Python高级特性与网络爬虫(五):Scrapy框架简介
Scrapy框架简介
scrapy是一个基于Twisted的异步处理框架,是一个纯Python实现的爬虫框架,其架构清晰,模块之间的耦合程度低,可扩展性很强,我们可以通过定制开发几个模块就可以实现一个功能强大的爬虫。一个Scrapy框架如下图所示主要由以下几个部分组成:

- Engine:引擎,处理整个系统的数据流处理、触发事务,是整个框架的核心
- Item:项目,它定义了爬取结果的数据结构,爬取的数据会被赋值成该Item对象
- Scheduler:调度器,接收引擎发过来的请求并将其加入到队列中,在引擎再次请求时将请求提供给引擎
- Downloader:下载器,下载网页内容,并将网页内容返回给爬虫(Spiders)
- Spiders:爬虫,定义了爬取的逻辑和网页的解析规则,负责解析响应并生成提取结果和新的请求
- Item Pipeline:项目管道,负责处理由Spiders从网页中抽取的项目,主要任务为清洗、验证和存储数据
- Downloader Middlewares:下载器中间件,位于引擎和下载器之间的钩子框架,主要处理引擎与下载器之间的请求与响应
- Spider Middlewares:Spider中间件,位于引擎与Spider之间的钩子框架,主要处理蜘蛛输入的响应和输出的结果以及新的请求
在scrapy中,一个数据流的流向或者说一次爬取的过程是这样进行的:
- 首先在spider中编写请求的url,相当于引擎问spider想处理那些request请求,这时spider就会做出回应,将已编写的request请求发送给engine引擎;
- engine引擎将spider发送过的的请求发给scheduler调度器,调度器会将request请求排序成队列;
- engine引擎将会请求scheduler调度器是否已将request请求入队,若已入队,则scheduler调度器将请求队列发送给engine引擎;
- engine引擎将scheduler调度器发送过来的的request请求队列,发送给downloader下载器。downloader下载器若成功下了请求的内容,则将response发送给引擎,引擎再将response发送给spider进行处理。若downloader下载器下载出错,则downloader下载器会将出错的请求发送给engine引擎,engine引擎再讲请求发送给scheduler调度器再次进行排队调度;
- spider接收engine引擎发送过来的数据,对数据进行分析。该数据由两部分组成,一部分是我们请求的数据,这部分数据会交给Item、Pipline进行数据存储或者清洗;另一部分是新的请求,spider会将新的请求发送给引擎,然后引擎再将这些新的请求发送到调度器进行排队。然后重复1、2、3、4操作,直到获取到全部的信息为止。
下面我们通过一个官方的scrapy测试网站http://quotes.toscrape.com爬取上面的text,author和tags存入MongoDB数据库中,来了解一下具体scrapy项目代码的构成
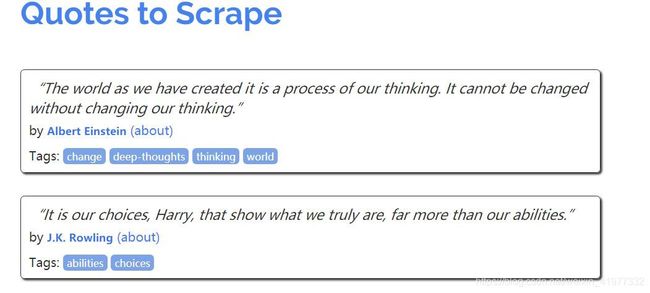
开始一个scrapy项目
大致介绍一下windows下scrapy的安装过程(如果你的windows上的python是通过anaconda安装的,直接conda install Scrapy即可安装,否则参考后面的安装过程),安装scrapy前,先要安装lxml库(通过wheel方式安装),pyOpenSSL(通过pip安装),Twisted(通过pip安装),pyWin32(从https://sourceforge.net/projects/pywin32网站下载exe安装),安装完以上依赖库之后,就可以通过pip install scrapy安装scrapy了,若没有报错,则表明安装完成,在命令行输入scrapy,出现如下画面证明安装完成

新建一个项目,可以在相应目录的命令行下使用如下的命令:
scrapy startproject tutorial_lxy
之后该目录下就会生成一个新的文件夹tutorial_lxy,文件夹的结构如下所示,接下来结合爬虫项目的构建过程来分别对文件夹中的各个模块进行介绍:
spiders
scrapy.cfg为scrapy部署时的配置文件,tutorial_lxy下放置的每一个python文件都是一个Spider,scrapy用它从特定的网页里抓取内容,并解析抓取的结果,可以通过命令行创建一个Spider,比如我们要生成爬取quotes.toscrape.com的Spider,在外面的父tutorial_lxy目录下执行如下命令:
scrapy genspider quotes quotes.toscrape.com
里面的子tutorial_lxy目录下就会生成一个quotes.py,即刚刚创建的Spider,内容如下所示(scrapy中所有自动生成的注释都是英文的,我自己加的注释都是中文注释,不会自动生成):
class QuotesSpider(scrapy.Spider): #继承自scrapy.Spider的爬取类
name = 'quotes' #每个项目唯一的名字,用来区分不同的Spider
allowed_domains = ['quotes.toscrape.com'] #允许爬取的域名,如果初始或后续的请求不是这个域名下的,会过滤掉该请求链接
start_urls = ['http://quotes.toscrape.com/'] #Spider在启动时爬取的url列表,初始的requests请求就是针对该列表内的链接的请求
