Kafka专项测试
Kafka专项测试
测试Kafka节点包括旧版本三台节点(183,186,187),以及新版本三台节点(180,181,182)
1.Kafka性能测试
1.1.集群资源情况
| 节点 | 磁盘使用率(总大小) | 内存使用率(总大小) | CPU使用率 | CPU配置 | 系统 |
|---|---|---|---|---|---|
| 192.168.1.183 | 43.45% (900.05GB) | 81.40% (62.80 GB) | 16% | Intel® E5-2620 v4 @ 2.10GHz 32核 | Red Hat 7.3 |
| 192.168.1.186 | 34.85% (900.05GB) | 57.35%(62.80 GB) | 9% | Intel® E5-2620 v4 @ 2.10GHz 32核 | Red Hat 7.3 |
| 192.168.1.187 | 29.40% (900.05GB) | 26.00%(62.80 GB) | 3% | Intel® E5-2620 v4 @ 2.10GHz32核 | Red Hat 7.3 |
| 192.168.1.180 | 7.09%(20804.20GB) | 20.39%(251.51GB) | 5% | Intel® Gold 5118 @ 2.30GHz 48核 | CentOS 7.5 |
| 192.168.1.181 | 9.48%(20804.20GB) | 20.14%(251.51GB) | 5% | Intel® Gold 5118 @ 2.30GHz 48核 | CentOS 7.5 |
| 192.168.1.182 | 6.77%(20804.20GB) | 21.35%(251.51GB) | 11% | Intel® Gold 5118 @ 2.30GHz 48核 | CentOS 7.5 |
1.2.测试方式
使用kafka-producer-perf-test.sh脚本测试,这种方式缺点是不能准确测延迟,但是吞吐量可以准确测试。
命令: ./bin/kafka-producer-perf-test.sh --topic zzltopic --throughput -1–num-records 100000 --record-size 1024 --producer.config ./config/producer.properties
相关参数说明:
–Topic:指定Kafka集群的topic名称
–num-records:总共需要发送的消息数
–record-size: 每个记录的字节数
–throughput:每秒钟发送的记录数
–producer.config:生产者配置文件
–bootstrap.servers:kafka集群的broker地址
1.3.Kafka参数测试
1.3.1.压缩方式(compression.type)
创建一个Partition为3的主题

参数compression.type:指定topic最终的数据压缩方式,如果这是为producer,那么将保留Producer的压缩方式
| 压缩方式 | 说明 |
|---|---|
| producer | 默认方式,通过producer保持原始的压缩代码集,压缩类型由producer指定 |
| uncompressed | 不压缩 |
| gzip | Linux常用压缩方式 |
| snappy | Snappy 是一个 C++ 的用来压缩和解压缩的开发包。其目标不是最大限度压缩或者兼容其他压缩格式,而是旨在提供高速压缩速度和合理的压缩率。 |
| lz4 |
目前综合来看效率最高的压缩算法,更加侧重压缩解压速度,压缩比并不是第一,本质上是时间换空间。
1、在后台管理界面更改Kafka服务端参数配置,并同步到各个节点,重启服务

2、使用脚本测试
![]()
Topic属性:

测试解释
![]()
测试总数据条数10000000,每条数据大小1024B,测试两次
Producer测试结果:
![]()
![]()
Uncompressed测试结果:
![]()
![]()
Gzip测试结果:
![]()
![]()
Snappy测试结果:
![]()
![]()
