从零教你学会用Python爬虫
因为某个朋友问我爬虫要怎样去学, 因此, 我便打算给他写一篇文章来教ta去从零开始学会爬虫.
基础知识
在这里简单的介绍一下学习爬虫所需要的基础知识, 这里仅简单介绍入门的基本知识, 由于篇幅有限, 这里仅做简单的解释, 如果想深入学习, 大家可以利用搜索引擎, 自己去学习.
什么是爬虫?
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本 – 摘自百度百科
编程语言
在这里, 我主要介绍如何利用Python进行爬虫, 其他语言的话, 语法可能不尽相同, 但是底层的原理是相通的. 如果大家有语言的基础, 可以跳过这一部分, 如果完全没有的话, 我也不能保证您看完之后能利马就学会了, 只能说是一个指导作用吧, 详细的话, 官方文档是一个很好的学习工具.
在这里做一个不是特别恰当的比喻, 大家可以把编程语言看做是一辆汽车, 不过这里汽车的作用是在路上行驶, 而编程语言的功能是让计算机为我们服务, 输出我们需要的结果. 作为汽车, 有基本的功能, 左转, 右转, 开门, 关门, 等等, 而对于编程语言, 会有一些基本的结构, 例如, 条件语句, 循环语句, 赋值语句等等. 对于Python来说, 有一个重要的概念叫做包, 可以理解成为是一个工具箱, 这里这里Python的包分为官方包和第三方包, 顾名思义, 官方包就是你安装完成编程语言之后, 就可以直接使用的工具箱, 而第三方包是需要你手动安装的. 大家可以理解成为汽车中的配件, 比如发动机, 方向盘等等, 这些是汽车出厂就带着的, 而比如车载冰箱, 行车记录仪等等, 这些是需要消费者自行购买的. 因此, 如果我们要利用Python做爬虫, 我们需要了解Python中的工具如何使用, 同样, 如果我们想开车上路, 我们肯定要先学习怎样开车. 在这里, 我在这里不打算去介绍Python中各种语法和语句是怎么样的, 如何去使用, 因为这些官方文档讲的比我好, 我在下文用到的时候, 会简单介绍Python中的函(工)数(具)如何使用.
网页
作为爬虫, 我们一般都是利用编程语言(Python)自动获取网页的内容, 在开始爬虫之前, 我们肯定是需要了解网页是如何组成的. 再来一个比喻, 相信很多人都记过手账, 大家可以把网页看成是一个手账本子中的一页.

不过这里给手账本内容的不是我们, 而是浏览器, 浏览器会按照指定的规则, 将预定的元素个放到页面上面, 为了让浏览器理解, 因此我们指定了某些标签, 例如 这里的地址是指的网页的地址, 也就是URL, 这个可以理解为一个路径, 通过这个路径, 我们可以找到网页, 这里可以理解成为一个图书馆图书位置的索引, 我们可以通过这个索引找到我们需要的书籍. 到这里, 基本的基础知识我就简单的介绍完成了, 当然, 这里只是简单的提及了一下, 如果真的像学习的话, 看完上面这些显然是不够的. 光说不练假把戏, 因此, 我们来看一个具体的例子来看一下上文所说的知识. 这里我们用一个非常简单的例子, 我们来爬取某度的首页, 我觉得首页这个logo挺好看的, 想保存下来. 当然, 这个案例太简单了, 我直接右键另存为就好了, 当然如果图片非常多的话, 手动另存为显然就不是一个好的方案了, 相信好多男生学习完爬虫, 想爬的网站之一就是妹纸图了, 这么多图片如果手动存的话, 那就肯定是要靠代码了. 当然这里还是回归本文, 扯得有点远了, 我们来考虑, 我们怎么利用代码来获取某度的logo. 首先, 我们肯定要看这个页面是由什么元素组成的, 也就是我们打开手账本, 我们可以看到各种记录, 我们需要分析我们应该把元素放到哪里. 在浏览器查看元素的话, 可以右键审查代码, 或者按快捷键 我们首先看到的就是这一堆英文符号, 前文说过, 页面显示的元素就是由这些标签组成的, 这些英文就是标签, 我们来看 关于这个库的安装, 大家搜索一下吧, 这个给我朋友留了一个小问题, 估计学过Python的应该都知道, 接下来, 我们来看代码. 这里, 地址就是代码中的 到这里, 这个小栗子就完成了, 虽然不难, 但是这里也包含了爬虫所用的基本的知识, 由于个人水平有限, 文中的栗子和说法不一定都非常的恰当, 也欢迎各位大佬的斧正., 地址
案例

F12. 我们就能看到网页由什么元素组成的了.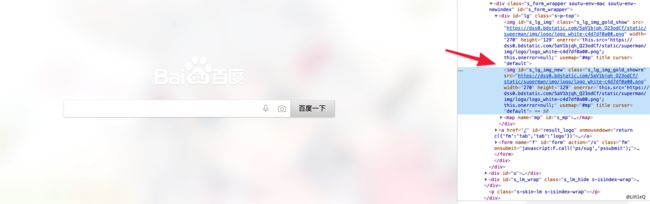
image)的一个缩写吧. 找到这个元素了, 我们就要想办法吧这个元素提取出来, 因此我们可以根据这个定位. 当然, 页面图片可能不止一个, 大家要自己找到需要的元素, 找到切入点, 我们就可以写代码了, 不过在写代码之前, 我们需要介绍一个Python第三方的库(requests_html), 便于我们快速获取到这个元素.def fetch_baidu():
url = 'https://www.baidu.com'
session = HTMLSession()
req = session.get(url)
img = req.html.find('img', first=True)
logo_url = 'https:' + img.attrs['src']
res = session.get(logo_url)
with open('/Users/littleq/Desktop/logo.png', 'wb') as f:
f.write(res.content)
return req
url, 然后这个库怎么使用呢? 我们会发现我们用代码获取页面内容的函数就是req = session.get(url), 大家可以理解成为这个工具就是这样使用的, 就比如, 汽车如果要启动的话就是打火, 这个就是这样设计的, 然后找到img标签的方法就是req.html.find('img', first=True), 这个也很形象, 就是我在返回的页面上找, 找到第一个img. 最后几行就是保存图片到文件了.