#被调用的start_urls里面的链接构成的请求requests完成download Middlerware(定义在middlewares.py中)的操作后生成Response作为parse的参数,可以在parse中定义对于response的解析等处理操作
def parse(self, response):
pass
items.py
items.py定义的是Item类,是一种保存爬取数据的容器,使用方法和字典类似,初始状态如下所示:
import scrapy
class TutorialLxyItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
创建的Item需要继承scrapy.Item类,并且定义类型为scrapy.Field的字段(如注释所示),我们这次需要爬取的内容有text,author和tags,因此定义三个字段,如下所示:
import scrapy
class TutorialLxyItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
text = scrapy.Field()
author = scrapy.Field()
tags = scrapy.Field()
接下来我们就可以在Spiders的quotes.QuotesSpider的parse方法中解析reponse的内容,并将其爬取到数据容器TutorialLxyItem中并展示出来,这里我们使用css选择器解析response的内容,将内容写入一个个TutorialLxyItem中并生成(yield),并且通过选择器得到下一页的链接并生成请求(yield),代码如下所示:
import scrapy
from tutorial_lxy.items import TutorialLxyItem
class QuotesSpider(scrapy.Spider):
name = 'quotes'
allowed_domains = ['quotes.toscrape.com']
start_urls = ['http://quotes.toscrape.com/']
def parse(self, response):
quotes=response.css('.quote')
for quote in quotes:
item=TutorialLxyItem()
item['text']=quote.css('.text::text').extract_first()#获取列表中的第一个元素
item['author']=quote.css('.author::text').extract_first()
item['tags']=quote.css('.tags .tag::text').extract()
yield item
next=response.css('.pager .next a::attr("href")').extract_first()
url=response.urljoin(next)#获取下一页的链接
yield scrapy.Request(url=url,callback=self.parse)#对下一页的链接进行request请求并再次执行parse操作
此时在父tutorial_lxy中执行如下命令:
scrapy crawl quotes
即可爬取网页上的内容并显示,如下所示,最开始先会加载配置文件settings.py,之后就会加载middlewares.py中的Downloader Middlewares和Spider Middlewares(这两个模块的作用后面会简要介绍),之后会加载pipelines中定义的pipelines(这里在没有定义pipelines时会为空列表,后面为了能够将爬取结果存储到MongoDB中需要定义相应的Pipelines),之后便是请求该网站的robots.txt,因为没有所以为404,然后请求http://quotes.toscrape.com/开始爬取内容
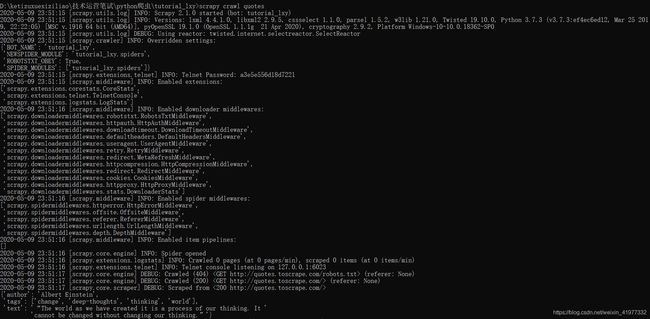
pipelines.py
如果想要进行更复杂的操作,比如对爬取结果进行进行一些筛选操作并将爬取结果保存到MongoDB中,我们可以在pipelines.py中定义Item Pipeline来实现。Item Pipeline作为项目管道,当Item生成后,它会自动被送入Item Pipeline中进行处理。pipelines.py文件的初始状态如下所示:
class TutorialLxyPipeline:
def process_item(self, item, spider):
return item
我们可以看到要实现一个Item Pipeline需要定义一个类并含有process_item()方法,在Settings.py中启用这个Item Pipeline之后,会自动调用这个方法,process_item()方法必须返回包含数据字典或Item对象,或者会抛出DropItem
异常。process_item()方法有两个参数,一个参数是item,每次Spider生成的item都会作为参数传递锅来,另一个参数是spider,即Spider的实例。接下来我们在pipelines.py中实现两个pipelines,一个是TutorialLxyPipeline,筛选掉text长度大于50的Item,另一个是 MongoPipeline,将结果保存到MongoDB中,代码如下所示:
from scrapy.exceptions import DropItem
