畅购商城(七):Thymeleaf实现静态页
好好学习,天天向上
本文已收录至我的Github仓库DayDayUP:github.com/RobodLee/DayDayUP,欢迎Star,更多文章请前往:目录导航
- 畅购商城(一):环境搭建
- 畅购商城(二):分布式文件系统FastDFS
- 畅购商城(三):商品管理
- 畅购商城(四):Lua、OpenResty、Canal实现广告缓存与同步
- 畅购商城(五):Elasticsearch实现商品搜索
- 畅购商城(六):商品搜索
Thymeleaf简单入门
什么是Thymeleaf
Thymeleaf是一个模板引擎,主要用于编写动态页面。
SpringBoot整合Thymeleaf
SpringBoot整合Thymeleaf的方式很简单,共分为以下几个步骤
- 创建一个sprinboot项目
- 添加thymeleaf和spring web的起步依赖
- 在resources/templates/下编写html(需要声明使用thymeleaf标签)
- 在controller层编写相应的代码
启动类,配置文件,依赖的代码下一节有,这里就不贴了。
<html xmlns:th="http://www.thymeleaf.org">
<head>
<title>SpringBoot整合Thymeleaftitle>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8"/>
head>
<body>
<p th:text="${hello}">p>
body>
html>
@Controller
@RequestMapping("/test")
public class TestController {
@RequestMapping("/hello")
public String hello(Model model){
model.addAttribute("hello","欢迎关注微信公众号Robod");
return "demo1";
}
}
这样将项目启动起来,访问http://localhost:8080/test/hello就可以成功跳转到demo1.html页面的内容了。
Thymeleaf常用标签
- th:action 定义后台控制器路径

现在访问http://localhost:8080/test/hello2,如果控制台输出“demo2”,页面还跳转到demo2的话说明是OK的。
- th:each 对象遍历

访问http://localhost:8080/test/hello3就可以看到结果了。
- 遍历Map

访问http://localhost:8080/test/hello4就可以看到输出结果。
- 数组输出

访问http://localhost:8080/test/hello5就可以看到输出结果。
- Date输出
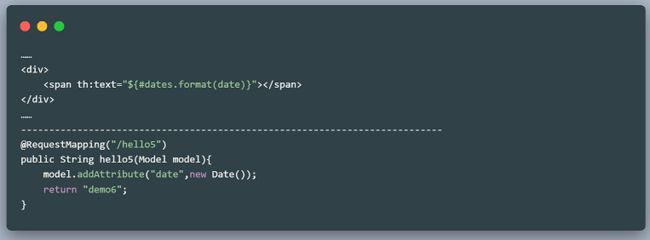
访问http://localhost:8080/test/hello6就可以看到输出结果。
- th:if条件
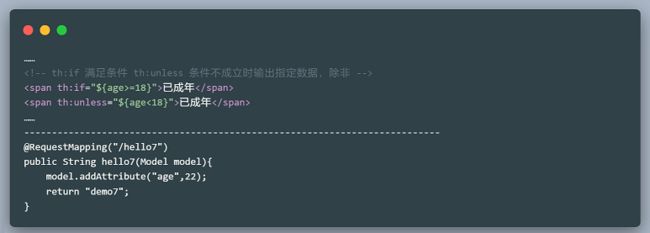
访问http://localhost:8080/test/hello7就可以看到输出结果。
- th:fragment th:include 定义和引入模块
比如我们在footer.html中定义了一个模块:
<div th:fragment="foot">
欢迎关注微信公众号Robod
div>
然后在demo7中引用:
<div th:include="footer::foot">div>
这样访问http://localhost:8080/test/hello7就可以看到效果了。
- |…| 字符串拼接
<span th:text="|${str1}${str2}|">span>
--------------------------------------------
@RequestMapping("/hello8")
public String hello8(Model model){
model.addAttribute("str1","字符串1");
model.addAttribute("str2","字符串2");
return "demo8";
}
访问http://localhost:8080/test/hello8就可以看到输出结果。
想要完整代码的小伙伴请点击下载
搜索页面
微服务搭建
我们创建一个搜索页面渲染微服务用来展示搜索页面,在这个微服务中,用户进行搜索后,调用搜索微服务拿到数据,然后使用Thymeleaf将页面渲染出来展示给用户。在changgou-web下创建一个名为changgou-search-web的Module用作搜索微服务的页面渲染工程。因为有些依赖是所有页面渲染微服务都要用到的,所以在changgou-web中添加依赖:
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-thymeleafartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-netflix-eureka-clientartifactId>
dependency>
<dependency>
<groupId>io.github.openfeigngroupId>
<artifactId>feign-httpclientartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-amqpartifactId>
dependency>
dependencies>
Feign的依赖这里我发现了一个问题,因为我不是把SearchEntity根据下图的流程通过Feign传递到changgou-service-search么。如果添加我注释的那个依赖就会出现HttpRequestMethodNotSupportedException: Request method 'POST' not supported异常。添加后面一个依赖就不会出现问题。我到网上查了一下,貌似是Feign的一个小Bug,就是如果在GET请求里添加了请求体就会被转换为POST请求。

