神经网络的结构与加速
本文是在准备一个文献阅读报告时,对相关论文内容的一个梳理,除了在网络结构设计上面做文章,神经网络加速的算法也有很多,例如剪枝,知识蒸馏等,奈何数学基础很烂,上述方法一时还不能很好领会,所以本文以 ImageNet 比赛为时间主线,来探寻近年来网络结构的变化(所以重点在结构变化,会选择性忽略一些训练技巧及特点),若有描述不当或者理解有误的地方,欢迎留言交流!!
1.简介

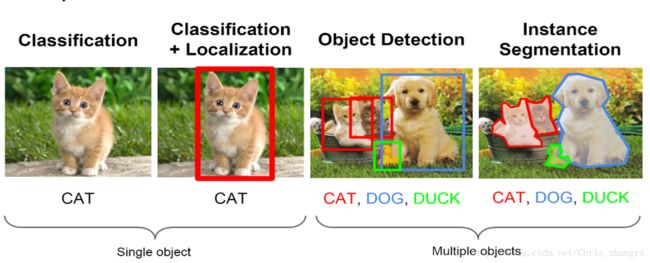
目前,深度学习在计算机视觉领域主要分为以下四个方面:
- 目标分类(classification):输入一张图片,网络可以输出图片的类别。
- 目标定位(classification+location):输入一张图片,网络不仅可以输入类别,还可以框出这个物体的位置。
- 目标检测(Object detection):输入一张包含多种物体的图片,分别输出它们的类别,并且标记它们。
- 物体分割(Instance Segmentation):在目标检测的基础上不仅要知道它们的大致位置,还要找到它们轮廓,圈出它们。
ImageNet 比赛只包含前三项,物体分割2014年推出专门的数据集就是微软 COCO[26]。

ImageNet是世界上最大的图像识别数据集,包含1500万张标注图片,是来自167个国家近5万名工作者,花费2年时间将近十亿张图片清理、分类、标记所共同完成的。
可以看到从11年到12年ImageNet比赛的结果有一个很大的提升,正是因为12年深度学习方法的提出,然后到了2015年ResNet的提出,将错误率降到了3.57%,人类水平的错误率为5.1%。16年冠军错误率为2.99%,因为在物体识别领域已经超过了人类的表现,所以在2017年,李飞飞团队宣布结束ImageNet比赛,将视角转向其他更有挑战性的领域。
2012年


AlexNet提出[1]:
1.让ReLU(Rectified Linear Unit nonlinearity)出现在大众视野
2.基于GPU训练的CUDA优化方案,分GPU训练(group训练的鼻祖)
3.用了一系列的训练技巧提升精度并加快训练速度
4.提出了5层卷积层+3层全连接层的网络结构
什么是ReLU(修正线性单元)呢?

这里我用Python小程序简单生成了两张图来帮助理解,第一张图可以用直线 y=ax+b 来拟合,将左边的数据经过ReLU后就编程了右边的样子,对这个名称最直观的理解就是,它可以将一条直线(线性)编程一条折线(非线性)。ReLU就是一个max函数,将输入的数与 0 比较大小,最后输出值。
2013年


ZFNet提出[27]:
Z,F分被是两位作者名字的首字母。
1.对AlexNet进行了细节优化,但大体框架未变,任然是8层结构,所以在网络结构的发展上很少有人得到。
2.主要贡献是卷积网络可视化,如上图所示,将5层卷积层进行了特征图的可视化,验证了特征在卷积网络中真的是从局部到整体的在提取,帮助人们深入理解神经网络,有感兴趣的同学可以下载来看一看。
2014年
感觉从2014年以后,大量优秀的工作被提出,深度学习发展加速,开始高歌猛进。


VGGNet[2]提出:
问题:
本文主要探讨了一个重要问题——深度
解决方法:
- 大量3x3卷积滤波器的使用。可以增加网络非线性以及减少参数量。
参数量的定义:输入通道数 (M)x 卷积核尺寸(K x K) x 输出通道数(N)
下图进行说明:

一层7x7卷积层,变成3层3x3卷积层,每一层卷积层后面跟一个刚才提到的ReLU,所以一个ReLU变3个ReLU,可以增加非线性。减少参数量见图中说明。



NIN[6]:
问题:
如何更好的提取特征?
解决方法:
1. 用3层小网络代替单层卷积核
2. 用了 AVE pooling 取代了FC层
a)增加特征图与类别之间的相关性
b)没有参数需要优化,避免过拟合
这里原文中说3层的MLP(多层感知机)的作用相当于一个正常卷积的1x1的卷积层,这一点还是不能很理解?
然后值得一得是,1x1卷积的有效性,包括用AVE pooling层来代替原先卷积结构中的全连接层都是来自于这篇论文。

