java集合-Map接口
文章目录
- 1. Map接口
- 泛型
Collection接口
Map接口
1. Map接口
Java官方文档对Map的解释
An object that maps keys to values. A map cannot contain duplicate keys; each key can map to at most one value.
This interface takes the place of the Dictionary class, which was a totally abstract class rather than an interface.
The Map interface provides three collection views, which allow a map’s contents to be viewed as a set of keys, collection of values, or set of key-value mappings. The order of a map is defined as the order in which the iterators on the map’s collection views return their elements. Some map implementations, like the TreeMap class, make specific guarantees as to their order; others, like the HashMap class, do not.
大概意思就是
一个保存键值映射的对象。 映射Map中不能包含重复的key,每一个key最多对应一个value。
这个接口替代了原来的一个抽象类Dictionary。
Map集合提供3种遍历访问方法,
- 获得所有key的集合然后通过key访问value。
- 获得value的集合。
- 获得key-value键值对的集合(key-value键值对其实是一个对象,里面分别有key和value)。
Map的访问顺序取决于Map的遍历访问方法的遍历顺序。
有的Map,比如TreeMap可以保证访问顺序,但是有的比如HashMap,无法保证访问顺序。
接口定义如下:
public interface Map<K,V> {
...
interface Entry<K,V> {
K getKey();
V getValue();
...
}
}
泛型分别代表key和value的类型。
这时候注意到还定义了一个内部接口Entry,其实每一个键值对都是一个Entry的实例关系对象,所以Map实际其实就是Entry的一个Collection,然后Entry里面包含key,value。
再设定key不重复的规则,自然就演化成了Map。(个人理解)
Map接口并不是Collection接口的子接口,但是它仍然被看作是Collection框架的一部分。
Map是一种把键对象和值对象进行关联的容器,而一个值对象又可以是一个Map,依次类推,这样就可形成一个多级映射。
1.1 类图:
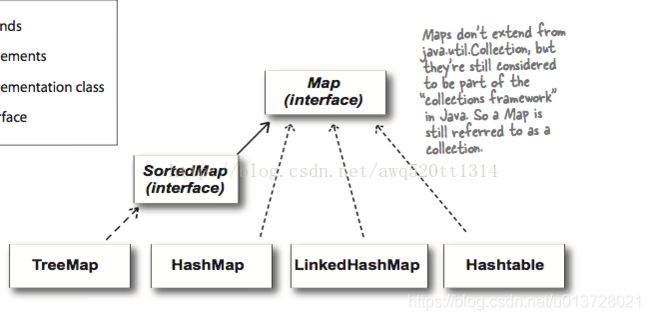
Map
├Hashtable
├HashMap
└WeakHashMap
对于键对象 来说,像Set一样,一个Map容器中的键对象不允许重复,这是为了保持查找结果的一致性;如果有两个键对象一样,那你想得到那个键对象所对应的值对象时就有问题了,可能你得到的并不是你想的那个值对象,结果会造成混乱,所以键的唯一性很重要,也是符合集合的性质的。
当然在使用过程中,某个键所对应的值对象可能会发生变化,这时会按照最后一次修改的值对象与键对应。对于值对象则没有唯一性的要求。
你可以将任意多个键都映射到一个值对象上,这不会发生任何问题(不过对你的使用却可能会造成不便,你不知道你得到的到底是那一个键所对应的值对象)。
1.2 下面介绍下定义的3个遍历Map的方法。
Set keySet()
会返回所有key的Set集合,因为key不可以重复,所以返回的是Set格式,而不是List格式。
之后会说明Set,List区别。这里先告诉一点Set集合内元素是不可以重复的,而List内是可以重复的。
获取到所有key的Set集合后,由于Set是Collection类型的,所以可以通过Iterator去遍历所有的key,然后再通过get方法获取value。
如下:
Map<String,String> map = new HashMap<String,String>();
map.put("01", "zhangsan");
map.put("02", "lisi");
map.put("03", "wangwu");
Set<String> keySet = map.keySet();//先获取map集合的所有键的Set集合
Iterator<String> it = keySet.iterator();//有了Set集合,就可以获取其迭代器。
while(it.hasNext()) {
String key = it.next();
String value = map.get(key);//有了键可以通过map集合的get方法获取其对应的值。
System.out.println("key: "+key+"-->value: "+value);//获得key和value值
}
Collection values()
直接获取values的集合,无法再获取到key。
所以如果只需要value的场景可以用这个方法。获取到后使用Iterator去遍历所有的value。
如下:
Map<String,String> map = new HashMap<String,String>();
map.put("01", "zhangsan");
