spark job提交流程源码
目录
#Job提交流程概览
#Task类型
1.Task
2.DAGTask
3.ResultTask
4.ShuffleMapTask
#Stage划分
sc.runJob
DAGScheduler.runJob
submitStage()
getMissingParentStages()
getShuffleMapStage()
#Task提交
submitMissingTasks()
submitTasks()
#小结
#Job提交流程概览
spark是早期代码,流程大致如下

job提交流程:
1.当程序中出现action()类算子时,会触发job的生成,可能生成别的数据类型(非RDD),或写入别的文件系统
2.sc.runJob(finalRDD)最终会调用DAGSchedule.runJob(finalRDD),会生成finalStage,newStage(finalRdd, None),None表示不发生shuffle
3.然后调用submitStage(finalStage),会先调用getMissingParentStages(finalStage)获取finalStage还未运行的父Stage,该方法也会切分Stage,如果有未运行的父Stage,会先提交父Stage,submitStage(父Stage)也会先获取未运行的父Stage,也就是说只有Stage的所有父Stage全部运行后,才可以提交该Stage。
4.如果Stage的父Stage已全部提交,会调用submitMissingTasks(stage),提交该stage的Task,会判断是否是ResultTask,是的话生成new ResultTask(),否则new ShuffleMapTask(),将生成的Task加入HashSet()中,接下来submitTasks(HashSet())
5.如果模式为local或mesos,会调LocalScheduler或MesosScheduler,会调threadPool.submit(),其中threadPool为 Executors
生成,至此整个job提交完成。
#Task类型
spark的最小执行单元Task,
当发生shuffle依赖时,会切分stage,每个stage的task数量,由该stage最后rdd的partition数量决定,
task有两种,shufflemaptask和resulttask,resulttask是finalstage,也就是需要将结果返回给driver的stage,而
shufflemaptask无需将结果返回,需要将结果shuffle后传给后面的shufflemaptask或者resulttask,类似与
mapreduce的mapper,shuffle完后将数据传给reducer。
1.Task
class TaskContext(val stageId: Int, val splitId: Int, val attemptId: Int)
extends Serializable
abstract class Task[T] extends Serializable {
def run(id: Int): T//运行该task
def preferredLocations: Seq[String] = Nil//获取优先位置
def generation: Option[Long] = None//当fetch数据失败时,该值+1
}TaskContext有三个类参数,分别为:
stageId,表示该task属于哪个stage
splitId,RDD的partition
attemptId,运行Id
2.DAGTask
为Task的子类
abstract class DAGTask[T](val runId: Int, val stageId: Int) extends Task[T] {
//getGeneration通过请求worker或master来获取当前的generation数
val gen = SparkEnv.get.mapOutputTracker.getGeneration
override def generation: Option[Long] = Some(gen)
}3.ResultTask
为DAGTask的子类
class ResultTask[T, U](
runId: Int,
stageId: Int,
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
val partition: Int,
locs: Seq[String],
val outputId: Int)
extends DAGTask[U](runId, stageId) {
val split = rdd.splits(partition)//获取分区
override def run(attemptId: Int): U = {
val context = new TaskContext(stageId, partition, attemptId)
//实例化一个TaskContext对象
func(context, rdd.iterator(split))
//返回一个方法,参数为TaskContext对象,rdd的某个分区数据
}
override def preferredLocations: Seq[String] = locs
override def toString = "ResultTask(" + stageId + ", " + partition + ")"
}可以看到ResultTask的run()方法返回的是一个用于计算某个rdd分区方法,方法可以是count(),take()等,直接计算出结果
4.ShuffleMapTask
class ShuffleMapTask(
runId: Int,
stageId: Int,
rdd: RDD[_],
dep: ShuffleDependency[_,_,_],
val partition: Int,
locs: Seq[String])
extends DAGTask[String](runId, stageId)
with Logging {
val split = rdd.splits(partition)
override def run (attemptId: Int): String = {