import pymongo
class TutorialLxyPipeline(object):
def __init__(self):
self.limit=50
def process_item(self, item, spider):
if item['text']:
if len(item['text'])>self.limit:
item['text']=item['text'][0:self.limit].rstrip()+'...'
return item
else:
return DropItem('Missing Text')
class MongoPipeline(object):
def __init__(self,mongo_uri,mongo_db):
self.mongo_uri=mongo_uri
self.mongo_db=mongo_db
@classmethod
def from_crawler(cls,crawler): #类方法classmethod,通过crawler获取全局配置信息(在setting.py中)
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DB')
)
def open_spider(self,spider): #Spider开启时,调用该方法,初始化和MongoDB的连接
self.client=pymongo.MongoClient(self.mongo_uri)
self.db=self.client[self.mongo_db]
def process_item(self,item,spider):
name=item.__class__.__name__ #获取类名TutorialLxyItem
self.db[name].insert(dict(item)) #插入数据
return item
def close_spider(self,spider):
self.client.close()
其中MONGO_URI和MONGO_DB定义在settings.py中,需要在settings.py中添加如下代码:
ITEM_PIPELINES = {
'tutorial_lxy.pipelines.TutorialLxyPipeline': 300,
'tutorial_lxy.pipelines.MongoPipeline': 400,
}
MONGO_URI='localhost'
MONGO_DB='tutorial_lxy'
此时再执行命令scrapy crawl quotes即可将爬取内容存如MongoDB中
middlewares.py简介
middlewares.py中主要定义了各种中间件,比如Downloader Middleware和Spider Middleware,其中Downloader Middleware即下载中间件,他主要有以下两个作用:
- 在Request执行下载之前对request的内容(如headers,proxy等)进行修改
- 在下载后生成的Response发送给Spider之前,对Response进行修改
每个Downloader Middleware主要有以下三个核心方法,即process_requests(request,spider),process_response(request,reponse,spider)和process_exception(requests,exception,spider),分别对应处理request,response和downloader或process_requests()抛出异常的处理.
Spider Middleware是介入到Scrapy和Spider处理机制的钩子框架,当Downloader生成Response之后,Response会被发送给Spider,在发送给Spider之前,Response会首先经过SpiderMiddleware处理,当Spider处理生成Item和Request之后,Item和Request还会经过Spider Middleware处理,所以 Spider Middleware主要有如下三个作用:
- 在Downloader生成的Response发送给Spider之前,也就是在Response发送给Spider之前对Response进行处理。
- 我们可以在Spider生成的Request发送给Scheduler之前,也就是在Request发送给Scheduler之前对Request进行处理。
- 我们可以在Spider生成的Item发送给Item Pipeline之前,也就是在Item发送给Item Pipeline之前对Item进行处理。
每个Spider Middleware都定义了以下一个或多个方法的类,核心方法有4个
- process_spider_input(response,spider),当Response被Spider Middleware处理时调用,
- process_spider_exception(response,exception,spider),当Spider或Spider Middleware的process_spider_input()方法抛出异常时调用
- process _spider_output(response,result,spider),
当Spider处理Response返回结果时调用 - process_start_requests (start_requests,spider),process_start_requests()方法以Spider启动的Request为参数被调用