
#>vi /etc/sysconfig/network
添加或修改:
NETWORKING=yes
HOSTNAME= node1
第二步:修改/etc/hosts文件
#>vi /etc/hosts
修改 127.0.0.1这行中的localhost.localdomain为 node1
修改 ::1这行中的localhost.localdomain为node1:
添加对应ip的对应hostname
127.0.0.1 localhost node1 localhost4 localhost4.localdomain4 ::1 localhost node1 localhost6 localhost6.localdomain6 192.168.60.155 node1 192.168.60.156 node2 192.168.60.157 node3 192.168.60.158 node4 |
第三步 :修改vi /etc/hostname文件(此步不操作,怎么修改都没有用)
删除文件中的所有文字,在第一行添加node1
第四步:重启并验证
#>reboot -f
#> hostnamectl
4.2.1.3. 防火墙及端口号设置
4.2.1.3.1. 系统防火墙开启、关闭、状态查看
- /bin/systemctl status firewalld.service #查看防火墙状态,看第三行Active:inactive(dead)关闭,inactive(running)为开启
关闭状态下的:
开启状态下的:
- /bin/systemctl stop firewalld.service #关闭防火墙
- /bin/systemctl start firewalld.service #开启防火墙
重启防火墙
- firewall-cmd --reload #重启firewall
- systemctl stop firewalld.service #停止firewall
- systemctl disable firewalld.service #禁止firewall开机启动
- firewall-cmd --state #查看默认防火墙状态(关闭后显示notrunning,开启后显示running)
4.2.1.3.2. 配置防火墙开放端口,
查看已经开放的端口:firewall-cmd --list-ports
1.文件开启端口
编辑/etc/sysconfig/iptables,添加配置项(开放的是8080端口):
-A INPUT -m state –state NEW -m tcp -p tcp--dport 8080 -j ACCEPT
2.命令开启端口
firewall-cmd --zone=public--add-port=80/tcp --permanent
命令含义:
–zone #作用域
–add-port=80/tcp #添加端口,格式为:端口/通讯协议
–permanent #永久生效,没有此参数重启后失效
4.2.1.4. SSH免密码登录
参考文档:https://blog.csdn.net/a237428367/article/details/50464153
serverA 服务器的 usera 用户免密码登录 serverB 服务器的 userb用户。
4.2.1.4.1. 先使用usera 登录 serverA 服务器
[root@serverA ~]# su - usera
[usera@serverA ~]$ pwd
/home/usera
4.2.1.4.2. 在serverA上生成密钥对
[root@node4 java]# ssh-keygen-t rsa
Generating public/private rsakey pair.
Enter file in which to savethe key (/root/.ssh/id_rsa):
/root/.ssh/id_rsa already exists.
Overwrite (y/n)? y
Enter passphrase (empty for nopassphrase):
Enter same passphrase again:
Your identification has beensaved in /root/.ssh/id_rsa.
Your public key has been savedin /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:4uEer73KAuBqZkwEZ5yqSZIInOCqBoIZJZXc1EPvt5croot@node4
The key's randomart image is:
+---[RSA 2048]----+
|=++=.o. |
|+=B . o. |
|=* .. |
|O= . |
|%o o S . |
|*o. o o . . . |
|=. . + .E |
|o= .o + . |
|+ .=o+. |
+----[SHA256]-----+
此时会在/home/usera/.ssh目录下生成密钥对
[root@node4 java]# cd ~/.ssh
[root@node4 .ssh]# ll
总用量 16
-rw-------. 1 root root 2859 4月 7 00:49 authorized_keys
-rw-------. 1 root root 1679 4月 7 23:45 id_rsa
-rw-r--r--. 1 root root 392 4月 7 23:45 id_rsa.pub
-rw-r--r--. 1 root root 528 4月 7 23:49 known_hosts
4.2.1.4.3. 将公钥上传到serverB 服务器,并以userb用户登录
方式一:用ssh-copy-id命令
[root@node4 .ssh] ssh-copy-idroot@192.168.60.155
/usr/bin/ssh-copy-id: INFO:Source of key(s) to be installed: "/root/.ssh/id_rsa.
The authenticity of host'192.168.60.155 (192.168.60.155)' can't be established.
ECDSA key fingerprint is SHA256:Ls45fTLhlQFrtJUyfjJE5715h+859dFz8Vp6wzm2eMQ.
