3 Openstack-Ussuri-高可用配置(pacemaker&haproxy)部署-centos8
pacemaker:资源管理器(CRM),负责启动与停止服务,位于 HA 集群架构中资源管理、资源代理层
corosync:消息层组件(Messaging Layer),管理成员关系、消息与仲裁,为高可用环境中提供通讯服务,位于高可用集群架构的底层,为各节点(node)之间提供心跳信息;
resource-agents:资源代理,在节点上接收CRM的调度,对某一资源进行管理的工具,管理工具通常为脚本;
pcs:命令行工具集;
fence-agents:fencing 在一个节点不稳定或无答复时将其关闭,使其不会损坏集群的其它资源,其主要作用是消除脑裂
#在全部控制节点安装相关服务,以controller160节点为例;
3.1 配置SSH免密认证
[root@controller160 ~]# ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:WV0VywXmgnocShYxbETsggN5Y75Ls+jMZsvbu6iEvmc root@controller160
The key's randomart image is:
+---[RSA 3072]----+
| . =*. +++|
| o + +o o +. o|
| = o oo + o .o |
| + .o.* . . |
| o .S o |
|. + . |
|.. o + |
|o++Eo |
|.B%o+o |
+----[SHA256]-----+
[root@controller160 ~]# ssh-copy-id root@controller161
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
The authenticity of host 'controller161 (172.16.1.161)' can't be established.
ECDSA key fingerprint is SHA256:7QfTWDISgUB5tbDsuL21tTBgWAfN+9kB2buwObFt32o.
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@controller161's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'root@controller161'"
and check to make sure that only the key(s) you wanted were added.
[root@controller160 ~]# ssh-copy-id root@controller162
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
The authenticity of host 'controller162 (172.16.1.162)' can't be established.
ECDSA key fingerprint is SHA256:7QfTWDISgUB5tbDsuL21tTBgWAfN+9kB2buwObFt32o.
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@controller162's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'root@controller162'"
and check to make sure that only the key(s) you wanted were added.
3.2 启用HighAvailability repo
yum -y install yum-utils
dnf config-manager --set-enabled HighAvailability
dnf config-manager --set-enabled PowerTools
#安装跟启用EPEL repo
rpm -Uvh https://dl.fedoraproject.org/pub/epel/epel-release-latest-8.noarch.rpm
3.3 构建pacemaker集群
yum install -y pacemaker pcs corosync fence-agents resource-agents
#构建集群
#启动pcs服务,在全部控制节点执行,以controller160节点为例
[root@controller160 ~]# systemctl enable pcsd
[root@controller160 ~]# systemctl start pcsd
#修改集群管理员hacluster(默认生成)密码,在全部控制节点执行,以controller160节点为例
[root@controller160 ~]# echo hacluster.123 | passwd --stdin hacluster
Changing password for user hacluster.
passwd: all authentication tokens updated successfully
#认证配置在任意节点操作,以controller160节点为例;
#节点认证,组建集群,需要采用上一步设置的password
[root@controller160 ~]# pcs host auth controller160 controller161 controller162 -u hacluster -p hacluster.123
controller160: Authorized
controller161: Authorized
controller162: Authorized
#创建并命名集群,在任意节点操作,以controller160节点为例;
#生成配置文件:/etc/corosync/corosync.conf
[root@controller160 ~]# pcs cluster setup openstack-u-cluster --start controller160 controller161 controller162
No addresses specified for host 'controller160', using 'controller160'
No addresses specified for host 'controller161', using 'controller161'
No addresses specified for host 'controller162', using 'controller162'
Destroying cluster on hosts: 'controller160', 'controller161', 'controller162'...