因为我们需要使用到Feign在几个微服务之间进行调用,所以在changgou-search-web添加对changgou-service-search-api的依赖。
<dependencies>
<dependency>
<groupId>com.robodgroupId>
<artifactId>changgou-service-search-apiartifactId>
<version>1.0-SNAPSHOTversion>
dependency>
dependencies>
然后在changgou-service-search-api下编写相应的Feign接口用来调用changgou-service-search:
@FeignClient(name="search")
@RequestMapping("/search")
public interface SkuEsFeign {
/**
* 搜索
* @param searchEntity
* @return
*/
@GetMapping
Result<SearchEntity> searchByKeywords(@RequestBody(required = false) SearchEntity searchEntity);
}
然后在changgou-search-web下的resource目录下将资料提供的静态资源导入进去。因为主要是做后端的功能,所以前端就不写了,直接导入:

最后将启动类和配置文件写好:
@SpringBootApplication
@EnableEurekaClient
@EnableFeignClients(basePackages = "com.robod.feign")
public class SearchWebApplication {
public static void main(String[] args) {
SpringApplication.run(SearchWebApplication.class,args);
}
}
server:
port: 18086
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:7001/eureka
instance:
prefer-ip-address: true
spring:
thymeleaf:
#构建URL时预先查看名称的前缀,默认就是这个,写在这里是怕忘了怎么配置
prefix: classpath:/templates/
suffix: .html #后缀
cache: false #禁止缓存
feign:
hystrix:
enabled: true
application:
name: search-web
main:
allow-bean-definition-overriding: true
# 不配置下面两个的话可能会报timed-out and no fallback available异常
ribbon:
ReadTimeout: 500000 # Feign请求读取数据超时时间
hystrix:
command:
default:
execution:
isolation:
thread:
timeoutInMilliseconds: 50000 # feign连接超时时间
这样我们的搜索页面微服务工程就搭建好了。然后在创建一个SkuSearchWebController类,然后创建一个searchByKeywords方法作为搜索功能的入口
@GetMapping("/list")
public String searchByKeywords(SearchEntity searchEntity
, Model model) {
if (searchEntity == null || StringUtils.isEmpty(searchEntity.getKeywords())) {
searchEntity = new SearchEntity("小米");
}
if (searchEntity.getSearchSpec() == null) {
searchEntity.setSearchSpec(new HashMap<>(8));
}
SearchEntity result = skuFeign.searchByKeywords(searchEntity).getData();
model.addAttribute("result", result);
return "search";
}
这里我指定了一个默认的关键词,因为我发现如果searchEntity为null的话Feign就会报出timed-out and no fallback available,指定默认关键词就可以解决这个问题,而且也符合逻辑,淘宝上如果不在搜索栏填入任何内容就会搜索默认的关键词。
这个时候如果去访问http://localhost:18086/search/list是没有图片和css样式的,因为现在的seearch.html中指定的相对路径,也就是去访问search/img/下的图片,其实是在img/下,所以我们还需要把相对路径改为绝对路径。把search中的href="./改为href="/,把src="./改为src="/,这样访问的就是img/下的图片了。页面就可以正常显示了。

这样的话搜索页面渲染微服务就搭建成功了。
数据填充
现在页面所展示的数据并不是我们从ES中搜索出来的真实数据,而是预先设置好的数据。所以现在我们需要把搜索出来的数据填充到界面上。

