集群与分布式的区别和Zookeeper集群搭建入门
什么是集群
- 多个节点干相同的事情
- 生活小栗子: 赛龙舟中每个划桨的人都是一个节点, 每个节点做相同的事情, 这就是集群.
什么是分布式
- 多个节点协同完成一件事情, 每个节点做不同的事情
- 生活小栗子: 乐队中有的人弹吉他, 有的人打鼓, 有的人吹号. 并且共同完成一次演出, 这就是分布式.
集群与分布式
- 不管在生活中, 还是在我们的实际项目中, 集群与分布式大多都是同时出现的.
- 生活小栗子: 赛龙舟中划桨的人, 与打鼓的, 人与掌舵的人分别做不同的事情, 却共同完成赛龙舟这件事情, 这就是分布式. 同时划桨的多个人做着相同的事情, 这就是集群. 可见分布式与集群是同时出现的.
- 相同点与区别: 相信看完上面的简述和小栗子, 大家已经对集群和分布式的相同点和区别有了理解, 这里就不多赘述了.
Zookeeper集群的搭建
为什么搭建Zookeeper集群
- 高并发的情况下, 单机版性能不够.
- 小栗子: 我的饭店一开始客人较少, 我招一个厨师炒菜即可. 后来我的饭店客人越来越多, 一个厨师不够用了, 所以就需要再招几个厨师.
- 单机版不具备高可用行.
- 小栗子: 依然是饭店的栗子, 如果我只有一个厨师, 那当我的厨师生病了, 那我的饭店就挂掉了, 显然这样是不具备高可用性的.
Zookeeper的leader选举
-
为什么需要leader选举
- 其实可以类比想一下国家为什么要选举国家总统? 当然是为了更好的治理国家. 为什么需要政府? 只有一个超然于所以团体之上的势力, 才可以统一调度共有资源, 协调各团体关系, 为各团体制定规则, 以及集中力量办大事… 咳, 扯远了, 总之就是为了保证分布式数据的一致性的.
-
什么时候会出现leader选举
-
服务器初始化启动的时候.
小栗子: 回想你大一新生刚刚入学的时候, 是不是班级都会选举一个班长出来?
-
服务器运行期间无法和leader保持连接.
这个更简单了, leader挂掉了, 自然需要重新选举了.
-
-
选举的规则, 也就是说凭什么你当老大
-
服务器ID
比如有三台服务器, 编号分别是1,2,3
那么编号越大在选择算法中的权重越大. (很粗暴, 谁编号大谁就厉害)
-
数据ID
服务器中存放的最大数据ID
值越大说明数据越新, 在选举算法中权重越大.
-
超过半数投票者为leader
这就是选举的核心了, 只要有半数以上投票就是leader了, 后面的即便服务器ID比我高, 那你也只能是following了.
-
-
选举的状态
- LOOKING,竞选状态。
- FOLLOWING,随从状态,同步leader状态,参与投票。
- OBSERVING,观察状态,同步leader状态,不参与投票。
- LEADING,领导者状态。
-
以一个小栗子说明整个选举的过程
假设有五台服务器组成的zookeeper集群, 它们的id从1-5, 同时它们都是最新启动的, 也就是没有历史数据 (所以我们就只需要考虑服务器ID即可, 不用考虑数据了). 假设这些服务器依序启动, 来看看会发生什么。
- 服务器1启动, 先投自己一票, 然后就是looking状态.
- 服务器2启动, 先投自己一票, 然后与服务器1进行通信, 互换选举结果, 由于两者都没有历史数据, 所以id值较大的服务器2胜出, 但是由于没有达到超过半数以上的服务器都同意选举它(这个例子中的半数以上是3), 所以服务器1,2还是继续保持LOOKING状态.
- 服务器3启动, 先投自己一票, 然后进行通信所以理所当然服务器3票数最多, 但这次不一样了, 因为这次已经有3台服务器投给了它, 所以它的票数已经超过了半数, 所以自动当选为leader.
- 服务器4启动, 根据前面的分析, 理论上服务器4应该是服务器1,2,3,4中最大的, 但是由于前面已经有半数以上的服务器选举了服务器3, 所以它只能接收当小弟的命了.
- 服务器5启动, 同4一样,当小弟.
搭建Zookeeper集群
准备工作
接下来我们来搭建一个三个节点的Zookeeper集群(伪集群)。什么是伪集群? 就是在一台服务器上不同端口的三个Zookeeper组成. 注意要不同端口.
- 虚拟机 (下面栗子中使用VMware)
- linux系统 (下面栗子中使用CentOS 6)
- 远程连接linux (下面栗子中使用X Shell)
- 安装好linux后, 在系统中安装好jdk (下面按照了jdk8)
上面几步就不在笔记中写了, 相信有一定linux基础的人都没有问题.
第一步: 上传Zookeeper安装包, 并解压缩
首先可以去官网上下载Zookeeper的安装包 http://mirrors.shu.edu.cn/apache/zookeeper/
也可以到这个网址 http://apache.fayea.com/zookeeper/
第二步: 将解压好的Zookeeper文件夹复制3份出来
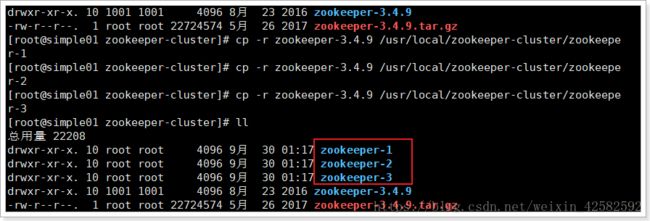
修改配置
第三步: 修改配置文件zoo.cfg 中端口和dataDir的目录
三个Zookeeper都修改一遍, dataDir分别对应自己的data目录, 端口分别为2181, 2182, 2183.
首先修改配置文件的名字为zoo.cfg
-------------------------------------------------
[root@simple01 zookeeper-1]# mkdir data
[root@simple01 zookeeper-1]# cd conf
[root@simple01 conf]# mv zoo_sample.cfg zoo.cfg
然后修改配置文件zoo.cfg 中端口和dataDir的目录
-------------------------------------------------
[root@simple01 conf]# vim zoo.cfg

