Hadoop框架概论
分布式系统和集群
分布式概念:
分布式是指将多台服务器集中在一起,每台服务器都实现总体中的不同业务,做不同的事情。
集群:集群是指一组独立的计算机系统构成的一多处理器系统,它们之间通过网络实现进程间的通信,让若干台计算机联合起来工作(服务),可以是并行的,也可以是做备份的。
分布式与集群的区别:
分布式主要工作是分解任务,将职能拆解,多个人在一起做不同的事
集群:集群主要是将同一个业务,部署在多个服务器上,多个人在一起做同样的事。
Hadoop框架概论
Hadoop狭义解释
Hadoop是Apache旗下的一个用Java语言实现开源软件框架,是一个存储和计算大规模数据的软件平台。
Hadoop是Apache Lucene创始人 Doug Cutting创建的。起源一个Nutch项目。
Hadoop指Apache这个开源框架,核心组件有:
HDFS(分布式文件系统),解决海量数据存储
MAPREDUCE(分布式运算编程框架),解决海量数据计算。
YARN(作为调度和集群资源管理的框架),解决资源任务调度
广义解释
广义上来说,Hadoop通常是指一个更广泛的概念-Hadoop生态圈
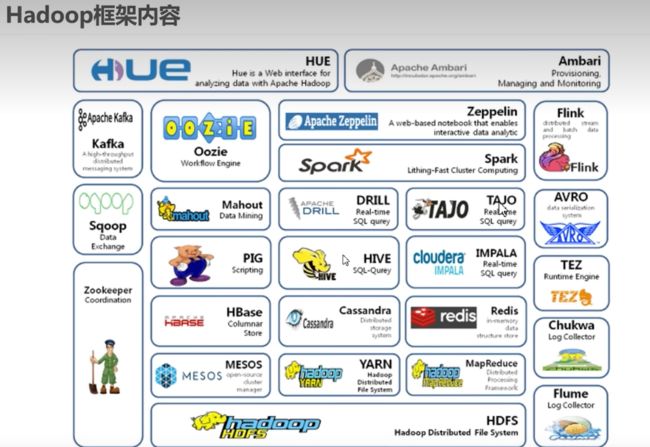
其中重点的包括:Kafka、Spark、Flink、Hive、HBase、Zookeeper、Yarn、HDFS、MapReduce、
Hadoop框架版本
通用版本:
1、1.x版本,hadoop的第二代开源版本
2、2.x版本,架构产生重大变化,引入Yarn平台许多新特性,是主流版本
3、3.x版本,该版本是最新版本,但是还不太稳定
发行版:
开源社区版本和商业版本
开源社区版:指由Apache软件基金会维护的版本,是官方维护的版本体系,版本丰富,兼容性差。
商业版本:指由第三方商业公司在社区版Hadoop基础上进行了修改,整合以及各个服务组件兼容性测试而发行的版本,比较著名的有cloudera的CDH等。
Hadoop架构
Hadoop架构模块1.0 和2.0
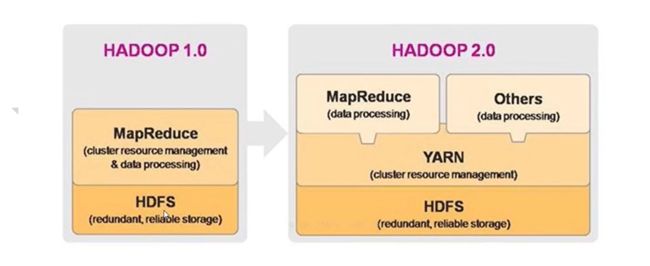
1.0包含两部分MapReduce 负责计算,HDFS负责存储
2.0多一个Yarn负责分布式资源调度
Hadoop2.x架构内部模型
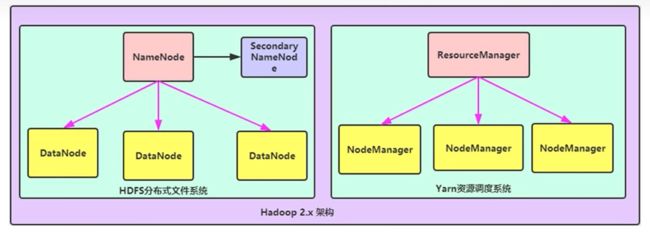
HDFS模块:
NameNode:集群中的主节点,主要用于管理集群中的各种数据,
SecondaryNameNode:主要能用于hadoop中元数据信息的辅助管理
DataNode:集群中的从节点,主要用于存储集群中的各种数据
数据计算核心模块:
ResourceManager:接手用户的计算请求任务,并负责集群的资源分配
NodeManager:负责执行主节点分配的任务
Hadoop2.x架构模型-MapReduce分布式计算模型