页面所展示的就是一堆的li标签,我们所需要做的就是留一个li,然后使用Themeleaf标签循环取出数据填入进去。
<div class="goods-list">
<ul class="yui3-g">
<li th:each="item:${result.rows}" class="yui3-u-1-5">
<div class="list-wrap">
<div class="p-img">
<a href="item.html" target="_blank"><img th:src="${item.getImage()}"/>a>
div>
<div class="price">
<strong>
<em>¥em>
<i th:text="${item.price}">i>
strong>
div>
<div class="attr">
<a target="_blank" href="item.html" title=""
th:utext="${#strings.abbreviate(item.name,150)}">a>
div>
<div class="commit">
<i class="command">已有<span>2000span>人评价i>
div>
<div class="operate">
<a href="success-cart.html" target="_blank" class="sui-btn btn-bordered btn-danger">
加入购物车a>
<a href="javascript:void(0);" class="sui-btn btn-bordered">收藏a>
div>
div>
li>
ul>
div>
页面关键词搜索和回显显示
首先指定表单提交的路径,然后指定name的值,将搜索按钮的type指定为“submit”就可以实现页面关键词搜索;然后添加th:value="${result.keywords}"表示取出result.keywords的值,从而实现回显显示的功能。
搜索条件回显及条件过滤显示
分类和品牌
如果没有指定分类和品牌信息的话,后端会将分类和品牌进行统计然后传到前端,当我们指定了分类和品牌之后就不用将分类和品牌进行分类统计了,这个在上一篇文章中说过,但是前端怎么处理呢?使用th:each遍历出数据显示出来,当我们指定了分类或者品牌之后,页面上就不去显示分类或品牌选项。
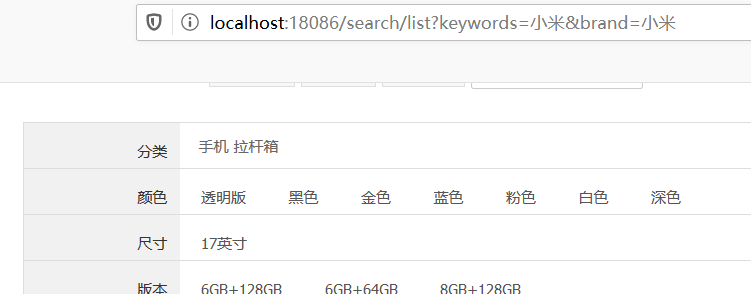
th:unless 的意思是不满足条件才输出数据,所以判断一下categotyList和brandList是不是空的,是空的就不输出内容。不是空的就用th:each遍历,然后用th:text输出。
规格
规格显示和过滤和上面的类似。
searchSpec是传到后端的规格Map
但是前端怎么给后端的searchEntity.searchSpec赋值呢?我不知道,问了一下我哥,他说这样写:http://www.test.com/path?map[a]=1&map[b]=2,然后就报400错误了,控制台显示
Invalid character found in the request target. The valid characters are defined in RFC 7230 and RFC 3986
百度查了一下,这个是Tomcat的一个特性,按照RFC 3986规范进行解析,认为[ ] 是非法字符,所以拦截了。解决方法也很简单,在启动类中添加以下代码:
@Bean
public TomcatServletWebServerFactory webServerFactory() {
TomcatServletWebServerFactory factory = new TomcatServletWebServerFactory();
factory.addConnectorCustomizers(new TomcatConnectorCustomizer() {
@Override
public void customize(Connector connector) {
connector.setProperty("relaxedPathChars", "\"<>[\\]^`{|}");
connector.setProperty("relaxedQueryChars", "\"<>[\\]^`{|}");
}
});
return factory;
}
这样就可以完美地解决问题了,再来试一下

