1 ETL抽取现状
现有的ETL产品都是通过sql接口从生产数据库上抽取,或者是由生产数据库的应用开发商根据ETL的要求定期生成接口文件。这是ETL常见的两种接口方式。
在目前的ETL抽取机制中,一般有以下几种限制条件:
(1)ETL抽取频率为1天一次
无论是ETL直接从生产数据库中读取数据,还是通过生成数据文件的方式来传输数据。其频率一般都是每天进行一次。因为无论是直接抽取还是生成数据文件,都只能选择在夜间业务量较小的时间段完成。
(2)无法有效处理增量数据识别问题
按照ETL的设计原理,每天从生产系统抽取数据最好是当天的变化数据,这样能大幅度缩短抽取时间,将对生产系统的性能影响降到最低。为了实现增量数据的抽取,就必须具备识别增量数据的条件,通常的做法包括:
a) 通过生产系统中的table中的某个字段来表示该数据是否发生了改变,以及发生改变的日期;
b) 在生产系统中的table上增加timestamp字段,用来记录该条记录发生变化的时间;
c) 由应用厂商来根据业务逻辑判断,将当天的改变数据自动生成接口文件。
以上三种方式不能适合所有的情况,尤其是那些经常进行UPDATE的操作的表更是难以处理。
不得以,很对用户的ETL对那些无法识别增量的table进行每天一次全量抽取,通过全量数据来和前一次抽取的数据之间进行比较来判断数据的增、删、改。
这种方式最大的问题在于:
(1) 每天抽取的数据量过于庞大。每天上亿到几十亿条记录都重新处理将占用大量资源和时间;
(2) 每次的抽取对生产系统占用大量的资源,严重影响到生产系统的正常运行。
1.1 实时ETL抽取改造目标
因此,数据抽取领域需要一个ETL抽取增强的解决方案,以期望达到以下目标:
(1) 解决目前需要应用厂商提供接口文件的复杂程度,以及需要每天对update的记录进行全表抽取所带来的问题
(2) 为未来更加实时的ETL抽取奠定基础,例如将来可实现每几分钟、10分钟的抽取间隔;
(3) 降低ETL抽取对生产系统的性能影响
(4) 避免每天的全量数据处理
(5) 提供增量识别机制
2 DSGETLPlus解决方案概要
DSG ETLPlus解决方案的目的是为ETL工具提供一个增量实时数据抽取解决方案。
该工具利用对生产系统ORACLE redo log的跟踪机制,来对生产系统的数据进行变化跟踪,然后将跟踪到的变化数据传输到中间数据库上,在中间数据上对数据进行整合、过滤和判断,并且生产数据接口,将接口文件提供给ETL工具使用。
ETL软件可以从接口数据文件中获取增量数据,同时ETL也可以从镜像库中获取所有需要的其他数据(例如首次数据抽取,或者全量数据抽取)
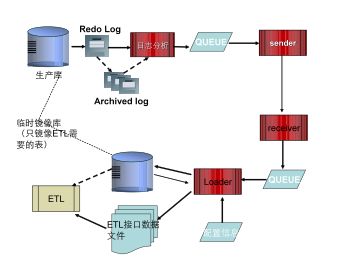
上图为DSG ETLPlus的工作原理图,从中我们可以看出ETLPlus不是去替代现有的ETL工具,而是对现有的ETL工具进行增强,增强之处在于:
(1)将ETL和生产系统分开,形成中间数据库。
(2)ETLPlus的增量通知功能,使得ETL简单容易识别增量数据;
(3)ETLPlus根据接口要求自动生成和ETL的接口数据,而且接口数据可以根据参数配置设定生产间隔,可以实现到每几秒钟生成一个接口文件。
(3)可为ETL提供一些有价值的附加功能,例如提供全量数据抽取时的静态数据支持等。
2.1 技术要点分析
为了提供增量数据实时抽取功能,ETLPlus软件提供了如下关键技术:
(1)oracle数据库的增量跟踪技术
增量跟踪技术是该组件的最重要环节,因为该环节的目的是解决传统ETL厂商无法解决的实时抽取和增量抽取问题。
DSG ETLPlus产品采取的增量识别技术如下:
在源端数据库上安装ETLPlus agent代理程序。源系统端的Agent进程对Oracle Log日志进行实时分析,从而获取源系统端的交易指令;然后,将这些交易指令和交易数据经过格式转化生成数据格式,并根据不同业务需求进行过滤和转化成与生产应用相吻合的指令;再次,实时传输到目标端系统。
(2)数据存储和增量变化通知功能
有了数据的实时捕获,那么捕获到的数据如何通知给ETL工具,如何将数据保存起来供ETL使用,这就是本产品的第二个关键点。
本产品采用的技术路线如下:
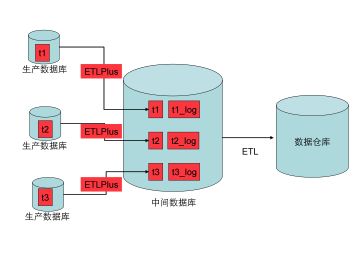
首先创建一个中间数据库,该数据库用作ETL直接数据抽取的数据库,避免ETL直接从生产数据库中抽取;
ETLPlus软件将识别到的技术发送到中间数据库的代理程序上;
代理程序将变化数据作两类处理:一是在中间数据库上维护一张和生产系统对应的数据表;二是根据变化记录经过整理形成完整的记录形成接口文件。
这样ETL工具就能够根据变化跟踪记录中记录所有发生过变化的记录,并且生成ETL工具所需要的增量数据。从而实现增量数据的实时抽取。
2.2 解决方案优势
本方案是在现有的数据仓库基础上进行改造和增强来完成,对现有的数据仓库中已经购买的ETL软件和数据仓库软件完全兼容。
经过此改造,我们认为对于数据库的数据抽取将带来本质上的变化:
(1) 缩短抽取时间:可达到准实时的数据抽取效果,间隔可达到几秒、几分钟;
(2) 降低对CRM数据库的影响:采用ETLPlus对CRM的redo log分析的CPU资源占用<5%,这远远小于ETL直接采用select方式所需要的资源;
(3) 降低数据仓库压力:采用该方式后,不用每天都对全量数据进行处理,只需需要多增量数据部分进行处理。
3 DSG ETLPlus部署方案
3.1 部署结构
为了部署ETLPlus,以采用如下方式来部署:
在数据源的oracle数据库上安装ETLPlus Agent,用来跟踪数据源上的数据变化,通过对redo log进行分析,将跟踪到的变化记录从日志中整合出来(不需要从生产数据库中select)。
在数据仓库服务器上或者在ODS服务器上也安装ETLPlus agent,同时在目标端机器上安装一个oracle数据库,ETLPlus Agent一方面将需要抽取的那些表在目标端服务器上维护一个实时更新的与生产系统保持同步的相同的表;同时在目标端上为每个表每隔一定时间生成一个接口文件。
ETL工具通过ETLPlus生成的接口文件来获取变化的数据内容,实现数据仓库或者ODS系统的数据更新;
如果ETL工具需要进行全量数据抽取,那么就可以直接在ETLPlus维护的目标端表中直接抽取,而不需要从生产数据库中再去抽取。