controller160: Successfully destroyed cluster
controller162: Successfully destroyed cluster
controller161: Successfully destroyed cluster
Requesting remove 'pcsd settings' from 'controller160', 'controller161', 'controller162'
controller160: successful removal of the file 'pcsd settings'
controller161: successful removal of the file 'pcsd settings'
controller162: successful removal of the file 'pcsd settings'
Sending 'corosync authkey', 'pacemaker authkey' to 'controller160', 'controller161', 'controller162'
controller160: successful distribution of the file 'corosync authkey'
controller160: successful distribution of the file 'pacemaker authkey'
controller161: successful distribution of the file 'corosync authkey'
controller161: successful distribution of the file 'pacemaker authkey'
controller162: successful distribution of the file 'corosync authkey'
controller162: successful distribution of the file 'pacemaker authkey'
Sending 'corosync.conf' to 'controller160', 'controller161', 'controller162'
controller160: successful distribution of the file 'corosync.conf'
controller161: successful distribution of the file 'corosync.conf'
controller162: successful distribution of the file 'corosync.conf'
Cluster has been successfully set up.
Starting cluster on hosts: 'controller160', 'controller161', 'controller162'...
3.4 启动集群
#启动群集服务,开机启动,以controller160节点为例
[root@controller160 ~]# pcs cluster enable --all
controller160: Cluster Enabled
controller161: Cluster Enabled
controller162: Cluster Enabled
[root@controller160 ~]# pcs cluster status
Cluster Status:
Cluster Summary:
* Stack: corosync
* Current DC: controller161 (version 2.0.3-5.el8_2.1-4b1f869f0f) - partition with quorum
* Last updated: Thu Jun 18 01:00:33 2020
* Last change: Thu Jun 18 00:58:20 2020 by hacluster via crmd on controller161
* 3 nodes configured
* 0 resource instances configured
Node List:
* Online: [ controller160 controller161 controller162 ]
PCSD Status:
controller160: Online
controller161: Online
controller162: Online
#查看corosync状态;
#“corosync”表示一种底层状态等信息的同步方式
[root@controller160 ~]# pcs status corosync
Membership information
----------------------
Nodeid Votes Name
1 1 controller160 (local)
2 1 controller161
3 1 controller162
#查看节点
[root@controller160 ~]# corosync-cmapctl | grep members
runtime.members.1.config_version (u64) = 0
runtime.members.1.ip (str) = r(0) ip(172.16.1.160)
runtime.members.1.join_count (u32) = 1
runtime.members.1.status (str) = joined
runtime.members.2.config_version (u64) = 0
runtime.members.2.ip (str) = r(0) ip(172.16.1.161)
runtime.members.2.join_count (u32) = 1
runtime.members.2.status (str) = joined
runtime.members.3.config_version (u64) = 0
runtime.members.3.ip (str) = r(0) ip(172.16.1.162)
runtime.members.3.join_count (u32) = 1
runtime.members.3.status (str) = joined
#查看集群资源
[root@controller160 ~]# pcs resource
