MySQL基础——视图,触发器,存储过程
表结构
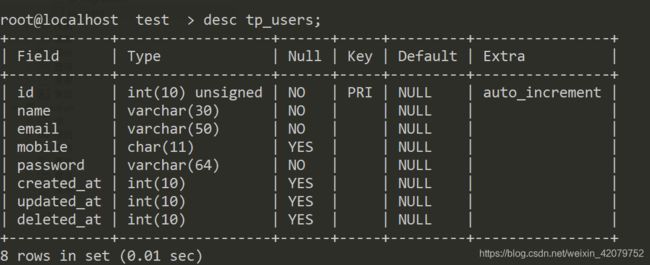
测试数据: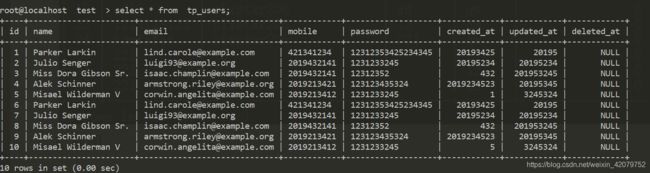 SQL
SQL
CREATE DATABASE test;
USE test;
CREATE TABLE `tp_users` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(30) COLLATE utf8mb4_unicode_ci NOT NULL,
`email` varchar(50) COLLATE utf8mb4_unicode_ci NOT NULL,
`mobile` char(11) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`password` varchar(64) COLLATE utf8mb4_unicode_ci NOT NULL,
`created_at` int(10) DEFAULT NULL,
`updated_at` int(10) DEFAULT NULL,
`deleted_at` int(10) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM AUTO_INCREMENT=11 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
INSERT INTO `test`.`tp_users` (`id`, `name`, `email`, `mobile`, `password`, `created_at`, `updated_at`, `deleted_at`) VALUES ('1', 'Parker Larkin', '[email protected]', '421341234', '12312353425234345', '20193425', '20195', NULL);
INSERT INTO `test`.`tp_users` (`id`, `name`, `email`, `mobile`, `password`, `created_at`, `updated_at`, `deleted_at`) VALUES ('2', 'Julio Senger', '[email protected]', '2019432141', '1231233245', '20195234', '20195234', NULL);
INSERT INTO `test`.`tp_users` (`id`, `name`, `email`, `mobile`, `password`, `created_at`, `updated_at`, `deleted_at`) VALUES ('3', 'Miss Dora Gibson Sr.', '[email protected]', '2019432141', '12312352', '432', '201953245', NULL);
INSERT INTO `test`.`tp_users` (`id`, `name`, `email`, `mobile`, `password`, `created_at`, `updated_at`, `deleted_at`) VALUES ('4', 'Alek Schinner', '[email protected]', '2019213421', '123123435324', '2019234523', '20195345', NULL);
INSERT INTO `test`.`tp_users` (`id`, `name`, `email`, `mobile`, `password`, `created_at`, `updated_at`, `deleted_at`) VALUES ('5', 'Misael Wilderman V', '[email protected]', '2019213412', '1231233245', '1', '3245324', NULL);
INSERT INTO `test`.`tp_users` (`id`, `name`, `email`, `mobile`, `password`, `created_at`, `updated_at`, `deleted_at`) VALUES ('6', 'Parker Larkin', '[email protected]', '421341234', '12312353425234345', '20193425', '20195', NULL);
INSERT INTO `test`.`tp_users` (`id`, `name`, `email`, `mobile`, `password`, `created_at`, `updated_at`, `deleted_at`) VALUES ('7', 'Julio Senger', '[email protected]', '2019432141', '1231233245', '20195234', '20195234', NULL);