map.put("02", "lisi");
map.put("03", "wangwu");
Collection<String> collection = map.values();//返回值是个值的Collection集合
System.out.println(collection);
Set< Map.Entry< K, V>> entrySet()
是将整个Entry对象作为元素返回所有的数据。
然后遍历Entry,分别再通过getKey和getValue获取key和value。
如下:
Map<String,String> map = new HashMap<String,String>();
map.put("01", "zhangsan");
map.put("02", "lisi");
map.put("03", "wangwu");
//通过entrySet()方法将map集合中的映射关系取出(这个关系就是Map.Entry类型)
Set<Map.Entry<String, String>> entrySet = map.entrySet();
//将关系集合entrySet进行迭代,存放到迭代器中
Iterator<Map.Entry<String, String>> it = entrySet.iterator();
while(it.hasNext()) {
Map.Entry<String, String> me = it.next();//获取Map.Entry关系对象me
String key = me.getKey();//通过关系对象获取key
String value = me.getValue();//通过关系对象获取value
}
通过以上3种遍历方式我们可以知道,如果你只想获取key,建议使用keySet。
如果只想获取value,建议使用values。
如果key value希望遍历,建议使用entrySet。
(虽然通过keySet可以获得key再间接获得value,但是效率没entrySet高,不建议使用这种方法)
2. HashMap类
HashMap就是最基础最常用的一种Map,它无序,以散列表的方式进行存储。
根据键的Hash值计算存储位置,存储键值对,可以根据键获取对应值。
具有很快的访问速度,但是是无序的、线程不安全的。
且HashMap不同步,如果需要线程同步,则需要使用ConcurrentHashMap,也可以使用Collections.synchronizedMap(HashMap map)方法让HashMap具有同步的能力。
其实是否同步,就看有没有synchronized关键字。
HashMap的key有且只能允许一个null。
之前提到过,HashSet就是基于HashMap,只使用了HashMap的key作为单个元素存储。
注:线程不安全(多个线程访问同一个对象或实现进行更新操作时,造成数据混乱)
HashMap的访问方式就是继承于Map的最基础的3种方式,详细见上。在这里我具体分析一下HashMap的底层数据结构的实现。
2.1 哈希表
在看HashMap源码前,先理解一下他的存储方式-散列表(哈希表)。
像之前提到过的用数组存储,用链表存储。哈希表是使用数组和链表的组合的方式进行存储。
(具体哈希表的概念自行搜索)如下图就是HashMap采用的存储方法。

hash得到数值,放到数组中,如果遇到冲突则以链表方式挂在下方。
2.2 HashMap的源码
HashMap的存储定义是
transient Node<K,V>[] table;
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
}
数组table存放元素,如果遇到冲突下挂到冲突元素的next链表上。
在这我们可以看下get核心方法和put核心方法的源码
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab;
Node<K,V> first, e;
int n;
K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
上面代码中看出先根据hash值和数组长度作且运算得出下标索引。
如果存在判断hash值是否完全一致,如果不完全一致则next链表向下找一致的hash值。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab;
Node<K,V> p;
int n, i;
//如果table为空或者table.length==0
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e;
K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
上面是put的核心源码,即查找hash值所在索引是否有元素,没有的话new一个Node直接放在table中。
如果已经有Node了,就遍历该Node的next,将新元素放到最后。
HashMap的遍历,是从数组遍历第一个非空的元素,然后再根据这个元素访问其next下的所有Node。因为第一个元素不是一定从数组的0开始,所以HashMap是无序遍历。
3. Hashtable类
Hashtable继承自Dictionary类 ,它也是无序的,但是Hashtable是线程安全的,同步的,即任一时刻只有一个线程能写Hashtable
由此我们比较一下HashMap和Hashtable的运行效率
测试插入效率如下:
long runCount=1000000;
Map<Integer,Integer> hashMap = new HashMap<Integer, Integer>();
Date dateBegin = new Date();
