msql优化--索引优化
关于数据库优化指标主要为:响应时间,扫描行数,返回行数。对于响应时间,主要体现在服务器级别,服务器性能,网络响应速度等;索引主要为了减少扫描行数;根据limit来限制返回行数。
常用的索引有:B-Tree索引,哈希索引,空间索引,全文索引。除此之外,按照数据存储方式可以分为聚集索引和非聚集索引。
【索引类型】
B-Tree索引
B-tree索引按照二叉树的方式进行存储,叶子页保存着索引的值,枝节点按照一定范围进行存储索引值。mysql查询通过访问枝节点快速定位到叶子节点,通过叶子节点存储的行地址查找到磁盘中的数据,这样减少扫描数据行。
B-Tree索引的查找方式:全键值查找(遍历所有的索引值),键值范围(in语句查找等),建前缀查找(match匹配方式查找),精确某一列范围匹配另外一列,值访问索引查询(直接定位到某一个值)。
在使用B-Tree索引作为查询条件时有很多限制条件,注意这些限制条件对我们的查询优化有很多帮助,下面通过例子的方式进行描述:


1. 在多列索引中,必须按照最左列开始查找,不然无法使用索引特性。例如上例:where条件不能使用last_name,first_name,dob的顺序进行索引查找。
2. 不能跳过索引列。例如:查询条件first_name,dob的查询将不能发挥索引特性。
3. 查询条件中部使用范围查询,则右边的条件则不能使用索引查询。例如:first_name使用了in条件查询,则last_name,dob则不是索引查询。
哈希索引
哈希索引只能精确匹配索引列值才能发挥作用,其存储结构是将索引值通过哈希算法将键值进行存储。且哈希索引支持的数据引擎是memory,我们通用的InnoDB数据引擎是无法直接支持哈希索引的,它可以通过自适应哈希索引技术模拟哈希索引的功能。
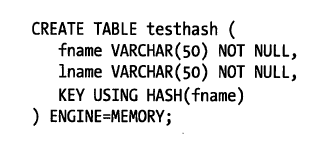
哈希索引的存储方式按照键值顺序存储,属于常数查找,存储内容与B-Tree索引相比不会存储索引列的值。因此查询时先访问索引页,然后通过行地址访问数据行,减少扫描数据行。
哈希索引的限制:
1. 索引页只包含哈希值和行指针,不包含数据值。
2. 数据行不是按照索引值的顺序来存储的,这样在排序操作时,索引列顺序和数据行顺序不一致导致性能消耗。
3. 必须匹配索引列的值,不能使用模糊匹配(like,match语句)
4. 只支持等值比较(<,>,<>则不支持)
聚簇索引
聚簇索引是InnoDB支持,但MyISAM数据引擎不支持的一种数据存储方式。它将数据行放入到索引页中,存储方式与B-Tree索引及其相似。
InnoDB通过主键来聚集数据,如果没有主键则通过唯一非空索引代替。
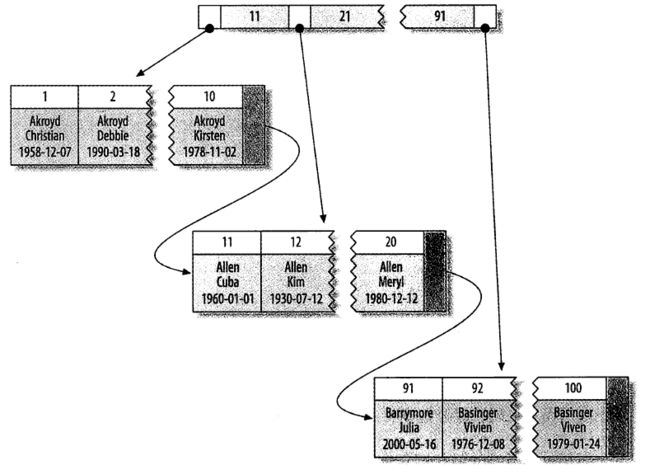
如上图,聚簇索引的索引值和数据保存在一起,这样访问速度更快。它任有一些限制:
1. 聚簇索引将数据行全部放入内存中,访问顺序不在重要了。
2. 插入顺序严重依赖杀入的位置,数据行的移动导致速度降低,因此不适合经常进入插入数据的表应用。
3. 当一个索引页无法存放所有的数据时,出现索引页断裂的问题
4. 二次索引需要扫描全表,速度下降。
【高效索引策略】
当我们了解了索引的存储特点及限制,则在建立索引的时候就能够有效的避免这些索引限制,下面我们通过如何选择索引列,索引列的数值最好具备什么样的特性,以及应用索引列的技巧进行阐述:
1. 索引要作为单独的列,不能使用表达式一部分或者函数的参数。
2. 索引列要尽可能简短,从性能考虑使用UUID作为索引列是很糟糕的!它在扫描查询,维护顺序上要消耗更多的资源。
3. 选择合适的前缀索引,在每个索引值对应的数据均匀的前提下,根据索引选择性进行判断(去重索引列值个数/总行数)
4. 对于单个索引来说,将查询出最少的数据条件放到前面。
5. 按照索引的顺序进行排序操作(可以使用explain命令,type类型是index)
6. 关联多张表时,on条件都使用索引列,order by子句都为第一个表时,才使用索引做排序。
【总结】
索引在查询提供了很大的便利,但是在更新和插入操作又带来了负担,我们最好在执行增删改操作的时候禁用索引,然后再启用。