ECDSA key fingerprint isMD5:1f:09:16:01:67:63:57:12:68:79:0a:e6:07:e2:5c:5d.
Are you sure you want tocontinue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO:attempting to log in with the new key(s), to filter oat are already installed
/usr/bin/ssh-copy-id: INFO: 1key(s) remain to be installed -- if you are prompteis to install the new keys
[email protected]'spassword:
Number of key(s) added: 1
Now try logging into themachine, with: "ssh '[email protected]'"
and check to make sure thatonly the key(s) you wanted were added.
这个时候usera的公钥文件内容会追加写入到userb的 .ssh/authorized_keys 文件中
[root@node4 .ssh]# cd ~/
[root@node4 ~]# cat .ssh/id_rsa.pub
ssh-rsaAAAAB3NzaC1yc2EAAAADAQABAAABAQCuD/JnHW0dBPrPFxmx5aYPGDwmRNx6lkGjU623XWuCdTc5X1U2H8YfApoArUIe3RlwQl4ajOeXrdbWHcMB1Q/rprkgr9IxHpWYRnRTgBZUCMS1XLiWzxW2pgJUmWCOCv/llNeD9kPL3+F9oYob1acQHCuC4d/iThxwR+bk2Q081hZFe6qnR37jTNUKgj+kFh+LlLnki3YGqvBtLEcJ5VR+EORzdCWR8frB5pgr7GRQ537A1Rp3SqzOa7uE7l1yXC0/gMJAtvsQGDf9clhIzxV8Id/HDW6svYsiGkcGPb2730uyNdssFr/ZdO5Mr48DFrjiXDZFlfT+ekbbGnsYteHbroot@node4
查看serverB服务器userb用户下的 ~/.ssh/authorized_keys文件,内容是一样的。
[root@node1 ~]# cat.ssh/authorized_keys
ssh-rsaAAAAB3NzaC1yc2EAAAADAQABAAABAQCuD/JnHW0dBPrPFxmx5aYPGDwmRNx6lkGjU623XWuCdTc5X1U2H8YfApoArUIe3RlwQl4ajOeXrdbWHcMB1Q/rprkgr9IxHpWYRnRTgBZUCMS1XLiWzxW2pgJUmWCOCv/llNeD9kPL3+F9oYob1acQHCuC4d/iThxwR+bk2Q081hZFe6qnR37jTNUKgj+kFh+LlLnki3YGqvBtLEcJ5VR+EORzdCWR8frB5pgr7GRQ537A1Rp3SqzOa7uE7l1yXC0/gMJAtvsQGDf9clhIzxV8Id/HDW6svYsiGkcGPb2730uyNdssFr/ZdO5Mr48DFrjiXDZFlfT+ekbbGnsYteHbroot@node4
方式二:用scp命令
1,将公钥id_rsa.pub上传到服务器(192.168.60.155)端
scp ~/.ssh/id_rsa.pub [email protected]:~/
2,将公钥追加到~/.ssh/authorized_keys文件中
cat id_rsa.pub >>authorized_keys
3.将公钥文件authorized_keysscp传回到client端serverA上.
scp ~/.ssh/[email protected]:~/.ssh
4.2.1.4.4. ssh目录和.ssh/authorized_keys文件赋权限
如果希望ssh公钥生效需满足至少下面两个条件:
1) .ssh目录的权限必须是700
2) .ssh/authorized_keys文件权限必须是600
[root@node1 ~]# cd .ssh
[root@node1 .ssh]# ll
总用量 4
-rw-------. 1 root root 392 4月 8 07:49 authorized_keys
权限不够,分配权限,777为最大权限
[root@node1 .ssh]# chmod 777 authorized_keys
[root@node1 .ssh]# ll
总用量 4
-rwxrwxrwx. 1 root root 392 4月 8 07:49 authorized_keys
这样就可以免密码登录了:
[root@node4 ~]# ssh 192.168.60.156 登录
Last login: Sun Apr 8 18:25:12 2018 from 192.168.60.154
[root@node2 ~]# exit 退出
登出
Connection to 192.168.60.156closed.