在ETLPlus部署中,需要一个中间数据库系统,该系统需要服务器、磁盘阵列和ORACLE数据库,ETLPlus将生成的ETL接口文件保存到该服务器的文件系统上供ETL工具读取。
3.2 软硬件环境要求
以上方案中提到了需要一个ETLPlus的中间数据库(这里我们叫做接口数据库),该接口数据库有两个目的:
(1) 保存了ETL所需要的表的完全数据,这些表和生产系统保持实时同步
(2) 这些表可用作全量抽取时使用,让全量抽取的时候也不需要到生产数据库上获取
(3) 帮助生成增量接口数据文件,因为对于INSERT ,DELETE操作来说,完全可以依赖于从源表读取来的redo log生成完整的接口数据;但是对于UPDATE操作来说,无法根据redo log的数据来生成完成一条记录,而必须借助于接口数据库中的完整数据。
该中间数据库可在ODS系统或者数据仓库系统中预留部分空间即可。
3.3 ETL接口文件说明
一、 接口文件格式要求
根据和ETL开发商的沟通讨论结果,DSG ETLPlus将根据规则生成接口数据文件,接口数据文件以不同的table作为一个定义,这里以一个table的定义为例说明:
1.接口数据项
| 接口单元名称: |
组织 |
||||
| 接口单元编码: |
11023 |
||||
| 接口单元说明: |
组织 |
||||
| 抽取方式及周期: |
定时增量 |
||||
| 接口数据文件名: |
a_YYYYMMHH24MI_11023.dat |
||||
| 校验文件名: |
a_YYYYMMHH24MI_11023.verf |
||||
| 接口单元属性列表: |
|
||||
| 属性编码 |
属性名称 |
属性类型 |
是否可为空 |
是否主键 |
备注 |
| PARTY_ID |
参与人标识 |
DECIMAL(12,0) |
N |
Y |
|
| PARENT_PARTY_ID |
上级组织 |
DECIMAL(12,0) |
N |
N |
|
| ORG_CODE |
组织标识 |
VARCHAR(30) |
N |
N |
|
| ORG_NAME |
组织名称 |
VARCHAR(50) |
N |
N |
|
| ORG_LEVEL |
组织级别 |
DECIMAL(5,0) |
N |
N |
|
| ORG_CONTENT |
组织简介 |
VARCHAR(250) |
N |
N |
|
| ADDRESS_ID |
地址标识 |
DECIMAL(12,0) |
N |
N |
|
| STATE |
状态 |
VARCHAR(3) |
N |
N |
|
| STATE_DATE |
状态时间 |
TIMESTAMP(0) |
N |
N |
|
| ORG_TYPE |
组织类型 |
VARCHAR(3) |
N |
N |
|
2.接口数据文件
a_200902221815_11023.dat
I|-1|-1|-1|缺省组织|-1|外键关联用,无意义|-1|00A|2009-2-2218:01:00|1|
I|1|-1|1|中国电信集团|1|中国电信集团|-1|00A|2009-2-2218:01:00|1|
I|10|1|10|甘肃电信|2|甘肃电信|-1|00A|2009-2-2218:01:00|2|
D|10|1|10|甘肃电信|2|甘肃电信|-1|00A|2009-2-2218:05:00|2|
I|931|10|931|兰州电信|3|兰州电信|-1|00A|2009-2-2218:01:00|2|
U|931|10|931|兰州电信公司|3|兰州电信公司|-1|00A|2009-2-2218:08:00|2|
3.接口数据校验文件
a_200902221815_11023.verf
a_200902221815_11023.dat 386 6 20090222181520090222182615
4.日接口校验汇总文件
d_a_20090225.verf
a_200902211230_10001.dat 0
a_200902211230_10002.dat 14
a_200902211230_10003.dat 200
a_200902211230_10004.dat 12
a_200902211230_10005.dat 50
a_200902211230_20001.dat 18
a_200902211230_20002.dat 62
a_200902211300_10001.dat 44
a_200902211300_10002.dat 23
a_200902211300_10003.dat 0
a_200902211300_10004.dat 15
a_200902211300_10005.dat 0
a_200902211300_20001.dat 18
a_200902211300_20002.dat 10087
二、 配置参数说明
为了提供上述信息的配置项,DSG ETLPlus将提供如下的配置信息来配置需要输出的接口定义:
ETL_INTF.CONF
[COMMON]
OUT_DIR=$DBPS_HOME/intdata /*指明输出数据所存放的路径*/
ITVL= 3600 /*指明数据输出的间隔,单位为秒*/
TMPFILE_suffix=.TMP /*指明临时文件的后缀名*/
Separator =‘|’ /*指明数据项之间的分隔符*/
[TABLE1]
TABLE_NAME=OWNER.TABLE_NAME /*表名*/
data_FILE_name=$tablename_YYYYMMDDHHMISS_????.dat /*该表所对应的输出接口datafile文件的命名格式*/
verify_FILE_name=$tablename_YYYYMMDDHHMISS_????.verf /*该表所对应的输出接口verifyfile文件的命名格式*/
date_verify_FILE_name=d_$tablename_YYYYMMDD.verf /*该表所对应的输出接口dateverify file文件的命名格式*/
field_list=PARTY_ID,PARENT_PARTY_ID,ORG_CODE,ORG_NAME /*定义该表所需要输出的字段及其输出顺序*/