INSERT INTO `test`.`tp_users` (`id`, `name`, `email`, `mobile`, `password`, `created_at`, `updated_at`, `deleted_at`) VALUES ('8', 'Miss Dora Gibson Sr.', '[email protected]', '2019432141', '12312352', '432', '201953245', NULL);
INSERT INTO `test`.`tp_users` (`id`, `name`, `email`, `mobile`, `password`, `created_at`, `updated_at`, `deleted_at`) VALUES ('9', 'Alek Schinner', '[email protected]', '2019213421', '123123435324', '2019234523', '20195345', NULL);
INSERT INTO `test`.`tp_users` (`id`, `name`, `email`, `mobile`, `password`, `created_at`, `updated_at`, `deleted_at`) VALUES ('10', 'Misael Wilderman V', '[email protected]', '2019213412', '1231233245', '5', '3245324', NULL);
视图
概念
视图是MySQL5.0.1版本新加入的功能,他可以理解为一个虚拟表
之所以被称为虚拟表,是因为他只是存储了一个数据结构,并不存储真实的数据,他的数据实在查询中动态生成的,
视图并不是真的优化,
视图的优点
简化了操作,我们不需要去关注视图是怎么处理数据的,我们只需要知道如何使用这个结果集即可,试图相当于一个中间层。
使用视图,可以定制用户数据,聚焦特定的数据。更加安全,比如我们可以让用户有权去访问某个视图,但是不能访问原表,这样就可以起到保护原表中某些数据的作用。
如果要加管理权限,权限是无法心细致到某一个列的,但是用过视图,很容易实现、
降低耦合,假如我们要修改原表的结构,那么我们可以通过修改视图的定义即可,而不用修改应用程序,对访问者是不会造成影响的,一般来说,代价会更小
视图的缺点
修改限制,当用户试图修改试图的某些信息时,数据库必须把它转化为对基本表的某些信息的修改,
对于简单的试图来说,这是很方便的,但是,对于比较复杂的试图,可能是不可修改的。
创建视图
CREATE VIEW [视图名] AS [sql语句];
例:
CREATE VIEW user_info_view AS SELECT id,name,email FROM tp_users;
删除视图
DROP VIEW [IF EXISTS] [视图名];
例:
DROP VIEW IF EXISTS user_info_view;
查看视图
跟表一样,视图可以用desc来查看视图的结构
DESC [视图名]
SHOW CREATE VIEW [视图名]; //查看创建视图的语法 如果感觉乱的话 可以在视图名 后加 \G
SELECT * FROM [视图名]; //查看视图内容

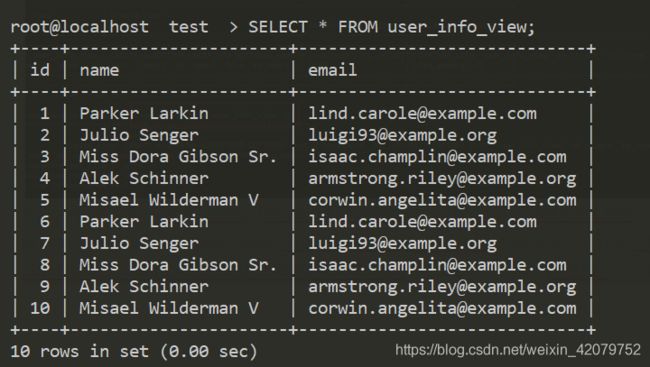
注意:视图查询的数据实则来自于源数据的内容,而他本质是一个数据结构,并不是存储真实的数据,就好比编程语言中对sql的封装(以PHP为例):
class DB
{
public function select()
{
return "sql:select id,name,email from `tp_users`";
}
}
视图的IUD
表是可以对对数据进行增删改的,但是对于视图来说 不一定
视图不可更新的情况:
- 包含聚合函数、distinct、group by 、having、union、union all。
- 常量视图
- select 包含子查询
- 包含连接操作
- form一个不能更新的视图、
- where子句的子查询引用了from子句中的表。
测试:
测试表(仅供测试)
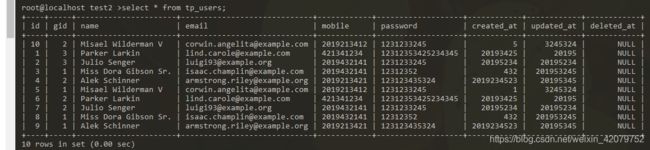

测试视图包含连表操作时:
create view user_view_2 as select a.id,a.name,b.name as groups,a.email,a.mobile from tp_users as a left join user_group as b on a.gid = b.id;
添加操作
![]()
删除操作:
![]()
修改操作:

可以发现 当视图包含连表操作,进行添加或删除时,mysql会报错提示,但是可以进行修改操作.
