SQL Server导入性能对比(1)——WITH TABLOCK并行导入
随着大数据和大量数据系统的出现,数据的加载变得越来越重要,很多岗位甚至只需要ETL技能,不过今时今日数据加载已经不再是单纯的ETL,还有ELT,甚至不需要进行数据移动的计算等等。
本文先把精力放在传统的ETL上。介绍几种数据加载的过程和对比。
本系列文章包含本文及:
SQL Server导入性能对比(2)——非聚集列存储索导入
SQL Server导入性能对比(3)——In-Memory搭配聚集列存储索引
常规数据加载方式
数据加载的本质就是把数据插入特定的地方,通常我们关注的是性能,说白了就是插入完成的时间,及引起的空间消耗。
本文及后面两篇文章将介绍和演示几种常规的插入方式,包括:
- 带有WITH (TABLOCK)的INSERT SELECT
- 非聚集列存储索引
- In-Memory搭配聚集列存储索引
INSERT SELECT with(TABLOCK)
使用这种方式,可以实现并行插入,目标表可以是聚集列存储索引,但是也可以是堆表。但是我们把目光放到列存储索引上,因为从上一篇文章中可以看到,列存储索引确实有好处,而且因为我目前使用的是Azure SQL DB,底层来说已经是SQL 2019的功能,所以我暂时不讨论堆表。
这种并行功能从SQL 2016开始引入,也就是2014并没有这个并行得功能。不管有多少个cores,insert into到聚集列存储索引都是使用单一的core进行,一开始先顺序填满Delta-Store,直到达到了第一个可用Delta-Store的最小可用行数(1048576行)。然后开始下一个Delta-Store。
在INSERT SELECT过程中,不管SELECT部分多高效,INSERT性能都将成为最慢的部分。但是这种设计是为了保证最后的哪个Delta-Store不会被完全填满,然后在后续载入更多的数据。
从SQL 2016(兼容级别是130或以上)开始,当带上WITH (TABLOCK)是,可以实现并行插入。根据当前CPU和内存资源,每个CPU core都对应一个独立的Delta-Store,使得数据的载入更加快。理论上说,如果磁盘的能力和大小足够大,那么core越多,相比起2014,性能也就成倍增加。但是正如前面说的,2014中,最后一个Delta-Store需要整理,在2016中,就是有N个Delta-Store需要整理,这是它的缺点,不过可以通过一些手段来缓解,比如重组索引。
上面的版本区别还需要考虑兼容级别,如果你安装SQL 2016但是兼容级别小于130,那么本质上还是等于使用低于2016的版本。
下面我们用ContosoRetailDW库来演示一下。先清理一下上面FactOnlineSales的主键和外键约束,然后创建一个聚集的列存储索引:
use ContosoRetailDW;
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimCurrency]
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimCustomer]
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimDate]
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimProduct]
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimPromotion]
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimStore]
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [PK_FactOnlineSales_SalesKey];
create clustered index PK_FactOnlineSales on dbo.FactOnlineSales( OnlineSalesKey ) with ( maxdop = 1);
create clustered columnstore Index PK_FactOnlineSales on dbo.FactOnlineSales with( drop_existing = on, maxdop = 1 );
然后创建一个测试表,
CREATE TABLE [dbo].[FactOnlineSales_CCI](
[OnlineSalesKey] [int] NOT NULL,
[StoreKey] [int] NOT NULL,
[ProductKey] [int] NOT NULL,
[PromotionKey] [int] NOT NULL,
[CurrencyKey] [int] NOT NULL,
[CustomerKey] [int] NOT NULL,
INDEX PK_FactOnlineSales_CCI CLUSTERED COLUMNSTORE
);
然后从FactOnlineSales中把1000万数据导入到上面的测试表,但是这个时候不指定WITH (TABLOCK)使其不强制使用并行插入,同样我开启了实际执行计划和SET STATISTICS IO和TIME的选项,用于获取一些执行信息:
set statistics time, io on;
insert into [dbo].[FactOnlineSales_CCI] (OnlineSalesKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey)
select distinct top 10000000 OnlineSalesKey, store.StoreKey, sales.ProductKey, PromotionKey, CurrencyKey, CustomerKey
FROM [dbo].[FactOnlineSales] sales inner join dbo.DimProduct prod on sales.ProductKey = prod.ProductKey
inner join dbo.DimStore store on sales.StoreKey = store.StoreKey
where prod.ProductSubcategoryKey >= 10 and store.StoreManager >= 30
option (recompile);

SQL Server parse and compile time:
CPU time = 6020 ms, elapsed time = 6312 ms.
Table 'FactOnlineSales'. Scan count 4, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 12023, lob physical reads 40, lob page server reads 0, lob read-ahead reads 30079, lob page server read-ahead reads 0.
Table 'FactOnlineSales'. Segment reads 13, segment skipped 0.
Table 'DimStore'. Scan count 5, logical reads 67, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table 'DimProduct'. Scan count 5, logical reads 370, physical reads 1, page server reads 0, read-ahead reads 126, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table 'FactOnlineSales_CCI'. Scan count 0, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.