[root@node4 ~]#
注意:
另外,将公钥拷贝到服务器的~/.ssh/authorized_keys文件中方法有如下几种:
1、将公钥通过scp拷贝到服务器上(scp~/.ssh/id_rsa.pub user@host:~/),然后catid_rsa.pub >> authorized_keys追加到~/.ssh/authorized_keys文件中,再将公钥文件传回到client端(scp ~/.ssh/authorized_keys [email protected]:~/.ssh),然后再赋权限即可免密码登录。
2、通过ssh-copy-id程序,执行命令ssh-copy-iduser@host即可(在centos7上生效)
3、可以通过cat ~/.ssh/id_rsa.pub | ssh -p 22 user@host ‘cat >> ~/.ssh/authorized_keys’,这个也是比较常用的方法,因为可以更改端口号。[A1]
4.2.1.5. 安装JDK
4.2.1.5.1. 检查一下系统中的jdk版本
[root@localhost software]#java -version
显示:
openjdk version "1.8.0_102" OpenJDK Runtime Environment (build 1.8.0_102-b14) OpenJDK 64-Bit Server VM (build 25.102-b14, mixed mode) |
4.2.1.5.2. 检测jdk安装包
[root@localhost software]# rpm-qa | grep java
显示:
java-1.7.0-openjdk-1.7.0.111-2.6.7.8.el7.x86_64 python-javapackages-3.4.1-11.el7.noarch tzdata-java-2016g-2.el7.noarch javapackages-tools-3.4.1-11.el7.noarch java-1.8.0-openjdk-1.8.0.102-4.b14.el7.x86_64 java-1.8.0-openjdk-headless-1.8.0.102-4.b14.el7.x86_64 java-1.7.0-openjdk-headless-1.7.0.111-2.6.7.8.el7.x86_64 |
4.2.1.5.3. 卸载openjdk
[root@localhost software]# rpm-e --nodeps tzdata-java-2016g-2.el7.noarch
[root@localhost software]# rpm-e --nodeps java-1.7.0-openjdk-1.7.0.111-2.6.7.8.el7.x86_64
[root@localhost software]# rpm-e --nodeps java-1.7.0-openjdk-headless-1.7.0.111-2.6.7.8.el7.x86_64
[root@localhost software]# rpm-e --nodeps java-1.8.0-openjdk-1.8.0.102-4.b14.el7.x86_64
[root@localhost software]# rpm-e --nodeps java-1.8.0-openjdk-headless-1.8.0.102-4.b14.el7.x86_64
或者使用
[root@localhost jvm]# yumremove *openjdk*
之后再次输入rpm -qa | grep java 查看卸载情况:
[root@localhost software]# rpm-qa | grep java
python-javapackages-3.4.1-11.el7.noarch
javapackages-tools-3.4.1-11.el7.noarch
4.2.1.5.4. 安装新的jdk
首先到jdk官网上下载你想要的jdk版本,下载完成之后将需要安装的jdk安装包放到Linux系统指定的文件夹下,并且命令进入该文件夹下:
[root@localhost software]# ll
total 252664
-rw-r--r--. 1 root root 11830603 Jun 9 06:43 alibaba-rocketmq-3.2.6.tar.gz
-rw-r--r--. 1 root root 43399561 Jun 9 06:42 apache-activemq-5.11.1-bin.tar.gz
-rwxrw-rw-. 1 root root185540433 Apr 21 09:06 jdk-8u131-linux-x64.tar.gz
-rw-r--r--. 1 root root 1547695 Jun 9 06:44 redis-3.2.9.tar.gz
-rw-r--r--. 1 root root 16402010 Jun 9 06:40 zookeeper-3.4.5.tar.gz
解压 jdk-8u131-linux-x64.tar.gz安装包
[root@localhost software]#mkdir -p /usr/lib/jvm
[root@localhost software]# tar-zxvf jdk-8u131-linux-x64.tar.gz -C /usr/lib/jvm
4.2.1.5.5. 设置环境变量
[root@localhost software]# vim/etc/profile
在最前面添加:
exportJAVA_HOME=/usr/lib/jvm/jdk1.8.0_131
exportJRE_HOME=${JAVA_HOME}/jre
exportCLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
或者
JAVA_HOME=/opt/jdk1.8.0_65
JAVA_BIN=$JAVA_HOME/bin
JRE_HOME=$JAVA_HOME/jre
JRE_BIN=$JRE_HOME/bin
PATH=$JAVA_BIN:$JRE_BIN:$PATH
exportJAVA_HOME JRE_HOME PATH
4.2.1.5.6. 执行profile文件
[root@localhost software]#source /etc/profile
这样可以使配置不用重启即可立即生效。
4.2.1.5.7. 检查新安装的jdk