val numOutputSplits = dep.partitioner.numPartitions //获取分区数
//将参数强转
val aggregator = dep.aggregator.asInstanceOf[Aggregator[Any, Any, Any]]
val partitioner = dep.partitioner.asInstanceOf[Partitioner]
//创建一个长度为分区数的数组
val buckets = Array.tabulate(numOutputSplits)(_ => new JHashMap[Any, Any])
for (elem <- rdd.iterator(split)) {//遍历rdd分区的元素
val (k, v) = elem.asInstanceOf[(Any, Any)]
var bucketId = partitioner.getPartition(k)//决定该元素去往后一个rdd的哪个分区
val bucket = buckets(bucketId)//取数组下标为bucketId的数据
var existing = bucket.get(k)//通过key获取value
if (existing == null) {//如果为空
bucket.put(k, aggregator.createCombiner(v))//新建累加器,将k,v放入
} else {
bucket.put(k, aggregator.mergeValue(existing, v))//否则,直接将v放入累加器
}
}
val ser = SparkEnv.get.serializer.newInstance()
for (i <- 0 until numOutputSplits) {
//创建文件,准备写数据
val file = SparkEnv.get.shuffleManager.getOutputFile(dep.shuffleId, partition, i)
//创建写入文件数据的流
val out = ser.outputStream(new FastBufferedOutputStream(new FileOutputStream(file)))
out.writeObject(buckets(i).size)//先写入每个数组(分区)的元素数
val iter = buckets(i).entrySet().iterator()
while (iter.hasNext()) {//遍历,将数组数据写往对应的分区文件
val entry = iter.next()
out.writeObject((entry.getKey, entry.getValue))
}
out.close()
}
return SparkEnv.get.shuffleManager.getServerUri
//返回uri,等待后续task拉取数据
}
override def preferredLocations: Seq[String] = locs
override def toString = "ShuffleMapTask(%d, %d)".format(stageId, partition)
}可以看到ShuffleMapTask返回的是一个uri,等待后续的task拉取数据,
该方法主要分为两步,
第一步遍历rdd分区中数据,根据partitioner(可查看上一篇了解分区器的两种类型)决定分区中数据去往后续rdd的哪个分区,
并将去往同一分区的数据写入下标相同的数组
第二步遍历数组,按分区写入对应的文件(当后续rdd有n个分区时,会写n个文件),返回uri,等待后续节点拉取数据
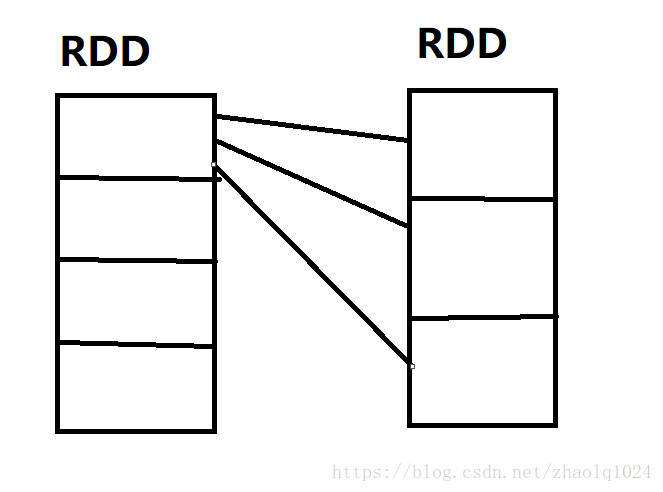
如图所示,假设父RDD有4个分区,子RDD由3个分区,当父RDD第一个分区,调用run()方法时,
会先创建一个长度为3的数组,遍历分区元素,通过partitioner决定元素去往下标为0或1或2的位置,然后写入数组,
接下来创建3个文件,将数据数据写入对应的文件,返回uri,等待fetch
#Stage划分
当发生shuffle时,sc.runJob-->DAGScheduler.runJob-->submitStage(),提交stage时,
会首先判断是否有未运行的父stage,如果没有调用submitMissingTasks提交stage
如果有则调用submitStage()先提交父stage
sc.runJob
当有action算子时,会调用sc.runJob方法,下图是在早期源码中搜sc.runJob的结果
我们去SparkContext看下runJob方法:
def runJob[T, U: ClassManifest](rdd: RDD[T], func: Iterator[T] => U): Array[U] = {
//fun:参数为迭代器
runJob(rdd, func, 0 until rdd.splits.size, false)
}
def runJob[T, U: ClassManifest](rdd: RDD[T], func: (TaskContext, Iterator[T]) => U): Array[U] = {
//fun:参数为TaskContext实例和迭代器
runJob(rdd, func, 0 until rdd.splits.size, false)
}
def runJob[T, U: ClassManifest](
rdd: RDD[T],
func: Iterator[T] => U,
partitions: Seq[Int],
allowLocal: Boolean
): Array[U] = {
runJob(rdd, (context: TaskContext, iter: Iterator[T]) => func(iter), partitions, allowLocal)
}
def runJob[T, U: ClassManifest](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
allowLocal: Boolean
): Array[U] = {
logInfo("Starting job...")