NO resources configured
#或通过web访问任意控制节点:https://172.16.1.160:2224
#账号/密码(即构建集群时生成的密码):hacluster/hacluster.123
3.5 高可用配置
#在任意控制节点设置属性即可,以controller160节点为例;
#设置合适的输入处理历史记录及策略引擎生成的错误与警告,在troulbshoot时有用
[root@controller160 ~]# pcs property set pe-warn-series-max=1000 \
> pe-input-series-max=1000 \
> pe-error-series-max=1000
#pacemaker基于时间驱动的方式进行状态处理,” cluster-recheck-interval”默认定义某些pacemaker操作发生的事件间隔为15min,建议设置为5min或3min
[root@controller160 ~]# pcs property set cluster-recheck-interval=5
#corosync默认启用stonith,但stonith机制(通过ipmi或ssh关闭节点)并没有配置相应的stonith设备(通过“crm_verify -L -V”验证配置是否正确,没有输出即正确),此时pacemaker将拒绝启动任何资源;
#在生产环境可根据情况灵活调整,验证环境下可关闭
[root@controller160 ~]# pcs property set stonith-enabled=false
#默认当有半数以上节点在线时,集群认为自己拥有法定人数,是“合法”的,满足公式:total_nodes < 2 * active_nodes;
#以3个节点的集群计算,当故障2个节点时,集群状态不满足上述公式,此时集群即非法;当集群只有2个节点时,故障1个节点集群即非法,所谓的”双节点集群”就没有意义;
#在实际生产环境中,做2节点集群,无法仲裁时,可选择忽略;做3节点集群,可根据对集群节点的高可用阀值灵活设置
[root@controller160 ~]# pcs property set no-quorum-policy=ignore
#v2的heartbeat为了支持多节点集群,提供了一种积分策略来控制各个资源在集群中各节点之间的切换策略;通过计算出各节点的的总分数,得分最高者将成为active状态来管理某个(或某组)资源;
#默认每一个资源的初始分数(取全局参数default-resource-stickiness,通过"pcs property list --all"查看)是0,同时每一个资源在每次失败之后减掉的分数(取全局参数default-resource-failure-stickiness)也是0,此时一个资源不论失败多少次,heartbeat都只是执行restart操作,不会进行节点切换;
#如果针对某一个资源设置初始分数”resource-stickiness“或"resource-failure-stickiness",则取单独设置的资源分数;
#一般来说,resource-stickiness的值都是正数,resource-failure-stickiness的值都是负数;有一个特殊值是正无穷大(INFINITY)和负无穷大(-INFINITY),即"永远不切换"与"只要失败必须切换",是用来满足极端规则的简单配置项;
#如果节点的分数为负,该节点在任何情况下都不会接管资源(冷备节点);如果某节点的分数大于当前运行该资源的节点的分数,heartbeat会做出切换动作,现在运行该资源的节点将释 放资源,分数高出的节点将接管该资源
#pcs property list 只可查看修改后的属性值,参数”–all”可查看含默认值的全部属性值;
[root@controller160 ~]# pcs property list
Cluster Properties:
cluster-infrastructure: corosync
cluster-name: openstack-u-cluster
cluster-recheck-interval: 5
dc-version: 2.0.3-5.el8_2.1-4b1f869f0f
have-watchdog: false
no-quorum-policy: ignore
pe-error-series-max: 1000
pe-input-series-max: 1000
pe-warn-series-max: 1000
stonith-enabled: false
#也可查看/var/lib/pacemaker/cib/cib.xml文件,或”pcs cluster cib”,或“cibadmin --query --scope crm_config”查看属性设置,” cibadmin --query --scope resources”查看资源配置
3.6 配置VIP
#在任意控制节点设置vip(resource_id属性)即可,命名即为“vip”;
#ocf(standard属性):资源代理(resource agent)的一种,另有systemd,lsb,service等;
#heartbeat:资源脚本的提供者(provider属性),ocf规范允许多个供应商提供同一资源代理,大多数ocf规范提供的资源代理都使用heartbeat作为provider;
#IPaddr2:资源代理的名称(type属性),IPaddr2便是资源的type;
#通过定义资源属性(standard:provider:type),定位”vip”资源对应的ra脚本位置;
#centos系统中,符合ocf规范的ra脚本位于/usr/lib/ocf/resource.d/目录,目录下存放了全部的provider,每个provider目录下有多个type;
#op:表示Operations
[root@controller160 ~]# pcs resource create vip ocf:heartbeat:IPaddr2 ip=172.16.1.168 cidr_netmask=24 op monitor interval=30s
[root@controller160 ~]# ip a show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether fa:f2:63:23:7a:e5 brd ff:ff:ff:ff:ff:ff