[root@localhost software]#java -version
显示:
java version"1.8.0_131"
Java(TM) SE RuntimeEnvironment (build 1.8.0_131-b11)
Java HotSpot(TM) 64-Bit ServerVM (build 25.131-b11, mixed mode)
4.2.1.5.8. 开机启动jdk
1.修改脚本文件rc.local: vim /etc/rc.d/rc.local
2.添加如下内容:
export JAVA_HOME=/opt/jdk1.8.0_65
/opt/tomcat包名/bin/startup.sh start
3.esc 退出编辑,:wq 保存修改
4.将rc.local修改为可执行
chmod 777 /etc/rc.d/rc.local
将本机的jdk-8u162-linux-x64.tar.gz上传到服务器node1的当前目录下: scp jdk-8u162-linux-x64.tar.gz node1:"pwd" 解压到当前目录或者其他目录(【–C 目录地址】) tar -zxvf jdk-8u162-linux-x64.tar.gz 【–C 目录地址】
|
4.2.2. 安装zookeeper
4.2.2.1. 特点
一致(每个节点的数据一致性)、有头(zookeeper有一个leader)、数据树(每个路径/节点都绑定了一个数据)
实现的是paxos算法,少于半数节点是不提供服务的。
l Zab协议和paxos算法保证了数据的一致性
l 一定用会有一个领导leader
l 每个节点路径都绑定一个数据
4.2.2.2. zookeeper投票算法
FastLeader算法
4.2.2.3. 分布式系统的CAP理论
l Consistency:一致性
l Availability:服务的可利用性(通知所有的人)
l Partition tolerance:服务的可扩展性(网络连用性)
只能三者得其二,不能得其三
Cbp(能力capability、美貌beauty、性格persionality)
4.2.2.4. 下载
zookeeper的下载安装不在说, 直接配置安装后的zookeeper。
参考:https://www.cnblogs.com/ahu-lichang/p/6723826.html
先配置一个后面的直接复制到其他服务器上就可以了。
注意:时间要求同步(查看时间date)、免密码登录
4.2.2.5. 前提条件
1. 设置节点机器配置/etc/host文件
添加以下内容
192.168.60.155 node1 192.168.60.156 node2 192.168.60.157 node3 |
其实此操作以在前面配置了,但是在单独安装zookeeper时需要注意
2. 设置节点机器的本机免密登录
配置方法上面有参考【4.2.1.4. SSH免密码登录】。要配置两两之间的免密登录
3. 关闭节点机器的防火墙或者开放相应的ip和端口。
参考【4.2.1.5防火墙及端口号设置】关闭防火墙。
4.2.2.6. 修改环境变量
在/etc/profile文件中配置环境变量
export ZOOKEEPER_HOME=/usr/zookeeper/zookeeper-3.4.6 export PATH=${ZOOKEEPER_HOME}/bin:${PATH} |
刷新环境变量
source /etc/profile
4.2.2.7. 修改配置文件zoo.cfg
/usr/zookeeper/zookeeper-3.4.6/conf/目录下复制zoo_sample.cfg为zoo.cfg再进行修改。
cd /usr/local/zookeeper/conf
cp zoo_sample.cfg zoo.cfg
vi zoo.cfg
添加以下内容:
dataDir=/usr/zookeeper/zookeeper-3.4.6/data
dataLogDir=/usr/zookeeper/zookeeper-3.4.6/log
#配置服务为ip,不要用hostname,否则启动会出现问题
server.1=192.168.60.155:2888:3888
server.2=192.168.60.156:2888:3888
server.3=192.168.60.157:2888:3888
4.2.2.8. 创建文件夹
mkdir /usr/zookeeper/zookeeper-3.4.6/data
mkdir /usr/zookeeper/zookeeper-3.4.6/log
在data文件夹中新建myid文件,myid文件的内容为1(一句话创建:echo 1 > myid)
vi data/myid
添加内容:1
4.2.2.9. 把zookeeper-3.4.6复制到其他node2和node3中
scp -r /usr/zookeeper/zookeeper-3.4.6node2:/usr/zookeeper/
scp -r /usr/zookeeper/zookeeper-3.4.6node3:/usr/zookeeper/
4.2.2.10. 将环境变量/etc/profile复制到其他node2和node3的 /etc/目录下
执行source /etc/profile,使环境配置立即有效。
修改node2和node3中myid中的值分别为2和3。
vi /usr/zookeeper/zookeeper-3.4.6/data/myid
4.2.2.11. 启动服务
依次启动node1,node2,node3。
cd /usr/zookeeper/zookeeper-3.4.6/bin
zkServer.sh start
/usr/zookeeper/zookeeper-3.4.6/bin/zkServer.shstart
4.2.2.12. 查看服务状态
jps查看进程,会出现进程QuorumPeerMain
刚启动的node1,node2会报错,但是没有事。
节点都启动完以后,zkServer.sh status查看zookeeper启动状态及MODE (可以看到MODE,谁是leader,谁是follower)
node1:follower
node2:leader
node3:follower
4.2.2.13. 客户端连接
./zkCli.sh -server node1:2181,连接成功如下