[TABLE2]
TABLE_NAME=OWNER.TABLE_NAME /*表名*/
data_FILE_name=$tablename_YYYYMMDDHHMISS_????.dat /*该表所对应的输出接口datafile文件的命名格式*/
verify_FILE_name=$tablename_YYYYMMDDHHMISS_????.verf /*该表所对应的输出接口verifyfile文件的命名格式*/
date_verify_FILE_name=d_$tablename_YYYYMMDD.verf /*该表所对应的输出接口dateverify file文件的命名格式*/
field_list=PARTY_ID,PARENT_PARTY_ID,ORG_CODE,ORG_NAME /*定义该表所需要输出的字段及其输出顺序*/
4 名词术语
1、ETL
是英文 Extract-Transform-Load 的缩写,用来描述将资料从来源端经过萃取(extract)、转换(transform)、加载(load)至目的端的过程。
2、ETL配置文件
ETL配置文件是用于保存ETL相关操作规则的一个文本文件,所有和ETL相关的操作和转换都在这个文件里面定义。
3、配置文件保留字
配置文件保留字是指在ETL配置文件中使用的一些名称,这些名称是固定的,不能修改,大小写敏感。
4、ETL转换和ETL转换名
本文档中,对一个表的结构和数据行的转换过程称为一个“ETL转换”。在配置文件中,要对所有的“ETL转换”进行命名,称之为ETL转换名。
5、外部查询和外部查询名
在ETL转换过程中,可能要通过其它表进行数据的转换,如代码转换过程。本文档中,这种对于其它表的查询操作称为外部查询。对每一个外部查询,用户都必须赋以一个名字,谓之外部查询名。使用外部查询名可以让用户定义一个转换,并在多个表中使用该转换功能,而不必在每个转换中书写一次查询语句。
5 ETL配置文件
5.1 (一)、配置文件作用
配置文件是用户设置ETL转换规则的地方,该文件在用户发起同步(首次同步和实时同步都会作解析)时作解析,文件解析完成后在作具体数据转换时将不再加载该文件。
如果用户没有设置该文件或设置错误,或者该文件不存,那么对该文件解析将出错,这种情况下,转换功能将不起作用。只有当该文件存在并解析正确时将作下面的具体的数据转换工作。所以在作具体转换工作前请使用图形界面或其他的工具来检查配置文件是否正确。
配置文件名为rule.conf,存放在源端$DBPS_HOME/config/子目录下。
5.2 (二)、配置文件格式说明
- 以"#"符号开头的行为注释,注释不作解析。注释必须为单行。不支持多行注释。
- 配置文件分隔为节,每个节以方括号包围的节名开始,到下一节开始或文件结束为止。
- 配置文件由“[RULES]”节开始,格式如下:
[RULES]
RULES=
MAP_NAMES=<外部查询名1>[,外部查询名2 ...]
外部查询名1= 标准的select语句。参见实例说明。
说明:
该部分记录所有ETL转换名,也就是哪些表进行转换。换句话说,每个表的转换都独立成为配置文件的一节,并且列在配置文件保留字“RULES”一行中。不在该行中出现的ETL转换,即使写到配置文件中也不会起飞作用。
配置文件保留字“RULES”后面记录是所有的ETL转换名,ETL转换名由用户自定义,建议使用“用户名.表名”的格式,ETL转换名是区分大小写的。多个规则名间用“,”分隔开。ETL转换名中不可以包含空格。
配置文件保留字MAP_NAMES定义代码转换使用的外部查询,每个外部查询由一个标准的查询SQL语句和一个外部查询名组成。但这个查询SQL语句必须满足一定的限制条件。外部查询名是由用户定义的,大小写不敏感。查询名必须写到MAP_NAMES行中,否则不会生效。
使用外部查询的是定制函数SUBSTITUTE,它只能使用外部查询名,而不能直接给它一个查询SQL语句。
使用外部查询名可以让用户定义一个代码转换,并在多个表中使用该转换功能,而不必在每个转换中书写一次查询语句。
参见外部查询配置实例。
- 具体的ETL转换部分格式:
[ETL转换名]
DS_OWNER=<源端表的所有者名称>
DS_TNAME=<源端表名>
DT_OWNER=<目标端表的所有者名称>
DT_TNAME=<目标端表名>
COL_MAP_CNT=<该表列转换规则数>
COL_MAP_<顺序号1>=<源端列名[,源端列名…]>:<目标端列名>(目标端列数据类型)[转换表达式]
……
COL_MAP_<顺序号n>=<源端列名[,源端列名…]>:<目标端列名>(目标端列数据类型)[转换表达式]
ROW_FILTER_CNT=1
ROW_FILTER_1=<行过滤表达式>
说明:
配置文件保留字DS_OWNER、DS_TNAME和DT_OWNER、DT_TNAME分别标明表的源端表的所有者、源端表名,和目标端表的所有者、目标端表名
配置文件保留字COL_MAP_CNT记录该表中列转换规则个数。每个列转换规则对应本行之后的一行,也就是一个列替换规则。目标端不同于源端的列必须在这里定义,而目标端和源端相同的列不必记录。换句话说,默认情况下,没有记录在这里的字段都会原封不动复制到目标端。
每个列转换占用一行,由三个域组成。其中,
l 等于号左边为COL_MAP_顺序号,这个顺序号将影响目标端列的顺序。
l 等于号右测又分为两个域,由冒号分隔。
l 冒号左侧是源端列名列表,用逗号分隔。
l 冒号右侧由目标端列名、数据类型和一个由方括号包围的转换表达式组成。
l 在这几个域都不缺失时的意义为:源端列表涉及的字段通过转换表达式转换成目标端的相应的字段及数据类型。
l 冒号右侧缺失,表示冒号左侧的列不复制到目标端中,也就是删除一个列。
l 冒号左侧缺失,表示新增加一个列。这种情况下,如果冒号右侧转换表达式中使用到了源端的列时,表达式仍然有效。
l 其它较复杂的情况可以由以上几种情况的组合实现。参见实例说明
l 所有的数据转换都可以表示为一个算术表达式,表达式里可以使用函数,可以由函数和(Oracle支持的)操作符组合成复杂的表达式。但表达式中不支持SQL语句中的CASE…THEN…ELSE…END子句。在表达式中,一个“字符串值”要放在两个单引号“'”中间,不在单引号中间的字符串值将会被认为是一个字段名或者是一个数值。例如:在表达式col1+3||'col1'的意思是:字段col1的值加1然后转换成字符串,再将c、o、l和1四个字母组成的字符串连接到该字符串之后。目前表达式中不支持双引号“"”。