OK!当我们指定了颜色这个规格的时候,就可以成功过滤颜色了,页面也不会显示颜色了。
搜索条件点击
搜索条件点击事件包括点击相应的搜索条件的时候按照选择的条件搜索,并将条件显示在界面上。当删除已选择的搜索条件时,界面上把条件删除掉,同时在后台去掉该搜索条件。
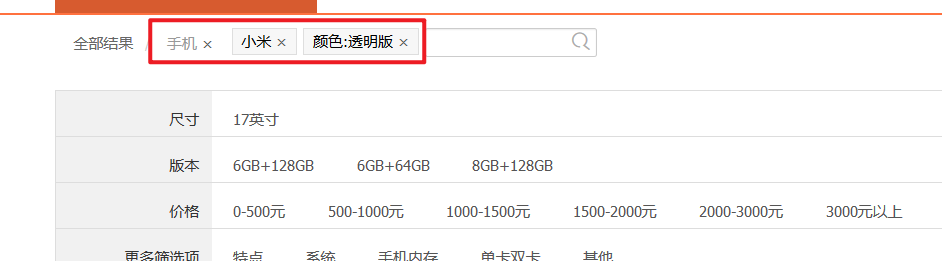
前端页面的实现思路就是修改url,删除条件就是删掉url中对应的内容,然后重新发送请求,增加搜索条件就是在url中添加内容重新发送请求。在SearchEntity中新增了一个url字段用于存放url字符串。

这是点击新增条件的代码,每次点击的时候就在原有的url基础上把新增的条件再加上去,然后发送请求。

点击 x 删除条件就是在原有的url上删除相应的条件,然后发送请求。
但是这里面有个问题,就是“6GB+128GB”中的加号传到后端后会变成空格。我一开始想的是使用拦截器先拦截请求,把url中的空格换回加号后再传到Controller中,但是貌似行不通。然后我就在Controller中遍历searchEntity.SearchSpec,把里面的空格换成加号,这样确实可以实现。但是破坏了代码的美观性。毕竟我是一个比较讲究的人。然后我想到了使用AOP的方式,这样在进入Controller之前预先对参数进行处理,代码就不会杂糅在一个方法里。
@Aspect
@Component
public class SearchAspect {
@Pointcut("execution(public * com.robod.controller.SkuSearchWebController.searchByKeywords(..)) " +
"&& args(searchEntity,model,request))")
public void searchAspect(SearchEntity searchEntity, Model model, HttpServletRequest request){
}
@Before(value = "searchAspect(searchEntity,model,request)",argNames = "searchEntity,model,request")
public void doBeforeSearch(SearchEntity searchEntity,Model model, HttpServletRequest request)
throws Throwable {
if (StringUtils.isEmpty(searchEntity.getKeywords())) {
searchEntity.setKeywords("小米");
}
Map<String,String> specs = searchEntity.getSearchSpec();
if (specs == null) {
searchEntity.setSearchSpec(new HashMap<>(8));
} else {
for (String key:specs.keySet()){
String value = specs.get(key).replace(" ","+");
specs.put(key,value);
}
}
}
}
这个AOP的代码,预先对SearchEntity进行一个处理。很符合逻辑,这样进入到Controller中的参数就是格式正确的。
@GetMapping("/list")
public String searchByKeywords(SearchEntity searchEntity
, Model model, HttpServletRequest request) {
SearchEntity result = skuFeign.searchByKeywords(searchEntity).getData();
result.setUrl(getUrl(request));
model.addAttribute("result", result);
return "search";
}
private String getUrl(HttpServletRequest request) {
StringBuilder url = new StringBuilder("/search/list");
Map<String, String[]> parameters = request.getParameterMap();
if (parameters!=null&¶meters.size()>0){
url.append("?");
if (!parameters.containsKey("keywords")) {
url.append("keywords=小米&");
}
for (String key:parameters.keySet()){
url.append(key).append("=").append(parameters.get(key)[0]).append("&");
}
url.deleteCharAt(url.length()-1);
}
return url.toString().replace(" ","+");
}
Controller中的searchByKeywords方法果然变得很整洁。拼接URL就单独抽取出来了,而且还考虑到了keywords没有值的处理方式。很棒!