[root@node4 zookeeper]# cd zookeeper-3.4.6/bin/ [root@node4 bin]# ls README.txt zkCli.cmd zkEnv.cmd zkServer.cmd zookeeper.out zkCleanup.sh zkCli.sh zkEnv.sh zkServer.sh [root@node4 bin]# ./zkCli.sh -server node1:2181 Connecting to node1:2181 2018-04-11 22:15:18,781 [myid:] - INFO [main:Environment@100] - Client environment:zookeeper.version=3.4.6-1569965, built on 02/20/2014 09:09 GMT 2018-04-11 22:15:18,808 [myid:] - INFO [main:Environment@100] - Client environment:host.name=localhost …. [zk: node1:2181(CONNECTING) 0] 2018-04-11 22:15:20,765 [myid:] - INFO [main-SendThread(node1:2181):ClientCnxn$SendThread@1235] - Session establishment complete on server node1/192.168.60.155:2181, sessionid = 0x162b6ba3d820000, negotiated timeout = 30000
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
[zk: node1:2181(CONNECTED) 0] [zk: node1:2181(CONNECTED) 0] help ZooKeeper -server host:port cmd args stat path [watch] set path data [version] ls path [watch] delquota [-n|-b] path ls2 path [watch] setAcl path acl setquota -n|-b val path history redo cmdno printwatches on|off delete path [version] sync path listquota path rmr path get path [watch] create [-s] [-e] path data acl addauth scheme auth quit getAcl path close connect host:port [zk: node1:2181(CONNECTED) 1] |
4.2.2.14. 命令操作
[zk: node1:2181(CONNECTED) 1] create /app appinfo Created /app [zk: node1:2181(CONNECTED) 2] ls / [app, zookeeper, yarn-leader-election, hadoop-ha] [zk: node1:2181(CONNECTED) 6] get /app appinfo cZxid = 0x500000004 ctime = Thu Apr 12 06:21:54 CST 2018 mZxid = 0x500000004 mtime = Thu Apr 12 06:21:54 CST 2018 pZxid = 0x500000004 cversion = 0 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 7 numChildren = 0 [zk: node1:2181(CONNECTED) 10] set /app appinfo_again cZxid = 0x500000004 ctime = Thu Apr 12 06:21:54 CST 2018 mZxid = 0x500000006 mtime = Thu Apr 12 06:24:39 CST 2018 pZxid = 0x500000004 cversion = 0 dataVersion = 2 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 13 numChildren = 0 [zk: node1:2181(CONNECTED) 7]delete /app |
4.2.2.15. 应用场景
l 集群配置一致
l HA(HighAbility)高可用
l Pub/sub
l Naming service
l Load balance
l 分布式锁
l 。。。
4.2.2.16. Java开发
l 创建连接
l 创建监视器
l 注册到zk上
4.2.3. 安装Hadoop
Hadoop的下载安装不在说, 直接配置安装后的hadoop。
参考文档:https://www.linuxidc.com/Linux/2015-11/124800.htm
只在Master服务器解压,再复制到Slave服务器
4.2.3.1. 先配置Master服务器
(1)下载“hadoop-2.7.0.tar.gz”,放到/home/hadoop目录下
(2)解压,输入命令,tar -xzvfhadoop-2.7.0.tar.gz
(3)在/home/hadoop目录下创建数据存放的文件夹,tmp、hdfs、hdfs/data、hdfs/name
4.2.3.2. 配置core-site.xml
配置/home/hadoop/hadoop-2.7.0/etc/hadoop目录下的core-site.xml
4.2.3.3. 配置hdfs-site.xml
配置/home/hadoop/hadoop-2.7.0/etc/hadoop目录下的hdfs-site.xml
4.2.3.4. 配置mapred-site.xml
配置/home/hadoop/hadoop-2.7.0/etc/hadoop目录下的mapred-site.xml
4.2.3.5. 配置yarn-site.xml
配置/home/hadoop/hadoop-2.7.0/etc/hadoop目录下的yarn-site.xml
4.2.3.6. 配置hadoop-env.sh、yarn-env.sh的JAVA_HOME
配置/home/hadoop/hadoop-2.7.0/etc/hadoop目录下hadoop-env.sh、yarn-env.sh的JAVA_HOME,不设置的话,启动不了,