Lz4测试结果:
![]()
![]()
新Kafka集群:
Producer结果:
![]()
Gzip结果:
![]()
| 压缩方式 | 吞吐量(单位:M/s) | 吞吐量(单位:千条/s) | 平均延迟(单位:ms) | 最高延迟(单位:ms) | 耗时(单位:s) |
|---|---|---|---|---|---|
| producer | 168.82 | 172.876 | 175.74 | 338 | 57 |
| Uncompressed | 163.66 | 167.586 | 181.16 | 425 | 59 |
| Gzip | 67.39 | 69.010 | 439.94 | 1082 | 144 |
| Snappy | 137.34 | 140.639 | 216.17 | 594 | 71 |
| lz4 | 128.53 | 131.610 | 231.08 | 546 | 75 |
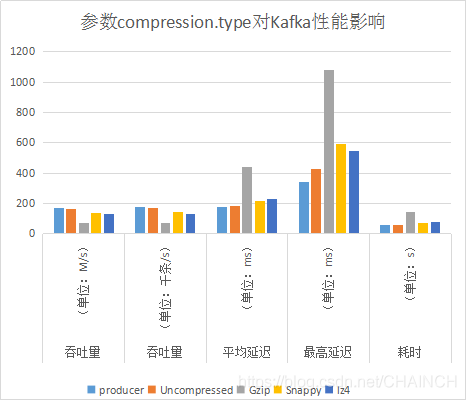
分析:单纯从多次测试得到的数据来看,压缩方式的改变能够很大地影响Kafka吞吐量。也可以看出Gzip这种压缩方式不可取,其他压缩方式仅从数据角度看,也没有提升吞吐量,这和理论是相反的。
同样在新集群下测试结果也是一样如下。说明这种方式的压缩,并不能提升吞吐量(从数据而言)。
结论:建议使用默认方式:producer
1.3.2.确认方式(acks)
| 总消息数(条) | Broker数量 | Acks参数值 | Topic数量 | Partition数量 | Partition备份数量 | 每条消息大小 | 消息记录条数 | 吞吐量(单位:M/s) | 平均延迟(单位:ms) | 最高延迟(单位:ms) |
|---|---|---|---|---|---|---|---|---|---|---|
| 1000万 | 3 | -1 | 2 | 236 | 2 | 2000 | 5000 | 平均9.54M/S | 0.6ms | 307ms |
| 1000万 | 3 | 1 | 2 | 236 | 2 | 2000 | 5000 | 平均9.54M/S | 3.13ms | 3006ms |
| 一亿 | 3 | -1 | 2 | 236 | 2 | 5000 | 20000 | 95M/S | 203ms | 16503ms |
| 一亿 | 3 | 1 | 2 | 236 | 2 | 5000 | 20000 | 72M/S | 369ms | 18916ms |
以上时本次不同Ack值测试的数据,分别测一千万条、一亿条数据,数据都显示-1比1消耗时间更少,性能更优。和官网给的结论恰恰相反。
注释:0、1 和 all。
0:第一种选择是把acks参数设置为0,意思就是我的KafkaProducer在客户端,只要把消息发送出去,不管那条数据有没有在哪怕Partition Leader上落到磁盘,我就不管他了,直接就认为这个消息发送成功了。
如果你采用这种设置的话,那么你必须注意的一点是,可能你发送出去的消息还在半路。结果呢,Partition Leader所在Broker就直接挂了,然后结果你的客户端还认为消息发送成功了,此时就会导致这条消息就丢失了。
1:第二种选择是设置 acks = 1,意思就是说只要Partition Leader接收到消息而且写入本地磁盘了,就认为成功了,不管他其他的Follower有没有同步过去这条消息了。
这种设置其实是kafka默认的设置,大家请注意,划重点!这是默认的设置
也就是说,默认情况下,你要是不管acks这个参数,只要Partition Leader写成功就算成功。
但是这里有一个问题,万一Partition Leader刚刚接收到消息,Follower还没来得及同步过去,结果Leader所在的broker宕机了,此时也会导致这条消息丢失,因为人家客户端已经认为发送成功了。
-1:最后一种情况,就是设置acks=all(-1),这个意思就是说,Partition Leader接收到消息之后,还必须要求ISR列表里跟Leader保持同步的那些Follower都要把消息同步过去,才能认为这条消息是写入成功了。