排序

当我们点击不同的排序规则的时候,就修改相应的排序规则,但是当我们点击分类条件的时候,之前的排序规格应该带上。所以我们再准备一个sortUrl,我们把排序的规则添加到sortUrl中传到后端,后端再把sortFIleld和sortRule添加到url中再返回到前端,返回到前端的sortUrl中是不带sortFIleld和sortRule的。
<li>
<a th:href="@{${result.sortUrl}(sortField=price,sortRule=ASC)}">价格升序a>
li>
<li>
<a th:href="@{${result.sortUrl}(sortField=price,sortRule=DESC)}">价格降序a>
li>
private String[] getUrl(HttpServletRequest request) {
StringBuilder sortUrl = new StringBuilder("/search/list");
…………
for (String key:parameters.keySet()){
url.append(key).append("=").append(parameters.get(key)[0]).append("&");
if (!("sortField".equalsIgnoreCase(key)||"sortRule".equalsIgnoreCase(key))){
sortUrl.append(key).append("=").append(parameters.get(key)[0]).append("&");
}
}
url.deleteCharAt(url.length()-1);
sortUrl.deleteCharAt(sortUrl.length()-1);
}
return new String[]{url.toString().replace(" ","+"),
sortUrl.toString().replace(" ","+")};
}
这样就可以实现排序了。
分页
分页的功能后端我们已经实现过了,现在要做的就是在前端去实现分页的显示。所以我们需要一些基本的分页信息,总页数当前页等。这些信息封装在了Page类中,所以我们首先要将Page添加到SearchEntity中。在SkuEsServiceImpl的searchByKeywords方法中添加Page对象。
Page<SkuInfo> pageInfo = new Page<>(skuInfos.getTotalElements(),
skuInfos.getPageable().getPageNumber()+1,
skuInfos.getPageable().getPageSize());
searchEntity.setPageInfo(pageInfo);
第一个参数是总页数,第二个参数是当前页,getPageNumber()是从0开始的,所以需要+1,第三个参数是每页显示的条数。然后就是在前端页面显示了:
<ul>
<li th:class="${result.pageInfo.currentpage}==1?'prev disabled':'prev'">
<a th:href="@{${result.url}(searchPage=${result.pageInfo.upper})}">«上一页a>
li>
<li th:each="i:${#numbers.sequence(result.pageInfo.lpage,result.pageInfo.rpage)}"
th:class="${result.pageInfo.currentpage==i ? 'active' : ''}">
<a th:href="@{${result.url}(searchPage=${i})}" th:text="${i}">a>
li>
<li th:class="${result.pageInfo.currentpage==result.pageInfo.last}?'next disabled':'next'">
<a th:href="@{${result.url}(searchPage=${result.pageInfo.next})}">下一页»a>
li>
ul>
显示页码信息从pageInfo中取。点击事件就是拼接url,将所需的searchPage拼接到url中。但是为了避免以下情况:
![]()
后端返回到前端的url信息中不应该包含searPage,所以我们在getUrl()方法中拼接字符串的时候把searchPage过滤掉。这样分页功能就大功告成啦!
商品详情页面
这个功能视频上没有,让我们照着讲义自己做,但是讲义给的Vue代码是有问题的,

就是这一部分,sku和spec是没有值的,但是我不会Vue,不知道怎么从skuList中取值。然后我就把sku从后端拿到然后存到map中。然后这里写成
data: {
return {
skuList: [[${skuList}]],
sku: [[${sku}]],
spec: {}
}
},
这样确实可以取出sku的值。但是{{sku.name}}和{{sku.price}}。咱也不懂Vue,不知道咋回事,就直接用th:text取值了,没用Vue的方式。
这里面有个要注意的点,就是把src="./ href="./里面的点删掉,不然样式加载不了。
Canal监听生成静态页
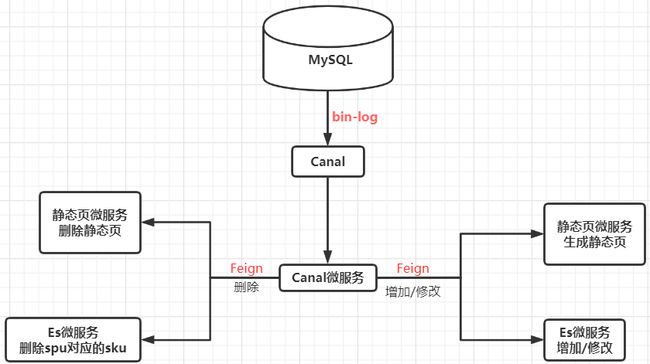
这个是我画的流程图,代码就不贴了,想要的小伙伴去Github下载即可。
小结
这篇文章的内容有点多,先是介绍了Thymeleaf的基本使用。然后实现了搜索页面以及商品详情页面。最后使用Canal来监听数据库变化,从而修改生成新的静态页以及修改Es数据。
如果我的文章对你有些帮助,不要忘了点赞,收藏,转发,关注。要是有什么好的意见欢迎在下方留言。让我们下期再见!