GoogLeNet[3,4]:
GooLeNet一共有4代,如果算上最新的Xception的话有5代了,《Going Deeper with Convolutions》这是GooLeNet的第一代,在这篇论文中作者所探讨的问题和VGG是一样的,同样是网络深度与宽度的问题,并且结合多尺度融合的想法,提出了Inception的结构,同一批特征图谱经过不同分辨率的卷积核处理以后得到的特征图具有不同的感受野,再将它们concat在一起输入到下一级,增加了特征的利用率。《Rethinking the Inception Architecture for Computer Vision》则是对Inception结构第2代,第3代的一个综述。

从第2代,第3代都是15年的工作了,Inception结合了VGG大卷积分解成小卷积的思想,将Inception V1 中的 5x5 分解成2个 3x3,进一步降低参数量,还有值得一提的就是,在Inception V2的论文中,提出了Batch Normalization的训练方法,好出多多,现在基本已经成了卷积层的标配。然后在这个基础上进一步探索,如果分解成更小的卷积,例如2x2是不是效果会更好呢,通过实验,发现nxn大小的卷积分解成nx1和1xn的两个不对称的小卷积会更有效,基于这个发现,就提出了Inception V3 当中的结构,并综合运用了右边的3种结构,达到了更好的效果。
总结如下:

2015年
2015年的冠军是ResNet,是由当时还在微软的何凯明大神提出的。

本文首先提出一个问题,根据前几年ImageNet比赛的经验,是不是网络越深,性能就越好呢? 答案是否定的。上面截图中可以看到,红色曲线是一个56层的网络,而黄色的线是一个20层的网络。在CIFAR-10上面做了训练对比,可以看到,传统的网络结构56层的性能反而没有20层的好。由此呢,第二个问题就出来了。怎么样在增加深度的基础上最起码不会让性能变差的? 基于这个问题本文提出了意义深远的残差结构。也就是我们常说的跨层连接,有效的缓解了常规的网络结构随着层数增加,性能退化的问题。


通过跨层连接,可以使网络需要学习的部分对输出的变化更加的敏感,也可以更集中精力去学习输入和输出的差异部分。
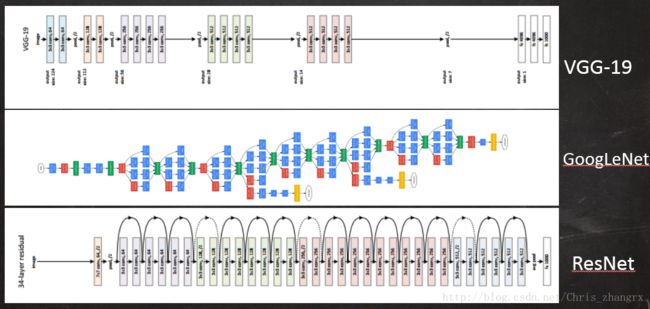
VGG ,GooLeNet , ResNet 结构的对比:
2015年以后
后续工作很多大家思想都是相互学习,时间线有点乱,所以同意归结成2015年以后的工作。

ResNeXt[29]:
本文是在ResNet的基础上(跨层连接可以看成是一个两分支的结构),从GoogLeNet系列的结构中寻找灵感,是不是多分支结构会更有效? 基于这个想法提出了何凯明等人呢(此时已经在Facebook了)提出了ResNeXt结构。
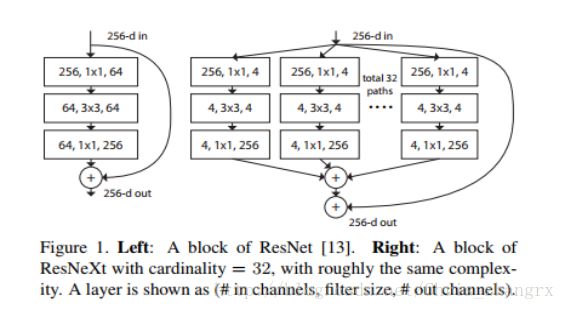
由上图可以看到,本文将左边的两分支结构编程了右边的33分支结构,为了更易扩展,整个网络都统一了结构。效果相对ResNet有了进一步的提升。

Xception[28]:
在GoogLeNet 4分支的基础上,也继续探索增加分支数是不是会更好的提升网络的性能,而分支数的极限情况就是每一个通道的特征图谱都对应一个卷积层,这中极限情况就和分步卷积不谋而合。这里不同的是正常分步卷积是先DepthWise分通道卷积以后,用1x1卷积进行通道间的混合,这里是先用1x1卷积分离通道,然后在在独立通道的特征图上进行空间卷积。