val start = System.nanoTime//提供相对精确的计时
val result = scheduler.runJob(rdd, func, partitions, allowLocal)
logInfo("Job finished in " + (System.nanoTime - start) / 1e9 + " s")
result
}
可以看到有四个重载的方法,但最终都会调用第四个,从第四个可以看到调用了scheduler.runJob方法
private var scheduler: Scheduler = {
//正则表达式
val LOCAL_N_REGEX = """local\[([0-9]+)\]""".r
val LOCAL_N_FAILURES_REGEX = """local\[([0-9]+),([0-9]+)\]""".r
master match {
case "local" => //如果是local,创建一个线程的本地调度器,失败重试
new LocalScheduler(1, 0)
case LOCAL_N_REGEX(threads) => //如果是local[n],创建n个线程的本地调度器
new LocalScheduler(threads.toInt, 0)
case LOCAL_N_FAILURES_REGEX(threads, maxFailures) =>//如果是local[n,m],m为重试次数
new LocalScheduler(threads.toInt, maxFailures.toInt)
case _ =>//否则创建mesos调度器
MesosNativeLibrary.load()
new MesosScheduler(this, master, frameworkName)
}
}
DAGScheduler.runJob
因为MesosScheduler和LocalScheduler都继承了DAGScheduler,直接去看DAGScheduler的runJob
代码有点多,就贴重要的出来
override def runJob[T, U](
finalRdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
allowLocal: Boolean)
(implicit m: ClassManifest[U]): Array[U] = {
lock.synchronized {
....定义的变量,数组,集合
submitStage(finalStage)
....
}
submitStage()
接下来看submitStage()方法,
该方法主要先判断waiting(HashSet存储等待运行的stage)和running(HashSet存储正在运行的stage)是否包含该stage,
如果都不包含,则调用getMissingParentStages获取该stage还未运行的父stage,
如果没有未运行的父stage,调用submitMissingTasks提交stage,并将stage加入running列表
如果有未运行的父stage,先提交父stage运行,并将stage加入waiting
def submitStage(stage: Stage) {
if (!waiting(stage) && !running(stage)) {
val missing = getMissingParentStages(stage)
if (missing == Nil) {
logInfo("Submitting " + stage + ", which has no missing parents")
submitMissingTasks(stage)
running += stage
} else {
for (parent <- missing) {
submitStage(parent)
}
waiting += stage
}
}
}
getMissingParentStages()
接下来先看getMissingParentStages方法,该方法主要用于获取stage未运行的父stage,划分stage
visit()方法首先遍历未被划分stage的rdd的依赖,
如果是shuffle依赖,调用getShuffleMapStage获取父stage,
如果是窄依赖,继续调用visit()方法,直到发生shuffle
可以看出stage与父stage划分的依赖就是是否发生shuffle