export JAVA_HOME=/usr/java/jdk1.8.0_162
4.2.3.7. 配置slaves
配置/home/hadoop/hadoop-2.7.0/etc/hadoop目录下的slaves,删除默认的localhost,增加2个从节点:
192.168.60.155
192.168.69.156
也可以配置为hostname:
node1
node2
4.2.3.8. 将配置好的Hadoop复制到各个节点对应位置上
将配置好的Hadoop复制到各个节点对应位置上,通过scp传送:
scp -r /usr/hadoop root@node1:/usr/
scp -r /usr/hadoop root@node2:/usr/
4.2.3.9. 启动hadoop
在Master服务器启动hadoop,从节点会自动启动,进入/home/hadoop/hadoop-2.7.0目录
(1)初始化,输入命令,bin目录下:./hdfs namenode -format
(2)全部启动sbin/start-all.sh,也可以分开sbin/start-dfs.sh、sbin/start-yarn.sh
启动成功
[root@node3 hadoop-2.7.5]# sbin/start-all.sh This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh Starting namenodes on [node3] node3: starting namenode, logging to /usr/hadoop/hadoop-2.7.5/logs/hadoop-root-namenode-node3.out node2: starting datanode, logging to /usr/hadoop/hadoop-2.7.5/logs/hadoop-root-datanode-node2.out node1: starting datanode, logging to /usr/hadoop/hadoop-2.7.5/logs/hadoop-root-datanode-node1.out Starting secondary namenodes [node3] node3: starting secondarynamenode, logging to /usr/hadoop/hadoop-2.7.5/logs/hadoop-root-secondarynamenode-node3.out starting yarn daemons starting resourcemanager, logging to /usr/hadoop/hadoop-2.7.5/logs/yarn-root-resourcemanager-node3.out node1: starting nodemanager, logging to /usr/hadoop/hadoop-2.7.5/logs/yarn-root-nodemanager-node1.out node2: starting nodemanager, logging to /usr/hadoop/hadoop-2.7.5/logs/yarn-root-nodemanager-node2.out [root@node3 hadoop-2.7.5]# |
(3)停止的话,输入命令,sbin/stop-all.sh
[root@node3 hadoop-2.7.5]# sbin/stop-all.sh This script is Deprecated. Instead use stop-dfs.sh and stop-yarn.sh Stopping namenodes on [node3] node3: stopping namenode node1: stopping datanode node2: stopping datanode Stopping secondary namenodes [node3] node3: stopping secondarynamenode stopping yarn daemons stopping resourcemanager node2: stopping nodemanager node1: stopping nodemanager node2: nodemanager did not stop gracefully after 5 seconds: killing with kill -9 node1: nodemanager did not stop gracefully after 5 seconds: killing with kill -9 no proxyserver to stop [root@node3 hadoop-2.7.5]# |
(4)输入命令,jps,可以看到相关信息
Hadoop集群启动成功: [root@node3 hadoop-2.7.5]# jps 35237 SecondaryNameNode 35049 NameNode 35388 ResourceManager 35647 Jps [root@node3 hadoop-2.7.5]# |
4.2.3.10. Web访问
Web访问,要先开放端口或者直接关闭防火墙
(1)输入命令,systemctl stop firewalld.service
(2)浏览器打开http://192.168.60.157:8088/
(3)浏览器打开http://192.168.60.157:50070/
4.2.4. 安装Hbase
– Hadoop集群要启动正常
– Zookeeper集群启动正常
检查:时间要求同步(查看时间date)、免秘钥
4.2.4.1. 相关配置
•配置regionservers 文件,主机名/etc/hosts
•配置backup-masters文件(配置masters高可用的备份机)
•配置hbase-env.sh文件
–配置JAVA_HOME
–配置HBASE_MANAGERS_ZK=false
•配置hbase-site.xml文件
– Hbase.rootdir
– Zookeeper集群主机
–启用hbase集群:true
Hbase-site.xml
– – – – – – – – – – – –
|
•将hdfs-site.xml文件放到hbase的conf目录下
– a.Add a pointer to your HADOOP_CONF_DIR to the HBASE_CLASSPATH
environment variable in hbase-env.sh.