配置文件保留字ROW_FILTER_CNT规定转换中对行的过滤条件数,目前只支持一个行过滤条件,也就是说只能是ROW_FILTER_CNT=1。
配置文件保留字ROW_FILTER_1规定行过滤条件,行过滤条件是一个类似PL/SQL中的条件表达式,相当于SQL查询中的的WHERE条件。如col1+3>col2 AND fname IS NULL。凡是满足行过滤条件的记录都不会被复制到目标端。ROW_FILTER_CNT=1
5.3 (三)、可以支持的转换操作
数据转换部分现在可以支持的转换操作有:
1、名字修改转换:
l 支持源端和目标端用户名不同的转换,源端和目标端表名不同的转换,源端和目标端字段名不同的转换。
l 支持对一个表的字段增加,删除,修该源字段类型。
2、列数据具体转换:
l 支持对NUMBER类型数据作的+, -, *, /的转换。
l 支持给一个列设置默认值,当该列为空时自动替换为设置的默认值。
3、行数据过滤:
l 过滤条件可以为一个条件表示式:例如
(Col1 + 3) > col2 AND col3 IS NOT NULL
5.4 (四)、配置文件格式实例说明:
以下的例子中均使用这样的假设:
源端有表DSGSRC.TAB1,结构为:
| 序号 |
列名 |
列类型 |
| 1 |
COL1 |
NUMBER |
| 2 |
COL2 |
VARCHAR2(10) |
| 3 |
COL3 |
DATE |
转换到目标端的DSGTGT. TAB_NEW
例1、增加列COL4,目标端结构如下
| 序号 |
列名 |
列类型 |
| 1 |
COL1 |
NUMBER |
| 2 |
COL2 |
VARCHAR2(10) |
| 3 |
COL3 |
DATE |
| 4 |
COL4 |
VARCHAR2(10),值为源端的COL1的内容转换成字符串而成 |
配置文件内容如下:
[RULES]
RULES=DSGSRC.TAB1
[DSGSRC.TAB1]
#源端用户名
DS_OWNER=DSGSRC
#源端表名
DS_TNAME=TAB1
#目标端用户名
DT_OWNER=DSGTGT
#目标端表名
DT_TNAME=TAB_NEW
# 列转换规则
COL_MAP_CNT=1
COL_MAP_1=:COL4(VARCHAR2(10))[col1]
例2、删除一列COL3,目标端结构如下
| 序号 |
列名 |
列类型 |
| 1 |
COL1 |
NUMBER |
| 2 |
COL2 |
VARCHAR2(10) |
[RULES]
RULES=DSGSRC.TAB1
[DSGSRC.TAB1]
#源端用户名
DS_OWNER=DSGSRC
#源端表名
DS_TNAME=TAB1
#目标端用户名
DT_OWNER=DSGTGT
#目标端表名
DT_TNAME=TAB_NEW
# 列转换规则
COL_MAP_CNT=1
COL_MAP_1=COL3:
例3、修改列名称
将COL1改名为FROMCOL1并且类型改变为VARCHAR2(10),目标端结构如下
| 序号 |
列名 |
列类型 |
| 1 |
FROMCOL1 |
VARCHAR2(10) |
| 2 |
COL2 |
VARCHAR2(10) |
| 3 |
COL3 |
DATE |
[RULES]
RULES=DSGSRC.TAB1
[DSGSRC.TAB1]
#源端用户名
DS_OWNER=DSGSRC
#源端表名
DS_TNAME=TAB1
#目标端用户名
DT_OWNER=DSGTGT
#目标端表名
DT_TNAME=TAB_NEW
# 列转换规则
COL_MAP_CNT=2
COL_MAP_1=COL1:
COL_MAP_2=COL1: FROMCOL1 (VARCHAR2(10))[COL1]
例4、数据行过滤
目标端结构和源端一样,但只复制COL1<=20的行。目标端结构如下:
| 序号 |
列名 |
列类型 |
| 1 |
COL1 |
NUMBER |
| 2 |
COL2 |
VARCHAR2(10) |
| 3 |
COL3 |
DATE |
[RULES]
RULES=DSGSRC.TAB1
[DSGSRC.TAB1]
#源端用户名
DS_OWNER=DSGSRC
#源端表名
DS_TNAME=TAB1
#目标端用户名
DT_OWNER=DSGTGT
#目标端表名
DT_TNAME=TAB_NEW
# 行过滤规则
ROW_FILTER_CNT=1
ROW_FILTER_1=COL1>20
例5、通过中间表进行代码转换。
假设源端有一个中间代码表C,结构如下:
| 序号 |
列名 |
列类型 |
| 1 |
C1 |
NUMBER |
| 2 |
C2 |
VARCHAR2(10) |
表C的内容如下:
| C1的值 |
C2的值 |
| 一 |
1 |
| 二 |
2 |
| 三 |
3 |
| 四 |
4 |
| …… |
…… |
目标端结构增加一列B(VARCHAR2(10)),它的内容是COL1通过表C进行代码转换而成,如COL1为“1”,则B为“一”,COL1为“2”,则B为“二”,依此类推,对于不存在于C表C2列的数值,则填入“not found”。
| 序号 |
列名 |
列类型 |
| 1 |
B |
VARCHAR2(10) |
| 2 |
COL1 |
NUMBER |
| 3 |
COL2 |
VARCHAR2(10) |
| 4 |
COL3 |
DATE |
[RULES]
RULES=DSGSRC.TAB1
# 定义代码转换使用的外部查询,本例定义了两个外部查询,但只使用了一个:
MAP_NAMES=conva,VESSELENAME
conva=selectc2,c1 form c
VESSELENAME= select distinct du.VES_code, vn.VES_name from dock_UNCODE du, EDI_UNCODE eu,VESSELENAME vn WHERE du.code=eu.code and eu.code=vn.code