inet 172.16.1.160/24 brd 172.16.1.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet 172.16.1.168/24 brd 172.16.1.255 scope global secondary eth0
valid_lft forever preferred_lft forever
inet6 fe80::f8f2:63ff:fe23:7ae5/64 scope link
valid_lft forever preferred_lft forever
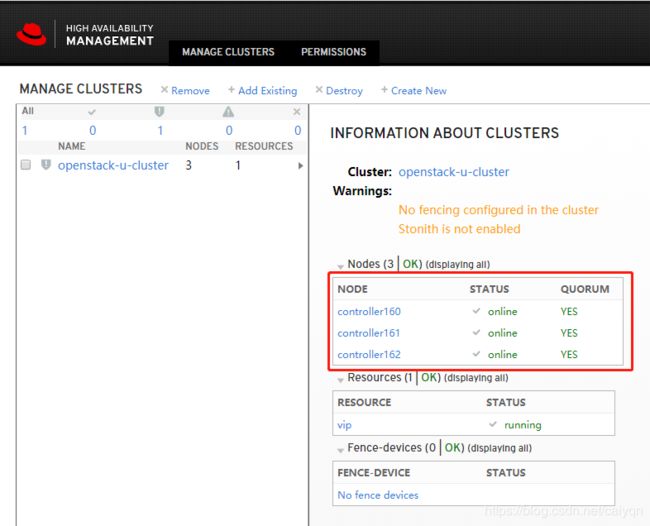
#查看集群资源,过”pcs resouce”查询,vip资源在controller160节点;
[root@controller160 ~]# pcs resource
* vip (ocf::heartbeat:IPaddr2): Started controller160
#如果api区分admin/internal/public接口,对客户端只开放public接口,通常设置两个vip,如命名为:vip_management与vip_public;
#建议是将vip_management与vip_public约束在1个节点
[root@controller160 ~]# pcs constraint colocation add vip_management with vip_public
3.7 高可用管理
#手动添加集群,实际操作只需要添加已组建集群的任意节点即可,如下

3.8 部署Haproxy
#在全部控制节点安装haproxy,以controller160节点为例;
yum install haproxy -y
#配置haproxy.cfg
#建议开启haproxy的日志功能,便于后续的问题排查!
#创建HAProxy记录日志文件并授权
mkdir /var/log/haproxy && chmod a+w /var/log/haproxy
#在rsyslog文件下修改以下字段
#vim /etc/rsyslog.conf
#启用tcp/udp模块
module(load="imudp") # needs to be done just once
input(type="imudp" port="514")
module(load="imtcp") # needs to be done just once
input(type="imtcp" port="514")
#添加haproxy配置
local0.=info -/var/log/haproxy/haproxy-info.log
local0.=err -/var/log/haproxy/haproxy-err.log
local0.notice;local0.!=err -/var/log/haproxy/haproxy-notice.log
#重启rsyslog
systemctl restart rsyslog
#在全部控制节点配置haproxy.cfg,以controller160节点为例;
#haproxy依靠rsyslog输出日志,是否输出日志根据实际情况设定;
#备份原haproxy.cfg文件
cp /etc/haproxy/haproxy.cfg /etc/haproxy/haproxy.cfg.bak
#==集群的haproxy配置,涉及服务较多,可根据后面实际部署内容进行更改,==这里针对涉及到的openstack服务,一次性设置完成,如下:
[root@controller160 ~]# grep -v ^# /etc/haproxy/haproxy.cfg
global
chroot /var/lib/haproxy
daemon
group haproxy
user haproxy
maxconn 4000
pidfile /var/run/haproxy.pid
log 127.0.0.1 local0 info
defaults
log global
maxconn 4000
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout check 10s
# haproxy监控页
listen stats
bind 0.0.0.0:1080
mode http
stats enable
stats uri /
stats realm OpenStack\ Haproxy
stats auth admin:admin
stats refresh 30s
stats show-node
stats show-legends
stats hide-version
# horizon服务
listen dashboard_cluster
bind 172.16.1.168:80
balance source
option tcpka
option httpchk
option tcplog
server controller160 172.16.1.160:80 check inter 2000 rise 2 fall 5
server controller161 172.16.1.161:80 check inter 2000 rise 2 fall 5
server controller162 172.16.1.162:80 check inter 2000 rise 2 fall 5
# mariadb服务;
# 设置controller160节点为master,controller161/162节点为backup,一主多备的架构可规避数据不一致性;
# 另外官方示例为检测9200(心跳)端口,测试在mariadb服务宕机的情况下,虽然”/usr/bin/clustercheck”脚本已探测不到服务,但受xinetd控制的9200端口依然正常,导致haproxy始终将请求转发到mariadb服务宕机的节点,暂时修改为监听3306端口
listen galera_cluster
bind 172.16.1.168:3306
balance source
mode tcp
server controller160 172.16.1.160:3306 check inter 2000 rise 2 fall 5
server controller161 172.16.1.161:3306 backup check inter 2000 rise 2 fall 5
server controller162 172.16.1.162:3306 backup check inter 2000 rise 2 fall 5