for (int i = 0; i < runCount; i++) {
hashMap.put(i, i);
}
Date dateEnd = new Date();
System.out.println("HashMap插入用时为:" + (dateEnd.getTime() - dateBegin.getTime()));
Map<Integer,Integer> hashtable = new Hashtable<Integer, Integer>();
Date dateBegin1 = new Date();
for (int i = 0; i < runCount; i++) {
hashtable.put(i, i);
}
Date dateEnd1 = new Date();
System.out.println("Hashtable插入用时为:" + (dateEnd1.getTime() - dateBegin1.getTime()));
运行结果为:
HashMap插入用时为:223
Hashtable插入用时为:674
如果我们将运行次数提高到20000000次,则运行时间分别为:
HashMap插入用时为:36779
Hashtable插入用时为:22632
由此可见,在数据量较小时,HashMap效率较高,但是当数据量增大,HashMap需要进行更多次的resize,这个操作会极大的降低HashMap的运行效率,因此在数据量大之后,Hashtable的运行效率更高。
而反过来重新测试读取效率,代码如下:
long runCount=1000000;
Map<Integer,Integer> hashMap = new HashMap<Integer, Integer>();
for (int i = 0; i < runCount; i++) {
hashMap.put(i, i);
}
Date dateBegin = new Date();
for (Integer key : hashMap.keySet()) {
hashMap.get(key);
}
Date dateEnd = new Date();
System.out.println("HashMap读取用时为:" + (dateEnd.getTime() - dateBegin.getTime()));
Map<Integer,Integer> hashtable = new Hashtable<Integer, Integer>();
for (int i = 0; i < runCount; i++) {
hashtable.put(i, i);
}
Date dateBegin1 = new Date();
for (Integer key : hashtable.keySet()) {
hashtable.get(key);
}
Date dateEnd1 = new Date();
System.out.println("Hashtable读取用时为:" + (dateEnd1.getTime() - dateBegin1.getTime()));
运行结果为:
HashMap读取用时为:54
Hashtable读取用时为:65
如果将数量增加到20000000,则运行结果为:
HashMap读取用时为:336
Hashtable读取用时为:526
由此可见,HashMap的读取效率更高。
4. LinkedHashMap
LinkedHashMap是Map中常用的有序的两种实现之一, 它保存了记录的插入顺序,先进先出。
对于LinkedHashMap而言,它继承与HashMap,底层使用哈希表与双向链表来保存所有元素。
其基本操作与父类HashMap相似,它通过重写父类相关的方法,来实现自己的链接列表特性。
LinkedHashMap采用的hash算法和HashMap相同,但是它重新定义了数组中保存的元素Entry,该Entry除了保存当前对象的引用外,还保存了其上一个元素before和下一个元素after的引用,从而在哈希表的基础上又构成了双向链接列表,效果图如下:
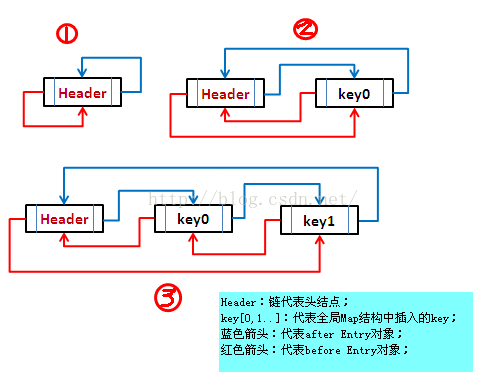
示例代码如下:
Map<Integer,Integer> linkedHashMap = new LinkedHashMap<Integer, Integer>();
linkedHashMap.put(1, 2);
linkedHashMap.put(3, 4);
linkedHashMap.put(5, 6);
linkedHashMap.put(7, 8);
linkedHashMap.put(9, 0);
System.out.println("linkedHashMap的值为:" + linkedHashMap);
输出结果为:
linkedHashMap的值为:{1=2, 3=4, 5=6, 7=8, 9=0}
注:LinkedHashMap在遍历的时候会比HashMap慢,不过有种情况例外,当HashMap容量很大,实际数据较少时,遍历起来可能会 比LinkedHashMap慢,因为LinkedHashMap的遍历速度只和实际数据有关,和容量无关,而HashMap的遍历速度和他的容量有关
5. TreeMap
TreeMap实现SortMap接口,能够把它保存的记录根据键排序,默认是按键值的升序排序,也可以指定排序的比较器,当用Iterator 遍历TreeMap时,得到的记录是排过序的。
TreeMap的排序原理是:红黑树算法的实现 。
它的主要实现是Comparator架构,通过比较的方式,进行一个排序,以下是TreeMap的源码,
比较的源码为:
/**
* Compares two keys using the correct comparison method for this TreeMap.