[DSGSRC.TAB1]
#源端用户名
DS_OWNER=DSGSRC
#源端表名
DS_TNAME=TAB1
#目标端用户名
DT_OWNER=DSGTGT
#目标端表名
DT_TNAME=TAB_NEW
# 列转换规则
COL_MAP_CNT=1
COL_MAP_1=:B[SUBSTITUTE(COL1,'conva', ’not found’)]
例6、综合例子
综合例1到例5的例子,目标端的表结构如下:
| 序号 |
列名 |
列类型 |
| 1 |
COL4 |
VARCHAR2(10) |
| 2 |
FROMCOL1 |
VARCHAR2(10) |
| 3 |
B |
VARCHAR2(10) |
| 4 |
COL2 |
VARCHAR2(10) |
[RULES]
RULES=DSGSRC.TAB1
MAP_NAMES=conva
# 定义代码转换使用的外部查询,这里只定义了一个外部查询:
MAP_NAMES=conva
conva=selectc2,c1 form c
[DSGSRC.TAB1]
#源端用户名
DS_OWNER=DSGSRC
#源端表名
DS_TNAME=TAB1
#目标端用户名
DT_OWNER=DSGTGT
#目标端表名
DT_TNAME=TAB_NEW
# 列转换规则
COL_MAP_CNT=5
COL_MAP_1=:COL4(VARCHAR2(10))[col1]
COL_MAP_2=COL3:
COL_MAP_3=COL1:
COL_MAP_4=COL1: FROMCOL1 (VARCHAR2(10))[COL1]
COL_MAP_5=:B[SUBSTITUTE(COL1,'conva', ’not found’)]
#行过滤规则
ROW_FILTER_CNT=1
ROW_FILTER_1=COL1>20
6 函数
6.1 概述
ETL转换表达式中,许多转换通过函数来完成。除“定制函数”外,其它函数参照Oracle10G的SQL函数实现。除个别函数和Oracle 10G的SQL函数有微小区别外,其它基本一致。所以,具体的细节可以参考Oracle 10G的SQL参考文档。
本章后面几节列出了所有受到支持的函数,不要试图使用任何未列在本文档中的函数,那只会导致转换失败。
另,在程序未实际交付使用前,本章列出的函数可能有一些暂时还没提供支持,请与开发人员联系确认。
6.2 定制函数
| 函数名 |
用法 |
说明 |
| DEFAULT |
DEFAULT(expr, default) |
设置默认值。该函数用于模拟给某个列设置一个默认值。 函数首先计算expr的值,如果为空非NULL,则返回该值。如果expr的值为NULL,则返回default的值。这时,如果default的值为NULL,则返回NULL。 其中expr和default都可以是任意表达式。 |
| SUBSTITUTE |
SUBSTITUTE(expr, 'ex_query'[, default]) |
外部替换。该函数适用于代码转换一类的运算。 函数首先计算expr的值,如果为NULL,则返回NULL。 如果expr的值非NULL,则根据外部查询ex_query的结果进行代码替换。 代码替换的具体过程如下: 假设ex_query=select code search, name result form country_code。代码替换时,检查外部查询的结果集中,如果有一行记录的第一列search的值等于expr的值,则返回该行的第二列result的值。 如果在ex_query的查询结果中没有找到相应的内容,则返回default表达式(如果有的话)的值,如果没有default参数,则返回NULL。 ex_query是代码替换的查询名。必须是一个字符串,这个查询名是用户定义,是对一个标准的查询的命名,并保存在ETL配置文件的外部查询配置中,参见实例一节。它要满足一定的条件,参见外部查询的限制条件。 其中expr和default都可以是任意表达式。 SUBSTITUTE( )函数相当于对 DECODE( )的扩展,SUBSTITUTE函数通过'ex_query'获得一个外部查询的SQL语句得到类似DECODE( )函数参数表中间的那一大串参数 |
6.3 数值函数
| 函数名 |
用法 |
说明 |
| ABS |
ABS(n) |
取n的绝对值 |
| BITAND |
BITAND(arg1, arg2) |
按位与,计算arg1和arg2按位进行与操作的结果 |
| CEIL |
CEIL(n) |
取得大于n的最小整数 |
| EXP |
EXP (n) |
自然指数 |
| FLOOR |
FLOOR (n) |
取得小于等于n的最大整数 |
| LN |
LN(n) |
求对数 |
| LOG |
LOG(m, n) |
求以m为底n的对数 |
| MOD |
MOD (m,n) |
取余函数,取得m除以n的余数 |
| POWER |
POWER (m,n) |
乘方,取得m的n次幂 |
| SQRT |
SQRT (n) |
开平方,取n的平方根 |
| TRUNC |
TRUNC(n [, m ]) |
截断操作。将数值n截断到小数点后m位,如果省略m则全部舍掉小数部分。m可以为负数,这时从小数点开始,从右向左将整数部分-m位数字置0. |
6.4 字符串函数
| 函数名 |
用法 |
说明 |
| CHR |
CHR (n) |
整数转成字符 |
| CONCAT |
CONCAT (s1, s2) |
字符串连接,和操作符“||”相同 |
| LOWER |
LOWER (s) |
全部小写 |
| LPAD |
LPAD(expr1, n [, expr2 ]) |
字符串左填充:用expr2或空格在字符串expr1的左侧填充,直到输出长度为n为止。 |
| LTRIM |
LTRIM(char [, set ]) |
左削边。删除字符串的左侧的set中的字符,默认为空格 |
| REPLACE |
REPLACE(char, search_string [, replacement_string ] ) |
将字符串char中所有出现的search_string替换为replacement_string |