# 为rabbirmq提供ha集群访问端口,供openstack各服务访问;
# 如果openstack各服务直接连接rabbitmq集群,这里可不设置rabbitmq的负载均衡
listen rabbitmq_cluster
bind 172.16.1.168:5673
mode tcp
option tcpka
balance roundrobin
timeout client 3h
timeout server 3h
option clitcpka
server controller160 172.16.1.160:5672 check inter 10s rise 2 fall 5
server controller161 172.16.1.161:5672 check inter 10s rise 2 fall 5
server controller162 172.16.1.162:5672 check inter 10s rise 2 fall 5
# glance_api服务
listen glance_api_cluster
bind 172.16.1.168:9292
balance source
option tcpka
option httpchk
option tcplog
server controller160 172.16.1.160:9292 check inter 2000 rise 2 fall 5
server controller161 172.16.1.161:9292 check inter 2000 rise 2 fall 5
server controller162 172.16.1.162:9292 check inter 2000 rise 2 fall 5
# keystone_public _api服务
listen keystone_public_cluster
bind 172.16.1.168:5000
balance source
option tcpka
option httpchk
option tcplog
server controller160 172.16.1.160:5000 check inter 2000 rise 2 fall 5
server controller161 172.16.1.161:5000 check inter 2000 rise 2 fall 5
server controller162 172.16.1.162:5000 check inter 2000 rise 2 fall 5
listen nova_compute_api_cluster
bind 172.16.1.168:8774
balance source
option tcpka
option httpchk
option tcplog
server controller160 172.16.1.160:8774 check inter 2000 rise 2 fall 5
server controller161 172.16.1.161:8774 check inter 2000 rise 2 fall 5
server controller162 172.16.1.162:8774 check inter 2000 rise 2 fall 5
listen nova_placement_cluster
bind 172.16.1.168:8778
balance source
option tcpka
option tcplog
server controller160 172.16.1.160:8778 check inter 2000 rise 2 fall 5
server controller161 172.16.1.161:8778 check inter 2000 rise 2 fall 5
server controller162 172.16.1.162:8778 check inter 2000 rise 2 fall 5
listen nova_metadata_api_cluster
bind 172.16.1.168:8775
balance source
option tcpka
option tcplog
server controller160 172.16.1.160:8775 check inter 2000 rise 2 fall 5
server controller161 172.16.1.161:8775 check inter 2000 rise 2 fall 5
server controller162 172.16.1.162:8775 check inter 2000 rise 2 fall 5
listen nova_vncproxy_cluster
bind 172.16.1.168:6080
balance source
option tcpka
option tcplog
server controller160 172.16.1.160:6080 check inter 2000 rise 2 fall 5
server controller161 172.16.1.161:6080 check inter 2000 rise 2 fall 5
server controller162 172.16.1.162:6080 check inter 2000 rise 2 fall 5
listen neutron_api_cluster
bind 172.16.1.168:9696
balance source
option tcpka
option httpchk
option tcplog
server controller160 172.16.1.160:9696 check inter 2000 rise 2 fall 5
server controller161 172.16.1.161:9696 check inter 2000 rise 2 fall 5
server controller162 172.16.1.162:9696 check inter 2000 rise 2 fall 5
listen cinder_api_cluster
bind 172.16.1.168:8776
balance source
option tcpka
option httpchk
option tcplog
server controller160 172.16.1.160:8776 check inter 2000 rise 2 fall 5