def getMissingParentStages(stage: Stage): List[Stage] = {
val missing = new HashSet[Stage]//存储未运行的父stage
val visited = new HashSet[RDD[_]]//存储已经划分stage的RDD
def visit(rdd: RDD[_]) {
if (!visited(rdd)) {//首先判断是否划分过
visited += rdd//添加到集合
val locs = getCacheLocs(rdd)
for (p <- 0 until rdd.splits.size) {//遍历分区
if (locs(p) == Nil) {
for (dep <- rdd.dependencies) {//遍历依赖
dep match {
case shufDep: ShuffleDependency[_,_,_] =>//shuffle依赖
val stage = getShuffleMapStage(shufDep)//获取父stage
if (!stage.isAvailable) {
//isAvailable判断为真的条件是:无父stage并且无shuffle依赖
missing += stage//将stage加入为运行的父stage队列
}
case narrowDep: NarrowDependency[_] =>//窄依赖
visit(narrowDep.rdd)//父rdd继续调用visit方法
}
}
}
}
}
}
visit(stage.rdd)
missing.toList
}
getShuffleMapStage()
接下来看getShuffleMapStage()方法,该方法是发生shuffle时获取父stage,
shuffleToMapStage是HashMap存储(shuffleId,stage)键值对,首先取key为该shuffleId的值
有值,直接返回取到的stage
无值,新建Stage并将该stage加入shuffleToMapStage中
def getShuffleMapStage(shuf: ShuffleDependency[_,_,_]): Stage = {
shuffleToMapStage.get(shuf.shuffleId) match {
case Some(stage) => stage
case None =>
val stage = newStage(shuf.rdd, Some(shuf))
shuffleToMapStage(shuf.shuffleId) = stage
stage
}
}
#Task提交
当stage所有的父stage都已经运行,则调submitMissingTasks(stage)方法,
submitMissingTasks()
val pendingTasks = new HashMap[Stage, HashSet[Task[_]]]
val finalStage = newStage(finalRdd, None)
val numOutputParts: Int = partitions.size//分区个数
val finished = new Array[Boolean](numOutputParts)//存储已经运行的分区,一个分区对应一个task
val outputParts = partitions.toArray//分区
def submitMissingTasks(stage: Stage) {
//pendingTasks存储的是stage未运行的task集合
val myPending = pendingTasks.getOrElseUpdate(stage, new HashSet)
var tasks = ArrayBuffer[Task[_]]()//存储要提交的task
if (stage == finalStage) {//判断是否是finalStage
for (id <- 0 until numOutputParts if (!finished(id))) {//遍历找出未运行的分区下标
val part = outputParts(id)//通过下标找到分区
val locs = getPreferredLocs(finalRdd, part)//获取优先位置
//创建一个ResultTask,加入到要提交的task数组中