| RPAD |
RPAD(expr1 , n [, expr2 ]) |
字符串右填充:用expr2或空格在字符串expr1的右侧填充,直到输出长度为n为止。 |
| RTRIM |
LTRIM(char [, set ]) |
右削边。删除字符串的右侧的set中的字符,默认为空格 |
| SUBSTR |
SUBSTR(string, position[, substring_length ]) |
取子串。该函数和Oracle 10G的SQL函数SUBSTRB行为一致。 |
| TRIM |
TRIM(char [, set ]) |
两端修整,这个和Oracle的定义有所不同 |
| UPPER |
UPPER(char) |
全部大写 |
| ASCII |
ASCII(char) |
返回与指定的字符串第一个字符的ASCII值 |
| INSTR |
INSTR(string , substring [, position [, occurrence ] ]) |
模式匹配,从position处开始从string中查找substring的第occurrence次出现的位置。该函数和Oracle 10G的SQL函数INSTRB行为一致。 |
| LENGTH |
LENGTH (char) |
求字符串长度。该函数和Oracle 10G的SQL函数LENGTHB行为一致。 |
6.5 时间日期处理函数
| 函数名 |
用法 |
说明 |
| ADD_MONTHS |
ADD_MONTHS(d, n) |
日期d增加n个月 |
| CURRENT_DATE |
CURRENT_DATE [( )] |
返回在为数据库会话设置的本地时区中的当前日期 |
| CURRENT_TIMESTAMP |
CURRENT_TIMESTAMP[ (precision) ] |
从数据库服务器取得当前会话所在时区的时间戳,返回类型为TIMESTAMP WITH TIME ZONE |
| EXTRACT |
EXTRACT(d, t) |
从d取得某一个域t t的值可以是:YEAR, MONTH, DAY, HOUR, MINUTE, SECOND, TIMEZONE_HOUR, TIMEZONE_MINUTE |
| LAST_DAY |
LAST_DAY(date) |
取得date所在月的最后一天 |
| LOCALTIMESTAMP |
LOCALTIMESTAMP [(precision)] |
返回TIMESTAMP类型的会话所在时区日期时间 |
| MONTHS_BETWEEN |
MONTHS_BETWEEN(date1, date2) |
计算date1和date2之间有几个月。如果date1在日历中比date2早,那么MONTHS_BETWEEN()就返回一个负数。 |
| NUMTODSINTERVAL |
NUMTODSINTERVAL(n, 'interval_unit') |
将以interval_unit指定的值为单位的数字n转换为一个INTERVAL DAY TO SECOND类型,interval_unit参数可以设置为DAY、HOUR、MINUTE或SECOND。 |
| NUMTOYMINTERVAL |
NUMTOYMINTERVAL(n, 'interval_unit') |
将以interval_unit指定的值为单位的数字x转换为一个INTERVAL YEAR TO MONTH类型,interval_unit参数可以设置为YEAR或MONTH。 |
| ROUND (date) |
ROUND(date [, fmt ]) |
对date取整。默认情况下,date取整为最近的一天。fmt是一个可选字符串参数,它指明要取整的单元。 |
| SYSDATE |
SYSDATE [( )] |
SYSDATE返回数据库服务器的操作系统中设置的当前时间值。 |
| SYSTIMESTAMP |
SYSTIMESTAMP [( )] |
返回一个TIMESTAMP WITH TIME ZONE类型,其中包括数据库的当前日期、时间,以及数据库时区 |
| TO_CHAR |
TO_CHAR({ datetime | interval } [, fmt [, 'nlsparam' ] ]) |
将datetime转换为字符串。该函数还可以为datetime提供可选的参数fmt。 |
| TO_TIMESTAMP |
TO_TIMESTAMP(char [, fmt [ 'nlsparam' ] ]) |
将字符串char转换为一个TIMESTAMP类型,还可以为char指定一个可选的参数format |
| TO_TIMESTAMP_TZ |
TO_TIMESTAMP_TZ(char [, fmt [ 'nlsparam' ] ]) |
将字符串char转换为一个TIMESTAMP WITH TIMEZONE类型,还可以为char指定一个可选的参数format |
| TRUNC |
TRUNC(date [, fmt ]) |
用于对date截断。默认情况下,x被截断为当天的开始时间。fmt是一个可选字符串参数,它指明要截断的单元。 |
6.6 转换处理函数
| 函数名 |
用法 |
说明 |
| CHARTOROWID |
CHARTOROWID(char) |
将字符型数据转换成ROWID数据类型. |
| HEXTORAW |
HEXTORAW(char) |
将保存在CHAR, VARCHAR2, NCHAR, 或者 NVARCHAR2中的十六进制数值字符转换成raw类型值。 |
| RAWTOHEX |
RAWTOHEX(raw) |
将raw类型值转换成相应的十六进制字符,参数raw必须是raw数据类型 |
| ROWIDTOCHAR |
ROWIDTOCHAR(rowid) |
将一个rowid类型值转换成VARCHAR2类型。转换的结果有18个字符。 |
| TO_BINARY_DOUBLE |
TO_BINARY_DOUBLE(expr [, fmt [, 'nlsparam' ] ]) |