再此我们只做一些简单测试 有兴趣的可以自己去测试
with check option 使用
首先修改表数据方便测试:
update`tp_users` set deleted_at = unix_timestamp() where id in (1,5,7,10);

创建一个只记录删除用户的视图
CREATE VIEW del_user_view AS select * from `tp_users` where deleted_at is not null;
SELECT * FROM del_user_view;

这是如果我们向这个视图添加一个未删除的用户 也就是 deleted_at = null
INSERT INTO del_user_view(name,email,mobile,password,created_at,updated_at,deleted_at) values ('Antor Yao','[email protected]','123123','FEFQWERQWSD234234',unix_timestamp(),NULL,NULL);
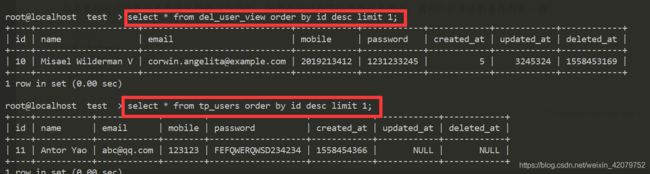
这时我们会发现可以向这个视图插入数据,但是因为不满足视图的条件,所以不会再视图中显示,但是数据已经插入基表了,但是我们有些时候我们不希望这样的情况发生,如果不满足视图的条件就不插入,这个时候就可以 使用 with check option
测试:
DROP VIEW IF EXISTS del_user_view;
CREATE VIEW del_user_view AS select * from `tp_users` where deleted_at is not null WITH CHECK OPTION;
INSERT INTO del_user_view(name,email,mobile,password,created_at,updated_at,deleted_at) values ('Antor Yao','[email protected]','123123','FEFQWERQWSD234234',unix_timestamp(),NULL,NULL);
错误信息:
![]()
可以理解为with check option 的作用就是多了一个check功能,也就是说插入的数据必须满足概述图的条件,才允许被操作
with check option也可以这么解释:通过视图进行的增/改,必须也能通过该视图看到增/改后的结果。
比如你insert,那么加的这条记录在刷新视图后必须可以看到;
如果update,修改完的结果也必须能通过该视图看到;
delete操作 不受with check option影响
总结:
with check option 使视图只能操作它可以查询出来的数据,对于它查询不出的数据,即使基表有,也不可以通过视图来操作。
1.对于update,有with check option,要保证update后,数据要被视图查询出来
2.对于delete,有无with check option都一样
3.对于insert,有with check option,要保证insert后,数据要被视图查询出来
4.对于没有where 子句的视图,使用with check option是多余的
视图应用&好处
-
1.提高了重用性,就像一个函数 如果要频繁获取user的name和goods的name。就应该使用以下sql语言。示例:
select a.name as username, b.name as goodsname from user as a,goods as b,ug as c where a.id=c.userid and c.goodsid = b.id;
但有了视图就不一样了,创建视图othe^示例
create view other as select a.name as username, b.name as goodsname from user as a, goods as b, ug as c where a.id=c.userid and c.goodsid=b.id; 创建好视图后,就可以这样获取user的name和goods的name。示例:
select * from other:
以上sql语句,就能获取user的name和goods的name 了。 -
2.对数据库重构,却不影响程序的运行 假如因为某种需求,需要将user拆房表usera和表userb,该两张表的结构如下
测试表:usera有id,name,age字段
测试表:userb有id,name,sex字段