tasks += new ResultTask(runId, finalStage.id, finalRdd, func, part, locs, id)
}
} else {
//如果不是finalStage
for (p <- 0 until stage.numPartitions if stage.outputLocs(p) == Nil) {
//遍历分区,如果某个分区没有输出位置
val locs = getPreferredLocs(stage.rdd, p)//获取优先位置
//创建一个ShuffleMapTask
tasks += new ShuffleMapTask(runId, stage.id, stage.rdd, stage.shuffleDep.get, p, locs)
}
}
myPending ++= tasks //将tasks加到未运行的tasks集合
submitTasks(tasks, runId)//提交tasks
}
可以看到,如果stage是finalStage,则创建一个ResultTask,直接返回一个结果,如果不是finalStage,创建一个ShuffleMapTask,将计算完的数据写入磁盘,等待后续task拉取
submitTasks()
接下来我们去看submitTasks()方法,
我看的是早期代码,用的是mesos调度,关于mesos调度的细节可以下载源码了解
private val activeJobs = new HashMap[Int, Job]//存储jobId,new SimpleJob()
private var activeJobsQueue = new ArrayBuffer[Job]
private val jobTasks = new HashMap[Int, HashSet[String]]//存储jobId,task集合
def submitTasks(tasks: Seq[Task[_]], runId: Int) {
logInfo("Got a job with " + tasks.size + " tasks")
waitForRegister()//等待mesos注册
this.synchronized {
val jobId = newJobId()//生成jobId
val myJob = new SimpleJob(this, tasks, runId, jobId)//创建SimpleJob实例
activeJobs(jobId) = myJob//加入Map中
activeJobsQueue += myJob//加入变长数组
logInfo("Adding job with ID " + jobId)
jobTasks(jobId) = HashSet.empty[String]
}
driver.reviveOffers();//请求资源执行myjob
}
创建了SimpleJob实例后,就请求执行了。
#小结
val data=sc.parallelize(List("tom","jerry","zlq","wnn","hehe","eason"),2)
val mapd=data.map(x=>(x.length,1))
val redd=mapd.reduceByKey(_+_,3)//3为新RDD的分区数
val coud=redd.collect()
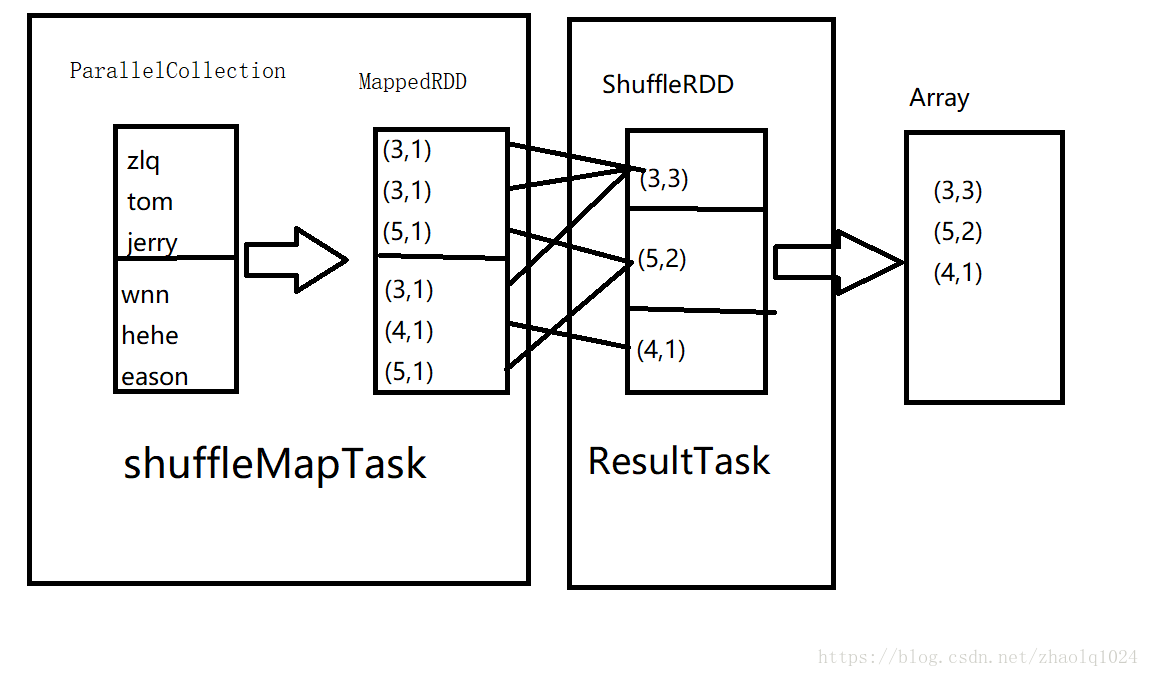
1.首先创建ParallelCollection(也继承RDD),分区为2,无依赖
2.然后执行map算子,生成MappedRDD,分区为2,依赖为 OneToOneDependency(ParallelCollection)
3.执行reduceByKey算子,生成ShuffleRDD,分区为3,依赖为ShuffleDependency(MappedRDD),
4.执行count算子,触发sc.runJob()-->DAGScheduler.runJob(ShuffleRDD)
创建stage:val finalStage = newStage(ShuffleRDD, None)
接下来:submitStage(finalStage),先调getMissingParentStages(finalStage)划分stage并获取父stage,
调用submitStage()提交父stage,submitMissingTasks(父stage)创建一个ShuffleMapTask,生成三个本地文件,等待ResultTask拉取。