如果说Partition Leader刚接收到了消息,但是结果Follower没有收到消息,此时Leader宕机了,那么客户端会感知到这个消息没发送成功,他会重试再次发送消息过去。
此时可能Partition 2的Follower变成Leader了,此时ISR列表里只有最新的这个Follower转变成的Leader了,那么只要这个新的Leader接收消息就算成功了
建议:基于公司数据完整考虑,建议设置为-1。保证不丢失。
1.3.3.其他参数
1.3.3.1.batch.size
当多个消息发往 同一个分区,生产者会将他们放进同一个批次,该参数指定了一个批次可以使用的内存大小,按照字节数进行计算,不是消息个数,当批次被填满,批次里面所有得消息将会被发送,半满的批次,甚至只包含一个消息也可能会被发送,所以即使把批次设置的很大,也不会造成延迟,只是占用的内存打了一些而已。但是设置的太小,那么生产者将会频繁的发送小,增加一些额外的开销。
1.3.3.2.linger.ms
该参数指定了生产者在发送批次之前等待更多消息加入批次的时间。批次填满或linger.ms达到上限时把批次发送出去。默认情况下,只要有可用的线程, 生产者就会把消息发送出去,就算批次里只有一个消息。把linger.ms设置成比0 大的数,让生产者在发送批次之前等待一会儿,使更多的消息加入到这个批次。虽然这样会增加延迟,但也会提升吞吐量(因为一次性发送更多的消息,每个消息的开销就变小了)。max.in.flight.requests.per.connection指定了生产者收到服务器响应之前可以发送多少个消息。它的值越高,将会消耗更多的内存,不过也会提升吞吐量。设置为1,可以保证消息是按照发送的顺序写入服务器。即使发生了重试。
kafka可以保证一个分区内的消息是有序的,如果生产者按照一定的顺序发送消息,那么broker会按照这个顺序将他们写到分区中,消费者也会按照同样的顺序消费他们,但是!如果设置了retries大于1,而设置了max.in.flight.requests.per.connection也是大于1的数,比如是2,那么当消息批次1发送之后,尚未收到服务器的响应,此时消息批次2也被发送,但是,消息批次1失败了,消息批次2成功了,那么此时由于retries设置了大于1的数,所以出发了重试机制,那么消息批次1开始进行重试发送,此时假设消息批次1发送成功了,那么这样的话,尽管消息发送的顺序是:消息批次1,消息批次2,但是最终服务端的顺序确实消息批次2,消息批次1。顺序被打乱了。所以如果对于顺序有着严格要求,最好将 max.in.flight.requests.per.connection设置为1,将retries设置大于1的数。这样即使发生重试,也不会打乱消息的先后顺序。
1.3.3.3.background.threads
Broker后台任务处理的线程数目。数据量较大的情况下,可适当调大此参数,以提升Broker处理能力,参考值10。
1.3.3.4.num.replica.fetchers
副本向Leader请求同步数据的线程数,增大这个数值会增加副本的I/O并发度,参考值1。
1.3.3.5.num.io.threads
Broker用来处理磁盘I/O的线程数目,这个线程数目建议至少等于硬盘的个数,参考值8。
1.3.3.6.KAFKA_HEAP_OPTS
Kafka JVM堆内存设置。当Broker上数据量较大时,应适当调整堆内存大小,参考值-Xmx6G -Xms6G
1.4.Partition数量
在旧Kafka(187,188)集群测试,10000000条数据,每条数据1024B
P10
![]()
P20
![]()
P30
![]()
P40
![]()
P50
![]()
P60
![]()
P70
![]()
P80
![]()
P90
![]()
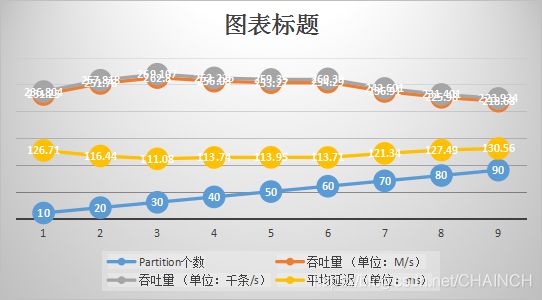
| Partition个数 | 吞吐量(单位:M/s) | 吞吐量(单位:千条/s) | 平均延迟(单位:ms) | 最高延迟(单位:ms) |
|---|---|---|---|---|
| 2 | 129.80 | 132.915 | 229.01 | 638 |
| 3 | 142.28 | 145.696 | 208.74 | 430 |