函数返回一个双精度的浮点数。 参数expr可以是一个字符串,也可以是一个NUMBER, BINARY_FLOAT,或BINARY_DOUBLE类型的数值。如果expr是一个BINARY_DOUBLE类型的数值,则本函数返回expr。 可选参数'fmt' 和 'nlsparam'只有当expr是一个字符串时才有效,此时与TO_CHAR(number) 函数使用的参数'fmt' 和 'nlsparam'相当。 本函数不支持SQL同名函数对'INF'、'-INF'和'NaN'的定义 不可以在expr字符串参数中引入浮点数的格式字符(F, f, D, 或 d)。 |
| TO_BINARY_FLOAT |
TO_BINARY_FLOAT(expr [, fmt [, 'nlsparam' ] ]) |
函数返回一个单精度的浮点数。 参数expr可以是一个字符串,也可以是一个NUMBER, BINARY_FLOAT,或BINARY_DOUBLE类型的数值。如果expr是一个BINARY_FLOAT类型的数值,则本函数返回expr。 可选参数'fmt' 和 'nlsparam'只有当expr是一个字符串时才有效,此时与TO_CHAR(number) 函数使用的参数'fmt' 和 'nlsparam'相当。 本函数不支持SQL同名函数对'INF'、'-INF'和'NaN'的定义 不可以在expr字符串参数中引入浮点数的格式字符(F, f, D, 或 d)。 |
| TO_CHAR (character) |
TO_CHAR(nchar | clob | nclob) |
函数将NCHAR, NVARCHAR2, CLOB, 或NCLOB类型的数据转换成数据库字符集。 |
| TO_CHAR (datetime) |
TO_CHAR({ datetime | interval } [, fmt [, 'nlsparam' ] ]) |
函数将一个DATE, TIMESTAMP, TIMESTAMP WITH TIME ZONE, 或TIMESTAMP WITH LOCAL TIME ZONE类型的datetime值或datetime间隔值转换成一个VARCHAR2类型的字符串,其格式由参数fmt指定,如果忽略这个参数,则转换按照以下规则进行: DATE类型的值按照默认日期格式转换; TIMESTAMP和TIMESTAMP WITH LOCAL TIME ZONE类型的值按照默认时间戳格式转换; TIMESTAMP WITH TIME ZONE类型的值按照默认时间戳格式和时区格式转换; 参数nlsparam指定月份和天的名称及其简写所用的语言。如果这一参数被忽略,则本函数将使用当前会话的默认日期语言。 |
| TO_CHAR (number) |
TO_CHAR(n [, fmt [, 'nlsparam' ] ]) |
函数将数值n按照可选参数fmt(如果存在的话)指定的格式转换成VARCHAR2类型的字符串。 n可以是NUMBER, BINARY_FLOAT,或 BINARY_DOUBLE类型。 如果忽略fmt参数,则转换结果字符串会足够长以存放n中的有效数字。 |
| TO_DATE |
TO_DATE(char [, fmt [, 'nlsparam' ] ]) |
将类型CHAR,VARCHAR2, NCHAR, 或NVARCHAR2的字符串转换成DATE类型的数据。 参数fmt是datetime型格式,它指明了char的数据格式。如果忽略fmt参数,则char必须按照默认的日期格式。如果为转换成公历而传入fmt参数值为'J',则char必须是一个整数。 |
| TO_NUMBER |
TO_NUMBER(expr [, fmt [, 'nlsparam' ] ]) |
函数将expr转换成NUMBER类型的值。expr可以是BINARY_FLOAT或 BINARY_DOUBLE类型,也可以是CHAR, VARCHAR2, NCHAR, 或NVARCHAR2类型的值,这些字符型expr包含的数值格式可由可选参数fmt指定。 本函数不直接支持CLOB数据,然而CLOBs数据作为传入参数时,可以通过隐性数据转换来实现。 |
| TO_TIMESTAMP |
TO_TIMESTAMP(char [, fmt [ 'nlsparam' ] ]) |
本函数将char指定的CHAR, VARCHAR2, NCHAR, 或NVARCHAR2类型的值转换成TIMESTAMP类型。 可选参数fmt指明传入参数char的数据格式。如果忽略参数fmt,则传入数据char必须是TIMESTAMP类型的默认格式(此格式由初始化参数NLS_TIMESTAMP_FORMAT来指定)。 本函数的参数nlsparam与函数TO_CHAR在转换日期时的作用相同。 |
| TO_TIMESTAMP_TZ |
TO_TIMESTAMP_TZ(char [, fmt [ 'nlsparam' ] ]) |
本函数将参数char指定的CHAR, VARCHAR2, NCHAR, 或NVARCHAR2类型的值转换成TIMESTAMP WITH TIME ZONE类型。 可选参数fmt指明传入参数char的数据格式。如果忽略参数fmt,则传入数据char必须是TIMESTAMP WITH TIME ZONE类型的默认格式。 本函数的参数nlsparam与函数TO_CHAR在转换日期时的作用相同。 |
6.7 杂项函数
| 函数名 |
用法 |
说明 |
| COALESCE |
COALESCE(expr [, expr ]...) |
函数返回表达式列表中第一个不等于NULL的expr的值。至少有一个expr不能为NULL,如果所有的expr都返回NULL,则本函数返回NULL。 |
| DECODE |
DECODE(expr, search, result [, search, result ]... [, default ]) |
Decode函数的目的是对每个search中的值与expr的值相比较,假设expr=sear,那么函数返回对应的result,假设没有找到响应的search,那么函数返回default,假设default没有设置,那么系统返回null。 函数中的值可以是任何类型的number类型或者字符串类型。 Decode函数中的参数最大个数为255个。 |
| GREATEST |
GREATEST(expr [, expr ]...)