Map分,Reduce是合

Hadoop模块之间的关系(HDFS、MapReduce、Yarn)
- MapReduce计算需要的数据和产生的结果需要HDFS来进行存储。
- MapReduce的运行需要由Yarn集群来提供资源调度
Hadoop集群搭建
集群简介:
Hadoop集群具体来说包含两个集群:HDFS集群(消耗硬盘资源)和Yarn(消耗内存资源),两者逻辑上分离,但是物理上常在一起。
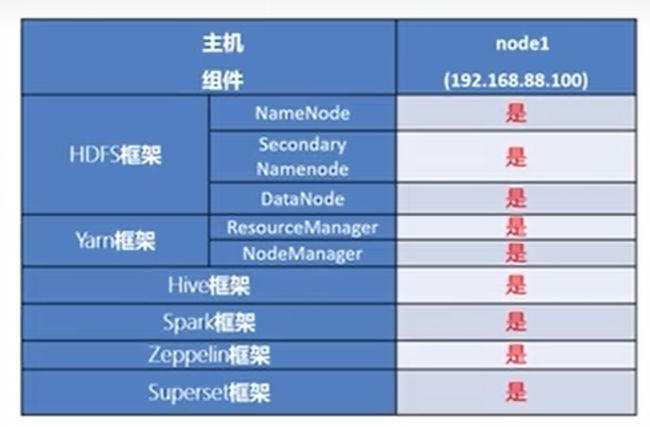
HDFS集群
NameNode(主节点)、DataNode(从节点)、SecondaryNameNode
Yarn集群
ResourceManager(主节点)、NodeManager(从节点)
集群搭建方式:
Standalone mode(单机模式)
单机模式,1个机器上运行HDFS的NameNode和DataNode、YARN的ResourceManager和Nodemanager,主要用于学习和调试
Cluster mode(集群模式)
集群模式主要用于生产环境部署,会使用N台主机组成一个Hadoop集群,这种部署模式下,主节点和从节点会分开部署在不同的机器上。
单机模式,windows系统运行内存至少要8G。
集群模式,windows内存至少16G

Hadoop集群使用
Hadoop启动和关闭-单机模式
- 启动虚拟机
- 连接虚拟机
- 集群一键启动和关闭
一键启动大数据环境
cd /export/onekye/
./start-all.sh
一键关闭大数据环境
cd /export/onekye/
./stop-all.sh
- 查看启动进程 jps,查看java相关的进程
- 查看HDFS页面
通过NameNode
Hadoop集群实践-单机模式
HDFS使用
从Linux本地上传一个文本文件到hdfs的/目录下
将/root目录下的initial-setup-ks.cfg文件上传到HDFS的根目录
cd /root
hadoop fs -put initial-setup-ks.cfg /
通过查看HDFS页面,看文件是否上传成功
MapReduce使用
在Hadoop安装包的share/hadoop/mapreduce下有官方自带的mapreduce程序,我们可以使用如下命令进行运行测试。示例hadoop-mapreduce-example-2.7.5.jar。
计算圆周率
hadoop jar /export/server/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar pi 2 10
2代表启动的线程。
Hadoop启动和关闭-集群模式
1、启动三台虚拟机
2、使用CRT链接主机
3、集群-一键启动和关闭
一键启动脚本
cd /export/onekey/
4、查看启动进程jps