| 4 | 180.80 | 185.137 | 164.11 | 419 |
| 5 | 179.11 | 183.412 | 156.06 | 441 |
| 6 | 208.22 | 213.220 | 141.88 | 619 |
| 7 | 204.42 | 209.328 | 144.40 | 383 |
| 8 | 230.67 | 236.211 | 128.03 | 985 |
| 9 | 214.11 | 219.476 | 137.47 | 396 |
| 10 | 231.25 | 236.804 | 126.71 | 606 |
| 15 | 238.94 | 244.672 | 112.96 | 808 |
| 16 | 251.46 | 257.493 | 117.05 | 465 |
| 17 | 248.99 | 254.965 | 117.68 | 564 |
| 18 | 248.12 | 254.078 | 118.66 | 407 |
| 19 | 247.51 | 253.447 | 118.61 | 617 |
| 20 | 251.78 | 257.818 | 116.44 | 611 |
| 30 | 262.80 | 269.107 | 111.08 | 590 |
| 40 | 256.08 | 262.226 | 113.74 | 602 |
| 50 | 253.27 | 259.350 | 113.95 | 701 |
| 60 | 254.29 | 260.390 | 113.71 | 842 |
| 70 | 236.91 | 242.601 | 121.34 | 384 |
| 80 | 225.98 | 231.401 | 127.49 | 1262 |
| 90 | 218.68 | 223.924 | 130.56 | 1181 |
 新Kafka集群测试结果:
新Kafka集群测试结果:
| Partition个数 | 吞吐量(单位:M/s) | 吞吐量(单位:千条/s) | 平均延迟(单位:ms) | 最高延迟(单位:ms) |
|---|---|---|---|---|
| 1 | 1000000 | 1 | 5501.911 | 107.46 |
| 10 | 1000000 | 10 | 9830.908 | 192.01 |
| 50 | 1000000 | 50 | 10695.873 | 208.9 |
| 100 | 1000000 | 100 | 9377.416 | 182.37 |
| 200 | 1000000 | 200 | 9730.75 | 190.05 |
| 30 | 193.70 | 198.354 | 146.75 | 1209.00 |
| 40 | 205.88 | 210.819 | 136.80 | 1013.00 |
| 50 | 208.21 | 213.211 | 134.71 | 1025 |
| 60 | 110.66 | 113.320 | 258.89 | 36445 |
从图可得:1、随着Partition数量的增加(10-30),Kafka的吞吐量随之增大,延迟随着降低;2、但是当增加到一定程度(40-60),Kafka性能趋于稳定;3、随着partition继续增大(70-90),Kafka性能出现下降
分析:Kafka在资源充足情况下,Partition数量越多,并行数量越多,吞吐量越高,延迟越低。但是随着Partition继续增加,Kafka性能下降。其一,是因为资源不能足够分配到多个Partition,性能下降;其二,越多的分区需要打开更多的文件句柄,导致性能下降;其三,越多的Partition,需要同步备份的数量越多
结论:通常情况下,越多的partition会带来越高的吞吐量,但是同时也会给broker节点带来相应的性能损耗和潜在风险。因此需要根据自身broker节点的实际情况来设置partition的数量。如当前Kafka集群有3个Broker节点,其中一台节点损坏,最佳Partition数量为30左右。
1.5.备份数量
备份数量为1,2,3,partitions为3,消息大小为10k,消息数量为1000w