server controller161 172.16.1.161:8776 check inter 2000 rise 2 fall 5
server controller162 172.16.1.162:8776 check inter 2000 rise 2 fall 5
3.9 各节点配置内核参数
#全部控制节点修改内核参数,以controller160节点为例;
#net.ipv4.ip_nonlocal_bind:是否允许no-local ip绑定,关系到haproxy实例与vip能否绑定并切换;
#net.ipv4.ip_forward:是否允许转发
[root@controller160 ~]# echo "net.ipv4.ip_nonlocal_bind = 1" >>/etc/sysctl.conf
[root@controller160 ~]# echo "net.ipv4.ip_forward = 1" >>/etc/sysctl.conf
[root@controller160 ~]# sysctl -p
net.ipv4.ip_nonlocal_bind = 1
net.ipv4.ip_forward = 1
#开机启动是否设置可自行选择,利用pacemaker设置haproxy相关资源后,pacemaker可控制各节点haproxy服务是否启动
[root@controller160 ~]# systemctl restart haproxy
[root@controller160 ~]# systemctl status haproxy
● haproxy.service - HAProxy Load Balancer
Loaded: loaded (/usr/lib/systemd/system/haproxy.service; disabled; vendor preset: disabled)
Active: active (running) since Thu 2020-06-18 01:29:43 CST; 4s ago
Process: 19581 ExecStartPre=/usr/sbin/haproxy -f $CONFIG -c -q (code=exited, status=0/SUCCESS)
Main PID: 19582 (haproxy)
Tasks: 2 (limit: 11490)
Memory: 4.4M
CGroup: /system.slice/haproxy.service
├─19582 /usr/sbin/haproxy -Ws -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid
└─19584 /usr/sbin/haproxy -Ws -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid
Jun 18 01:29:43 controller160 haproxy[19582]: [WARNING] 169/012943 (19582) : config : log format ignored for proxy 'glance_api_cluster' since it has no log address.
Jun 18 01:29:43 controller160 haproxy[19582]: [WARNING] 169/012943 (19582) : config : log format ignored for proxy 'keystone_public_cluster' since it has no log address.
Jun 18 01:29:43 controller160 haproxy[19582]: [WARNING] 169/012943 (19582) : config : log format ignored for proxy 'nova_ec2_api_cluster' since it has no log address.
Jun 18 01:29:43 controller160 haproxy[19582]: [WARNING] 169/012943 (19582) : config : log format ignored for proxy 'nova_compute_api_cluster' since it has no log address.
Jun 18 01:29:43 controller160 haproxy[19582]: [WARNING] 169/012943 (19582) : config : log format ignored for proxy 'nova_placement_cluster' since it has no log address.
Jun 18 01:29:43 controller160 haproxy[19582]: [WARNING] 169/012943 (19582) : config : log format ignored for proxy 'nova_metadata_api_cluster' since it has no log address.
Jun 18 01:29:43 controller160 haproxy[19582]: [WARNING] 169/012943 (19582) : config : log format ignored for proxy 'nova_vncproxy_cluster' since it has no log address.
Jun 18 01:29:43 controller160 haproxy[19582]: [WARNING] 169/012943 (19582) : config : log format ignored for proxy 'neutron_api_cluster' since it has no log address.
Jun 18 01:29:43 controller160 haproxy[19582]: [WARNING] 169/012943 (19582) : config : log format ignored for proxy 'cinder_api_cluster' since it has no log address.
Jun 18 01:29:43 controller160 systemd[1]: Started HAProxy Load Balancer.
