4.3.2无监督学习(四) - 序列模式与AprioriAll算法
简介
关联分析为了寻找数据各个特征之间的关联影响关系。关联关系并不是因果关系,它表示的是特征A出现与特征B出现之间的影响关系。关联分析通常可以分为关联规则(Association Rules)与序列模式(Sequence Pattern Mining)。其中,序列模式算法中最基本的是AprioriAll算法。
一句话解释版本:
序列模式就是有时间顺序概念的关联规则。
数据分析与挖掘体系位置
序列模式是一种无监督学习方法,其在整个数据分析与挖掘体系中的位置如下图所示。
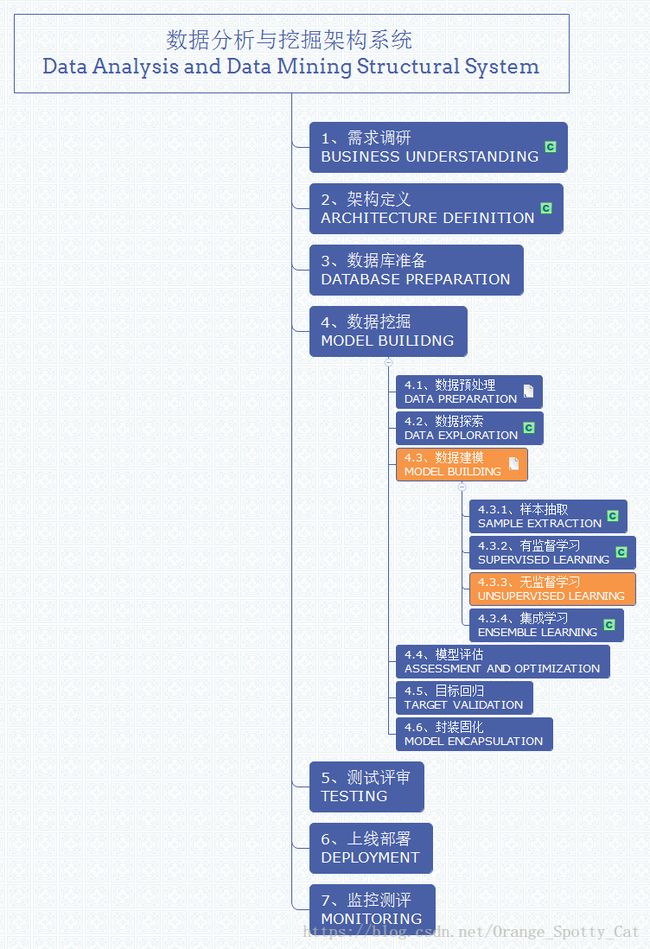
序列模式的理念
关联规则(Apriori算法)只能衡量X与Y之间的影响力大小。这种影响与时间、顺序是无关的。我们只考虑购买牛奶与购买面包的关系,但是不会考虑购买的先后顺序与购买的时间。举例来说,在关联规则中,如果一个项集为[牛奶,面包,裙子],这个购买行为是不具有任何顺序与时间观念的。
但是序列模式不同,它是具有先后顺序概念的。也就是说,它能够考察:我在之前的购买中买了牛奶,之后的购买行为中我更有可能买面包。序列模式的挖掘带入了时间次序的概念。
序列模式的处理单元
在上一章说过:
在关联规则中,一个记录是一个项集,[牛奶,面包,蜂蜜],这就是一个项集。
在序列模式中,一个记录是一个序列,它是有序的项集。一个序列包含项的个数是序列的长度。
序列模式的基础指标
序列模式的判定指标是支持度。它的算法与关联规则略有不同。
支持度(Support)
符号:support(S) 。
定义:衡量有序项集的出现频率。表示序列S在所有数据集中出现的概率。
计算:support(S)= P(S) / C,其中C代表C次购买行为。
举例:客户的三次购买行为是{牛奶,面包,蜂蜜},{豆浆,牛奶,面包},{面包,牛奶,蜂蜜}。则,support(牛奶->面包)=2/3.
注:序列不一定是连续、紧接着发生,只要符合时间先后顺序就可以。
序列模式的评判标准
序列规则的评判结果是:序列S是不是一个会频繁发生的模式。
要想确认这一点,需要设定阈值,这个阈值是
- 最小支持度(Minimum Support):序列S发生的概率至少要超过该值,S才算是频繁序列。
AprioriAll算法的原理
AprioriAll与Apriori基本是一样的,只不过Apriori是对项集做处理,而AprioriAll引入了序列的概念。
AprioriAll算法包括如下几步:
- 将原始数据集按事件、发生时间进行排序,得到各个序列。
- 设定序列最小支持度,即阈值
- 计算序列的支持度,并筛选出支持度大于阈值的序列