| 备份数量 | partitions | 数据量 | 每秒钟接收数据(条) | 每秒钟接受数据大小(M) | 最大延时 | 平均延时 |
|---|---|---|---|---|---|---|
| 1 | 3 | 1000w | 8267.400 | 80.74 | 245.21 | 824.00 |
| 2 | 3 | 1000w | 5297.788 | 51.74 | 383.95 | 995.00 |
| 3 | 3 | 1000w | 7849.170 | 76.65 | 158.68 | 915.00 |
分析:在Broker节点为3的前提下,调整备份数量对kafka的吞吐量没有明显的变化。但是可以看出变化趋势,随着备份数量增加,Kafka吞吐量是下降的。
结论:kafka的备份数量增加,相应增加数据的冗余性,但是考虑到数据的高可用场景,replication.factor>=3,即副本数至少是3个。备份数量的增加会增加系统的稳定性,允许(N-1)个broker宕机,但是系统磁盘的使用率会更高。
1.6.Broker节点数量
Broker节点=3
![]()
Broker节点=4
![]()
Broker节点=5
![]()
![]()
![]()
![]()
| Broker节点数量 | Partiton数量 | 吞吐量(单位:M/s) | 吞吐量(单位:千条/s) | 平均延迟(单位:ms) | 最高延迟(单位:ms) |
|---|---|---|---|---|---|
| 3 | 3 | 94.55 | 96.818 | 313.22 | 1615 |
| 3 | 50 | 208.9 | 213.314 | 241.31 | 2213 |
| 4 | 3 | 132.67 | 135.851 | 221.79 | 1291 |
| 4 | 50 | 218.3 | 223.641 | 203.12 | 785 |
| 5 | 3 | 107.47 | 110.053 | 273.21 | 2754 |
| 5 | 30 | 249.38 | 255.369 | 115.35 | 1017 |
| 5 | 50 | 233.90 | 239.509 | 121.54 | 1229 |
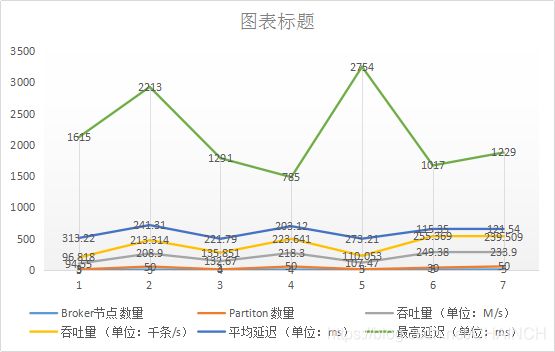
数据显示:
随着节点数量增多,Kafka吞吐量增加。但是相同Partition的Topic,随着Broker节点的增加,性能并没有明显增加。原因是因为增加Broker节点增加了吞吐量,是由于Partition数量随之增加带来的处理数据能力(资源足够前提下)。
结论:
增加Broker节点,需要同时增加Partition,才能发挥增大Broker真正吞吐量;同时增加Broker集群容量增加。
2.数据安全性测试
2.1.数据不丢失
在生产端生产数据时,不仅要保证数据不丢失,同时需要尽量保证数据有且生产一次。
保证数据不丢失、不重复,需要设置副本数,一般地,副本数量为3份。同时生产者生产消息时,同步到Kafka服务器告知生产者确认收到消息,并同步到副本,且副本同步列表ISR必须大于等于1。
具体参数如下:
创建Topic时 --replication-factor设置3
Acks = -1 为安全起见,需同步到所有列表
min.insync.replicas = 1 至少大于等于1
2.2.节点数据容量
华为HD集群设置的磁盘使用率达到80%开始告警(可根据情况对应修改配置参数)
当前环境kafka单独分配一个1.8T磁盘用于存储数据,理论上kafka容量可以达到1.8T,当磁盘容量到达1.44T后,集群会出现告警提示。
3.组件对接
略
4 .采集组件对接Kafka性能测试
4.1.Flume文件实时采集组件测试
4.1.1.kafka的topic分区数
由下表可知,kafka的topic分区数在30个左右,采集速度为15.9Mb/s,相比分区数为10或者50都更快,表明kafka的topic分区存在一个最优点,并非越多越好。
| channel类型 | Source类型 | Sink类型 | 采集文件大小 | Batchsize | kafka的partition | Kafka的acks | 采集总量(行) | 总耗时(s) 采集速度(mb/s) | 采集速度(行/s) |