这时如果php端使用sql语句:select * from user那就会提示该表不存在,这时该如何解决呢。解决方案:创建视图。以下sql语句创建视图:
create view user as select a.name,a.age,b.sex from usera as a, userb as b where a.name=b.name;以上假设name都是唯一的。此时php端使用sql语句: select* from user;就不会报错什么的。这就实现了更改数据库结构,不更改脚本程序的功能了。 -
3.提高了安全性能。可以对不同的用户,设定不同的视图。例如:某用户只能获取user表的name和age数据,不能获取sex数据。则可以这样创建视图。示例 如下:
create view other as select a.name, a.age from user as a;
这样的话,使用sql语句:select * from other;最多就只能获取name和age的数据,其他的数据就获取不了了。 -
4.让数据更加清晰想要什么样的数据,就创建什么样的视图。经过以上三条作用的解析,这条作用应该很容易理解了吧
触发器
触发器是与表有关的数据库对象,在满足定义条件时触发,并执行触发器中定义的语句集合。
触发器的特性:
- 有begin end体,begin end;之间的语句可以写的简单或者复杂
- 什么条件会触发:I、D、U
- 什么时候触发:在增删改前或者后
- 触发频率:针对每一行执行
- 触发器定义在表上,附着在表上。
也就是由事件来触发某个操作,事件包括INSERT语句,UPDATE语句和DELETE语句;可以协助应用在数据库端确保数据的完整性。
触发器不能与临时表或视图关联。
!!尽量少使用触发器,不建议使用。
假设触发器触发每次执行1s,insert table 500条数据,那么就需要触发500次触发器,光是触发器执行的时间就花费了500s,而insert 500条数据一共是1s,那么这个insert的效率就非常低了。因此我们特别需要注意的一点是触发器的begin end;之间的语句的执行效率一定要高,资源消耗要小。
触发器尽量少的使用,因为不管如何,它还是很消耗资源,如果使用的话要谨慎的使用,确定它是非常高效的:触发器是针对每一行的;对增删改非常频繁的表上切记不要使用触发器,因为它会非常消耗资源。
创建触发器
CREATE TRIGGER [触发器名称] [触发器执行时间] [执行的动作点] ON [表名] FOR EACH ROW [函数或动作]
执行时间: before,after
执行动作点:insert update delete
函数: begin end;
动作:update insert
FOR EACH ROW:表示任何一条记录上的操作满足触发事件都会触发该触发器,也就是说触发器的触发频率是针对每一行数据触发一次。
NEW与OLD详解
MySQL 中定义了 NEW 和 OLD,用来表示触发器的所在表中,触发了触发器的那一行数据,来引用触发器中发生变化的记录内容,具体地:
- 在INSERT型触发器中,NEW用来表示将要(BEFORE)或已经(AFTER)插入的新数据;
- 在UPDATE型触发器中,OLD用来表示将要或已经被修改的原数据,NEW用来表示将要或已经修改为的新数据;
- 在DELETE型触发器中,OLD用来表示将要或已经被删除的原数据;
使用方法:
NEW.columnName (columnName为相应数据表某一列名)
另外,OLD是只读的,而NEW则可以在触发器中使用 SET 赋值,这样不会再次触发触发器,造成循环调用
mysql> CREATE TABLE account (acct_num INT, amount DECIMAL(10,2));
mysql> INSERT INTO account VALUES(137,14.98),(141,1937.50),(97,-100.00);
mysql> delimiter $$
mysql> CREATE TRIGGER upd_check BEFORE UPDATE ON account
-> FOR EACH ROW
-> BEGIN
-> IF NEW.amount < 0 THEN
-> SET NEW.amount = 0;
-> ELSEIF NEW.amount > 100 THEN
-> SET NEW.amount = 100;
-> END IF;
-> END$$
mysql> delimiter ;
mysql> update account set amount=-10 where acct_num=137;