#访问:http://172.16.1.168:1080 用户名/密码:admin/admin
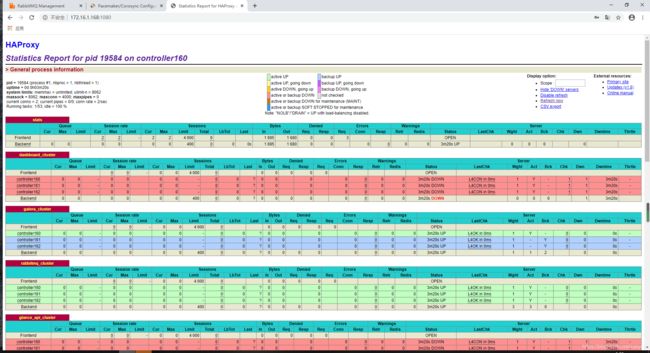
3.10 设置pcs,haproxy资源跟随vip
#任意控制节点操作即可,以controller160节点为例;
#添加资源lb-haproxy-clone
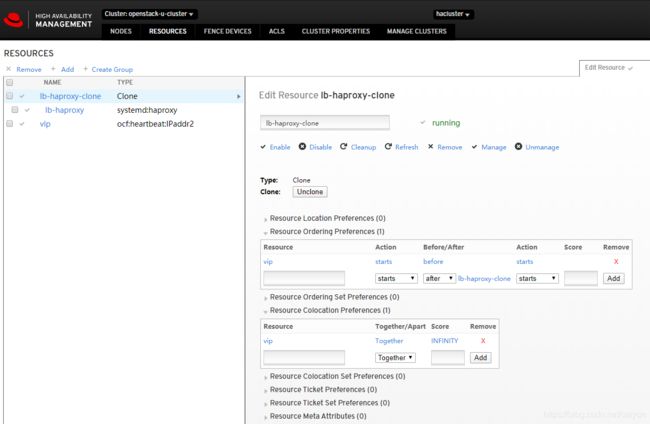
[root@controller160 ~]# pcs resource create lb-haproxy systemd:haproxy clone
[root@controller160 ~]# pcs resource
* vip (ocf::heartbeat:IPaddr2): Started controller160
* Clone Set: lb-haproxy-clone [lb-haproxy]:
* Started: [ controller160 controller161 controller162 ]
#设置资源启动顺序,先vip再lb-haproxy-clone;
#通过“cibadmin --query --scope constraints”可查看资源约束配置
[root@controller160 ~]# pcs constraint order start vip then lb-haproxy-clone kind=Optional
Adding vip lb-haproxy-clone (kind: Optional) (Options: first-action=start then-action=start)
#官方建议设置vip运行在haproxy active的节点,通过绑定lb-haproxy-clone与vip服务,将两种资源约束在1个节点;
#约束后,从资源角度看,其余暂时没有获得vip的节点的haproxy会被pcs关闭
[root@controller160 ~]# pcs constraint colocation add lb-haproxy-clone with vip
[root@controller160 ~]# pcs resource
* vip (ocf::heartbeat:IPaddr2): Started controller160
* Clone Set: lb-haproxy-clone [lb-haproxy]:
* Started: [ controller160 ]
* Stopped: [ controller161 controller162 ]
#通过high availability management查看资源相关的设置
至此,高可用配置(pacemaker&haproxy)已部署完毕,如有问题请联系我改正,感激不尽!
3.x 部署过程遇到的问题汇总
eg1.Error:
Problem: package fence-agents-all-4.2.1-41.el8.x86_64 requires fence-agents-apc-snmp >= 4.2.1-41.el8, but none of the providers can be installed
- package fence-agents-apc-snmp-4.2.1-41.el8.noarch requires net-snmp-utils, but none of the providers can be installed
- conflicting requests
- nothing provides net-snmp-libs(x86-64) = 1:5.8-14.el8 needed by net-snmp-utils-1:5.8-14.el8.x86_64
解决方案 :单独下载net-snmp-libs-5.8-14.el8.x86_64.rpm安装即可解决
rpm -ivh net-snmp-libs-5.8-14.el8.x86_64.rpm
eg2.[root@controller160 ~]# dnf config-manager --set-enabled HighAvailability
Repository AppStream is listed more than once in the configuration
Repository extras is listed more than once in the configuration
Repository PowerTools is listed more than once in the configuration
Repository centosplus is listed more than once in the configuration
解决方案:恢复centos8自带的Base源,可解决大部分的依赖问题
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.aliyun
cp /etc/yum.repos.d/CentOS-Base.repo.bak /etc/yum.repos.d/CentOS-Base.repo
yum makecache