– b.Add a copy of hdfs-site.xml (or hadoop-site.xml) or, better,symlinks, under
${HBASE_HOME}/conf, or
•启动hbase 集群
启动zookeeper
启动hdfs
启动hbase
Hbase安装目录/bin/start-hbase.sh
5. Hbase shell 操作
Hbase DDL和DML
DDL:创建表,删除表,删除列族,获取所有表
DML:数据插入,获取数据,根据时间戳获取版本数据
Hbase中可以管理域名空间和表及表中的数据,也可以设置表的生命周期DTL,设置是否放在缓存中IN_MEMERY,操作域名空间(hbase和default),可以将在memStore中表的数据强制flush到fileStore文件中(flush “表名”)、以K-V的格式查看hfile文件(hbase hfile –p –f region)等。
hbase shell常用的操作命令有create,describe,disable,drop,list,scan,put,get,delete,deleteall,cou
nt,status等,通过help可以看到详细的用法
5.1. DDL操作
(1)建立一个表create
– hbase(main):001:0> create 'scores','grade', 'course' – 0 row(s) in 0.4780 seconds |
(2)查看当前HBase中具有哪些表list
– hbase(main):002:0> list – TABLE – scores – 1 row(s) in 0.0270 seconds |
(3)查看表的构造describe
– hbase(main):004:0> describe 'scores' – DESCRIPTION ENABLED – {NAME => 'scores', FAMILIES => [{NAME =>'course', BLOOMFILTER => 'NONE', REPLICATION_SCOPE =>'0', true – COMPRESSION => 'NONE', VERSIONS =>'3', TTL => '2147483647', BLOCKSIZE =>'65536', IN_MEMORY => 'fal – se', BLOCKCACHE => 'true'}, {NAME => 'grade', BLOOMFILTER => 'NONE', REPLICATION_SCOPE => '0', COMPR – ESSION => 'NONE', VERSIONS => '3', TTL => '2147483647', BLOCKSIZE =>'65536', IN_MEMORY => 'false', – BLOCKCACHE => 'true'}]} – 1 row(s) in 0.0390 seconds |
(4)删除列族(alter、disable、enable )
– hbase(main):004:0> disable 'table1' – 0 row(s) in 0.0390 seconds – hbase(main):004:0> alter 'table1', {NAME=>'cf1',METHOD=>' delete '} – 0 row(s) in 0.0390 seconds
|
(5)删除表(disable、drop)
– hbase(main):004:0> disable 'table1' – 0 row(s) in 0.0390 seconds – hbase(main):004:0> drop 'table1' – 0 row(s) in 0.0390 seconds
|
5.2. DML操作
(1)插入数据put
– hbase(main):001:0> put 'table1', 'row1','cf1:a', 'aaa' – 0 row(s) in 0.4780 seconds |
(2)查看表中记录,scan
– hbase(main):002:0> scan 'table1' –
|
(3)获取数据,get
– hbase(main):004:0>get 'table1', 'row1'
– hbase(main):004:0>get 'table1', 'row1', 'cf1:a'
– hbase(main):004:0> get 'table1', 'row1',{COLUMN=>'cf1:a',TIMESTAMP=>12424354363}
|
6. Hbase JAVA API
获取cof
创建表
添加数据
查询(普通查询和过滤器查询)
7. Mapreduce操作hbase
•通过TableMapReduceUtil初始化job
8. Rowkey设计
9. Hbase调优
region分区
rowkey设计
列族设计
[A1]待考验