mysql> select * from account;
+----------+---------+
| acct_num | amount |
+----------+---------+
| 137 | 0.00 |
| 141 | 1937.50 |
| 97 | -100.00 |
+----------+---------+
mysql> update account set amount=200 where acct_num=137;
mysql> select * from account;
+----------+---------+
| acct_num | amount |
+----------+---------+
| 137 | 100.00 |
| 141 | 1937.50 |
| 97 | -100.00 |
+----------+---------+
查看触发器
1、SHOW TRIGGERS语句查看触发器信息
mysql> SHOW TRIGGERS\G;
显示所有触发器的基本信息;无法查询指定的触发器。
2、在information_schema.triggers表中查看触发器信息
mysql> SELECT * FROM information_schema.triggers\G
显示所有触发器的详细信息;同时,该方法可以加where条件查询制定触发器的详细信息。
所有触发器信息都存储在information_schema数据库下的triggers表中,可以使用SELECT语句查询,如果触发器信息过多,最好通过TRIGGER_NAME字段指定查询。
删除触发器
DROP TRIGGER [IF EXISTS] [schema_name.]trigger_name
删除触发器之后最好使用上面的方法查看一遍;同时,也可以使用database.trig来指定某个数据库中的触发器。
如果不需要某个触发器时一定要将这个触发器删除,以免造成意外操作,这很关键。
存储过程
对数据惊醒计算,分析汇总的时候,尤其是拿到别的公司数据的时候,进行转换为自己系统需要的数据和格式的时候、
一般用于公司内部系统,如 OA系统
概念
存储过程和函数可以理解为一段SQL语句的集合,他们被事先编译好并且存储在数据库中,在一些语言中,“函数” 跟“过程”是有区分的,过程可以理解为没有返回值的函数,不过在C家族中,则没有过程这个概念,同一为函数。
语法
CREATE PROCEDURE 存储过程名(参数列表)
BEGIN
存储过程体
END
call 存储过程名(参数列表)
参数类型:
- in 表示只用来输入。
- out 表示只是用来输出
- inout 表示可以用来输入,也可以用来输出
例:
DROP PROCEDURE USER_PROCEDURE;
CREATE PROCEDURE USER_PROCEDURE(INT x int , out y varchar(10)) --in表示输入
BEGIN
select name into y from `user` where is = x;
END
--执行
call user_procedure(1 , @a);
select @a;
查看存储过程信息
SHOW CREATE PROCEDURE [存储过程名];
存储过程理解
调用存储过程与直接执行SQL语句带来的效果是相同的,但是存储过程的一个好处就是处理逻辑都封装在数据库端。
当我们调用存储过程的时候,我们不需要了解其中的处理逻辑,一旦处理逻辑发生变化,只需要修改存储过程即可,对调用他的程序完全没有影响。
调用存储过程和函数可以简化应用开饭人员的很多工作,减少数据在数据库中和应用服务器之间的传输,可以提高数据处理的效率
变量
- 存储过程中是可以使用变量的,我们可以通过declare来定义一个局部变量,该变量的作用域只是在begin…end 中。
- 变量的定义必须写在开头,并且任何其他语句的前面,我们可以一次声明多个相同类类型的变量,我们还可以使用default来赋予默认值。
- 定义变量的语法为: declare 变量名1[,变量名2…] [default 默认值]
- 变量可以使用set来进行赋值。语法: set 变量名1 = 表达式1 [,变量名2=表达式2…]
- 也可以通过查询来将结果赋值给变量,他需要要求查询返回的结果只有一行,语法:select 列名 into 变量名 from 表名 其他语句;
存储过程中的数据类型
数值类型: int float double decimal
日期类型:timestamp date year
字符串 : char varchar text
timestamp 是使用最多的数据类型 -> 十位数的时间戳