在我的环境下用了大概71秒完成插入,同时执行计划显示是串行的。这个可以在运算符的属性中看到只有1个线程来做这件事。我们还可以算一下使用了大概(1000万除以1048576)个行组来存放,最后一个行组是多出来的没填满的数据行。用下面的语句可以验证:
select *
from sys.column_store_row_groups
where object_schema_name(object_id) + '.' + object_name(object_id) = 'dbo.FactOnlineSales_CCI'
order by row_group_id asc;

接下来清掉测试表,然后使用WITH(TABLOCK)来再跑一次,注意WITH(TABLOCK)是在目标表,而不是在源表,另外先执行一下升级兼容级别确保能使用SQL 2016的新特性,在本人环境中这个库是2008的兼容级别:
USE [master]
GO
ALTER DATABASE [ContosoRetailDW] SET COMPATIBILITY_LEVEL = 130
GO
set statistics time, io on;
insert into [dbo].[FactOnlineSales_CCI] with(TABLOCK) (OnlineSalesKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey)
select distinct top 10000000 OnlineSalesKey, store.StoreKey, sales.ProductKey, PromotionKey, CurrencyKey, CustomerKey
FROM [dbo].[FactOnlineSales] sales inner join dbo.DimProduct prod on sales.ProductKey = prod.ProductKey
inner join dbo.DimStore store on sales.StoreKey = store.StoreKey
where prod.ProductSubcategoryKey >= 10 and store.StoreManager >= 30
option (recompile);
这次时间从71秒降到40秒。

SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 2 ms, elapsed time = 2 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 132 ms, elapsed time = 132 ms.
Table 'FactOnlineSales'. Scan count 4, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 11237, lob physical reads 17, lob page server reads 0, lob read-ahead reads 26733, lob page server read-ahead reads 0.
Table 'FactOnlineSales'. Segment reads 13, segment skipped 0.
Table 'DimProduct'. Scan count 5, logical reads 370, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table 'DimStore'. Scan count 5, logical reads 67, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table 'FactOnlineSales_CCI'. Scan count 0, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
(10000000 行受影响)
(1 行受影响)
SQL Server Execution Times:
CPU time = 101093 ms, elapsed time = 39771 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
然后查看一下实际执行计划,提醒一下,并行操作只能从实际执行计划中看到,预估执行计划是不显示的。下图可以看到用了4个线程,因为我的环境只有4个core,然后并行为“True”。

检查一下行组信息,这次是12行,而不是前面的10行。最后四行被平均分布在独立的行组中用于后续的“修剪”,前面提到过,并行会导致更多的最终行组需要处理,这里的四行就是例子,如果你的core很多,那么也会有同样多的行。这些会影响性能,但是如果整体性能反而有明显提升,那么这种开销是可以接受的。
select *
from sys.column_store_row_groups
where object_schema_name(object_id) + '.' + object_name(object_id) = 'dbo.FactOnlineSales_CCI'
order by row_group_id asc;
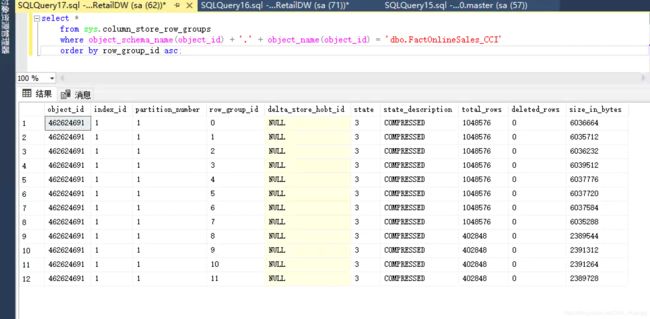
最大的可并行数为可用的core数量-1。
总结
本文演示了对比较大量的数据使用insert select命令导入时,如果是SQL 2016即兼容级别是130或以上版本,可以通过添加WITH(TABLOCK)来并行插入。
并行插入可以明显提高性能,不过代价就是你要修剪更多的元组,这个可以通过索引重建来完成,后面会演示。
下一文将继续,演示关于非聚集列存储索引在数据导入方面的提升。