|
Greatest函数从一系列表达式中返回最大的值,该函数依据expr的类型来决定返回值的类型,如果第一个expr是数字型,那么该函数就按照数字型去判断最大值,如果是character类型则根据asc的先后顺序为依据进行比较。 |
| LEAST |
LEAST(expr [, expr ]...) |
Leat函数从一系列表达式中返回最小的值,该函数依据expr的类型来决定返回值的类型,如果第一个expr是数字型,那么该函数就按照数字型去判断最小值,如果是character类型则根据asc的先后顺序为依据进行比较。 |
| NULLIF |
NULLIF(expr1, expr2) |
用来判断expr1和expr2,如果相等,函数返回NULL,如果不相等,返回expr1,expr1不能为NULL值。 |
| NVL |
NVL(expr1, expr2) |
判断expr1的值,如果expr1=null,函数返回expr2,如果expr1<>null,函数返回expr1 |
| NVL2 |
NVL2(expr1, expr2, expr3) |
假设expr1<>null,返回expr2,如果expr1=null,返回expr3 |
7 限制条件
7.1 (-)、对单行记录进行转换可能造成的数据不一致:
1、 更新(UPDATE)带有过滤条件字段的表:
如:源端表TAB1(A NUMBER, B CHAR(10)),目标表为TAB1(A NUMBER, B CHAR(10)), 行过滤条件为:A > 20
现在有这样的两条记录:
10, 'AB10'
30, 'AB30'
首次同步操作完成后目标表将只有(A > 20的行数据过滤没有,不加载到目标端):
10, 'ABC10'
情况一、 现在在源端作这样的操作:UPDATE TAB1 SET A=15 WHEREA=30;
这样源端数据为:
10, 'ABC10'
15, 'ABC30'
但产生的XF1包中由于没有原来字段A的内容,那么将没有办法作合理的行过滤。即使这样的数据到了目标端由于首次同步没有这样的数据,在查找rowmapping关系的时候还是会出错,也就说后来目标端的记录不变,实际丢失了记录:15, 'ABC30'
情况二、 现在在源端作这样的操作:UPDATE TAB1 SET A=50 WHEREA=10;
这样源端数据为:
50, 'ABC10'
30, 'ABC30'
由于产生的UPDATE XF1中A为50,这样的数据就需要过滤,所以UPDATE没办法到目标端,目标端数据不变。本来应该在目标端删除该记录的。这样以来目标端就多一条记录。
情况三、现在在源端作这样的操作:UPDATE TAB1 SETB='ABCX' WHERE A=10;
由于UPDATE XF1包存放的数据不完整(没有记录A字段数据),所以过滤条件也没办法很好的判断该条记录是否需要过滤。默认处理是认为该记录是符合要求的,直接转换完成后发送到目标端。这样到目标端如果真是需要转换的将加载成功,否则会出现rowmapping找不到的提示信息,但不影响数据正确性。
情况四、涉及两个以上字段的转换
假设将源的姓(FNAME)和名(LNAME)两个字段合并到目标端的一个字段,如姓名(NAME),转换的规则为:NAME=FNAME||LNAME。如果在源端更新了LANME的值,但没有更FNAME的值,那么在进行ETL转换时无法得到FNAME的值,所以转换会失败。
2、 由于DELETE数据不作任何转换直接发送到目标端,也存在rowmapping找不到的问题,但不影响数据的正确性。
7.2 (二)外部查询的限制条件说明
1、所有中间表是相对固定的,也就是要求所有的中间表在相对长的时间内(比如一个星期或者一个月)是不会变动的。
2、所有中间表的数据都只是在程序启动时装入内存,程序启动后中间表的修改将不会反映到转换结果中。所以,一旦中间表数据有了变动,就要重启复制程序,并且进行全同步。否则无法保证数据的正确性。
3、用户要提供代码转换的SQL语句,并且该语句的查询结果集只能有两个字段。例如:
select distinctdu.VES_code, vn.VES_name from dock_UNCODE du, EDI_UNCODE eu, VESSELENAME vn WHEREdu.code=eu.code AND eu.code=vn.code
4、这个查询结果集的列名称并不重要,重要的是组成结果集的两个列的顺序,代码转换时总是查找第一个列的数据。如果找到相等的数据,返回的是第二列的数据。下面的两个转换是不同的:
Country1=selectcode search, name result form country_code
Country2=selectname result, code search form country_code
5、代码转换的SQL语句可以是任意合法的查询语句。但是,查询结果集目前只运行如下数据类型:CHAR,VARCHAR, VARCHAR2, NUMBER, DATE
6、对于上述支持的数据类型在进行代码替换时,可能会进行隐式的数据类型转换,所以,请勿在SQL语句中使用TO_CHAR()之类的显式数据类型转换函数。如果涉及目前不支持的数据类型,请使用显式的转换函数,如TO_CHAR( ),TO_NUMBER( ),否则转换过程会失败。
7、使用该方式后效率将有明显下降,当然,这和中间表的记录多寡有关。为了提高效率,代码转换的查询结果是在程序调动时一次性调入内存,所以空间效率也会下降,也就是要多占用内存。