text:一旦用到text类型就需要考虑分表,如果不分表的话,该字段的查询尽量不要与其他其他字段放在一起查询,因为这样容易遇到慢查询,如果需要这个值的时候可以根据id单独拿这个字段
存储过程的优点
- 执行速度块,我们的每一条SQL语句都需要经过编译,然后执行,但是存储过程都是直接编译好的,直接运行即可。
- 减少网络流量,我们传输一个存错过程比我们传输大量的SQL语句的开销要小很多
- 提高系统安全性,因为存储过程可以使用权限控制,并且参数化的存储过程可以有效地防止SQL注入攻击,保证了其安全性
- 耦合性降低,当我们的表结构反升了调整或变动之后,我们可以修改相应的存储过程,我们的应用程序在一定程度上需要改动的地方就较小了
- 重用性强,因为我们写好一个存储过程之后,再次调用它只需要一个名称即可,也就是一次编写,随处调用,而且使用存储过程也可以让程序的模块化加强
存储过程的缺点
- 移植性差,存储过程是跟数据库绑定的,如果我们要更换数据库之类的操作,可能很多地方需要改动
- 修改不方便,对于存储过程而言,我们并不能特别有效地调试,他的一些bug可能发现的更晚一些,增加了应用的危险性
- 优势不明显和赘余功能,对于小型应用来说,如果我们使用语句缓存,发现编译SQL的开销并不大,但是使用存储过程区需要检查权限一类的开销,这些赘余功能也会在一定程度上拖累性能
阿里巴巴的开发手册上有专门规定禁止使用存储过程
流程控制语句
if 语法:
if 条件表达式 then 语句
[elseif 条件表达式 then 语句]...
[else 语句]
end if
case 语法:
1.
case 表达式
when 值 then 语句
when 值 then 语句
...
[else 语句]
end case;
2.
case
when 表达式 then 语句
when 表达式 then 语句
...
[else 语句]
end case;
loop 循环 语法:
[标号:] loop
循环语句
end loop [标号];
Loop
sql 语句
所有的条件判断和跳出都需要自己实现
end loop;
while 语句:
while 条件 do
循环语句
end while:
Repeat 游标:
Repeat
SQL语句1
UNTIL 条件表达式
end Repeat;
leave 用来从标注的流程构造中退出,他通常跟 begin...end 或循环一起使用
leave 标号;
声明语句结束符,可以自定义:
delimiter 符号;
游标
有的资料也叫光标
我们可以在存储过程中使用游标来对结果集进行循环的处理
有标的使用步骤基本分为:声明 打开 取值 关闭。
语法:
DECLARE 游标名 CURSOR FOR 结果集;//声明游标
OPEN 游标名;//打开游标
FETCH 游标名 into 变量名1[,变量名2...] //获取游标数据
CLOSE 游标名;//关闭游标
DECLARE CONTINUE HANDLER FOR NOT FOUND //结果集查询不到数据自动跳出
对某个表按照循环处理,判断训话那结果的条件是捕获not found 的条件 ,当fetch 光标找不到下一条记录的时候,就会关闭光标,然后退出过程。
在SQL中 我们使用declare定义的顺序是:变量 条件 游标 应用程序
例:
delimiter $$
create procedure exchange(out count int )
begin
declare supply_id1 int default 0;
declare amount int default 0;
--游标标识
declare blag int default 1;
--游标
declare order_cursor cursor for select supply_id,amount from order_group;
--not found 这个异常进行处理
declare continue handler for not found set blag = 0;
set count = 0;
--打开游标
open order_cursor;
--遍历
read_loop:loop
fetch order_cursor into supply_id1,amount1;
if blag = 0 then
leave read_loop;
end if;
if supply_id1 = 1 then
set count = count+amount1;
end if;
end loop read_loop;
end;
$$
delimiter;
call exchange(@count);
select @count;