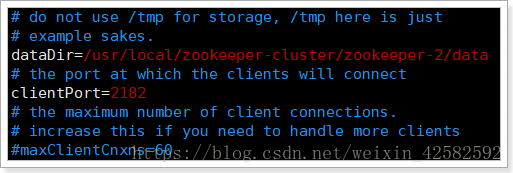

第四步: 给每个Zookeeper一个自己的编号, 放在data目录下的myid文件中
[root@simple01 zookeeper-cluster]# echo 1 > /usr/local/zookeeper-cluster/zookeeper-1/data/myid
[root@simple01 zookeeper-cluster]# echo 2 > /usr/local/zookeeper-cluster/zookeeper-2/data/myid
[root@simple01 zookeeper-cluster]# echo 3 > /usr/local/zookeeper-cluster/zookeeper-3/data/myid
第五步: 在每个节点上配置整个集群的所有服务器IP列表
让所有节点都知道我这个服务器上有多少个节点.
在每个Zookeeper的conf/zoo.cfg配置文件末尾加
server.{编号}={服务器IP}.{Zookeeper之间相互通信的端口}.{Zookeeper投票选举的端口}
---------------------------------------------
server.1=192.168.179.133:2881:3881
server.2=192.168.179.133:2882:3882
server.3=192.168.179.133:2883:3883

第六步: 到这里我们就配置完成了, 接下来就可以测试了
进入Zookeeper的bin目录下, 启动即可
./zkServer.sh start
-------------------------------
可以查看状态
./zkServer.sh status

可以看到, 我们在启动2号Zookeeper的时候, 2号的状态已经是leader了.
安装Zookeeper集群还是挺简单的吧? 我们稍稍总结下我们都做了什么事情.
- 上传解压Zookeeper文件夹, 并复制三份出来
- 修改每个Zookeeper的配置文件夹
- dataDir目录
- 端口号
- 整个集群所有节点的IP列表
- 给每个Zookeeper一个编号
- 我们是在data目录下的myid文件中分别给了1,2,3的编号
测试高可用性
我们选择直接将leader给Stop掉, 模拟leader宕机的现象, 我们来看看是否还能正常工作呢?
进入编号为2的Zookeeper的bin目录中, 执行下面语句
./zkServer.sh stop
按照我们的思考, 当leader挂掉的时候会自动开始选举, 那么编号最大的3号Zookeeper应该成为leader, 那么我们就看下是否如此呢?
进入编号为3的Zookeeper中, 查看状态
./zkServer.sh status
我们看到了下面的结果:

很显然, 我们的3号Zookeeper成为了leader. 集群依然正常运行.
那么, 就有个问题了
问题一: 如果我再把3号Zookeeper停掉呢? 集群还能正常工作吗?
问题二: 在集群中, 有2n+1个节点, 最多允许多少个节点挂掉呢 ?