*/
@SuppressWarnings("unchecked")
final int compare(Object k1, Object k2) {
return comparator==null ? ((Comparable<? super K>)k1).compareTo((K)k2)
: comparator.compare((K)k1, (K)k2);
}
我们也可以自定义Comparator, 对TreeMap数据的排序规则进行修改,这点是LinkedHashMap不能实现的
具体代码如下:
Map<String,Integer> treeMap = new TreeMap<String, Integer>();
treeMap.put("aa", 888);
treeMap.put("ee", 55);
treeMap.put("dd", 777);
treeMap.put("cc", 88);
treeMap.put("bb", 999);
System.out.println("使用默认排序规则,生成的结果为:" + treeMap);
Map<String, Integer> treeMap2 = new TreeMap<String, Integer>(new Comparator<String>() {
public int compare(String o1, String o2) {
return o2.compareTo(o1);
}
});
treeMap2.put("aa", 888);
treeMap2.put("ee", 55);
treeMap2.put("dd", 777);
treeMap2.put("cc", 88);
treeMap2.put("bb", 999);
System.out.println("使用自定义排序规则,生成的结果为:" + treeMap2);
执行结果为:
使用默认排序规则,生成的结果为:{aa=888, bb=999, cc=88, dd=777, ee=55}
使用自定义排序规则,生成的结果为:{ee=55, dd=777, cc=88, bb=999, aa=888}
这边可以查看一下compareTo()的方法源码,内容为:
public int compareTo(String anotherString) {
//先得到比较值的字符串长度
int len1 = value.length;
int len2 = anotherString.value.length;
//得到最小长度
int lim = Math.min(len1, len2);
char v1[] = value;
char v2[] = anotherString.value;
int k = 0;
//逐个比较字符串中字符大小
while (k < lim) {
char c1 = v1[k];
char c2 = v2[k];
if (c1 != c2) {
return c1 - c2;
}
k++;
}
//如果在两个字符串的最小长度内,字符均相同,则比较长度
return len1 - len2;
}
由此可见,当key值中存储了Integer类型的数字时,将默认无法根据数字大小来进行排序,处理方式如下:
Map<String,Integer> treeMap = new TreeMap<String, Integer>();
treeMap.put("1", 888);
treeMap.put("9", 55);
treeMap.put("31", 777);
treeMap.put("239", 88);
treeMap.put("177", 999);
System.out.println("使用默认排序规则,生成的结果为:" + treeMap);
Map<String, Integer> treeMap2 = new TreeMap<String, Integer>(new Comparator<String>() {
public int compare(String o1, String o2) {
//修改比较规则,按照数字大小升序排列
return Integer.parseInt(o1) - Integer.parseInt(o2);
}
});
treeMap2.put("1", 888);
treeMap2.put("9", 55);
treeMap2.put("31", 777);
treeMap2.put("239", 88);
treeMap2.put("177", 999);
System.out.println("使用自定义排序规则,生成的结果为:" + treeMap2);
执行结果为:
使用默认排序规则,生成的结果为:{1=888, 177=999, 239=88, 31=777, 9=55}
使用自定义排序规则,生成的结果为:{1=888, 9=55, 31=777, 177=999, 239=88}
6. 总结
Map中,HashMap具有超高的访问速度,如果我们只是在Map 中插入、删除和定位元素,而无关线程安全或者同步问题,HashMap 是最好的选择。如果考虑线程安全或者写入速度的话,可以使用HashTable。如果想要按照存入数据先入先出的进行读取。 那么使用LinkedHashMap。如果需要让Map按照key进行升序或者降序排序,那就用TreeMap
7. 补充
WeakHashMap类
WeakHashMap是一种改进的HashMap,它对key实行“弱引用”,如果一个key不再被外部所引用,那么该key可以被GC回收。
Hashtable类和HashMap类的区别
Hashtable和HashMap类有三个重要的不同之处。
-
Hashtable是基于陈旧的Dictionary类的,HashMap是Java 1.2引进的Map接口的一个实现。
-
Hashtable的方法是同步的,而HashMap的方法不是。这就意味着,虽然你可以不用采取任何特殊的行为就可以在一个多线程的应用程序中用一个Hashtable,但你必须同样地为一个HashMap提供外同步。一个方便的方法就是利用Collections类的静态的synchronizedMap()方法,它创建一个线程安全的Map对象,并把它作为一个封装的对象来返回。这个对象的方法可以让你同步访问潜在的HashMap。这么做的结果就是当你不需要同步时,你不能切断Hashtable中的同步(比如在一个单线程的应用程序中),而且同步增加了很多处理费用。
-
只有HashMap可以让你将空值作为一个表的条目的key或value。HashMap中只有一条记录可以是一个空的key,但任意数量的条目可以是空的value。这就是说,如果在表中没有发现搜索键,或者如果发现了搜索键,但它是一个空的值,那么get()将返回null。如果有必要,用containKey()方法来区别这两种情况。