|---|---|---|---|---|---|---|---|---|---|
| kafkaChannel | TailDir | Kafka | 953.68 | 10000 | 10 | -1 | 10000000 | 65 | 14.7 |
| kafkaChannel | TailDir | Kafka | 953.68 | 10000 | 30 | -1 | 10000000 | 60 | 15.9 |
| kafkaChannel | TailDir | Kafka | 953.68 | 10000 | 50 | -1 | 10000000 | 63 | 15.1 |
4.1.2.flumeBatchSize,批次写入Kafka的Event个数
由下表可知,kafka的flumeBatchSize在10万左右,采集速度为29.8Mb/s,相比flumeBatchSize为1万或者100万都更快,表明kafka的flumeBatchSize存在一个最优点,并非越多越好。此外,flume的客户端宕机重启,可能导致一个批次的数据重复,批次越大,数据重复量越多。
| channel类型 | Source类型 | Sink类型 | 采集文件大小 | Batchsize | kafka的partition | Kafka的acks | 采集总量(行) | 总耗时(s) 采集速度(mb/s) | 采集速度(行/s) |
|---|---|---|---|---|---|---|---|---|---|
| File Channel | TailDir | Kafka | 953.68 | 100000 | 30 | -1 | 10000000 | 406 2.3 | 24631 |
| memoryChannel | TailDir | Kafka | 953.68 | 100000 | 30 | -1 | 10000000 | 31 30.8 | 322581 |
| kafkaChannel | TailDir | Kafka | 953.68 | 100000 | 30 | -1 | 10000000 | 32 29.8 | 312500 |
注:以上测试其他条件如下
1、测试采用一个agent节点采集本地文件发送至kafka集群;
2、Topic的副本数为2;
3、所用机器为10.28.133.180服务器。
4.2.DSG数据库实时采集组件测试
4.2.1.测试环境基本信息
| 软件环境 | 详情描述 |
|---|---|
| Oracle版本 | oracle11g、oracle12c |
| Kafka 版本 | kafka2.11-1.10 |
| 测试 工具 | SuperSync(DSG) |
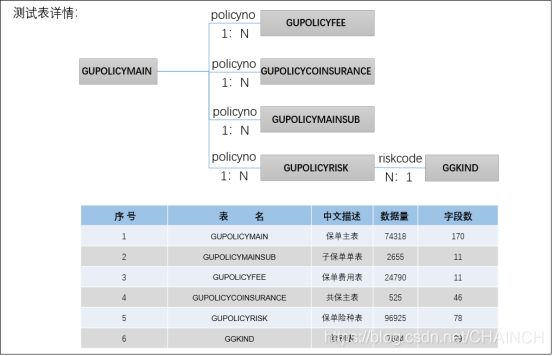
4.2.2. 场景一
单表全量同步
测试过程:
oracle数据准备,分别准备10W、100W、500W量级的三张表;
清除(clean)、启动DSG目标端源端进程;
进行kafka数据后台消费至指定文件;
10W表DSG全量同步、100W表DSG全量同步





结果分析:
此次测试共使用三张表,表数据量大小并不影响DSG加载数据效率(均值1MB/s),10W数据量kafka花费107s进行消费写入文件,100W数据量kafka花费97s进行消费写入文件,500W数据量kafka花费107s进行消费写入文件。
综上所述:
DSG加载数据慢,成线性曲线成长,数据文件越大,加载越慢。
kafka消费数据并行写入文件,时间差异不大,即:DSG加载数据时kafka可以同时消费加载完成数据。
4.2.3. 场景二
测试用例:单表实时同步
测试过程:
oracle数据准备;
清除(clean)、启动DSG目标端源端进程;
进行kafka数据后台消费至指定文件;


结果分析:
此次测试共使用9条数据插入500W表,加载数据共计耗时12s,kafka使用118s消费数据写入文本文件。
4.2.4. 场景三
测试用例:多表全量同步
测试目的:
测试多表全量同步的同步时间及同步准确性
测试过程:
oracle数据准备;
清除(clean)、启动DSG目标端源端进程;
进行kafka数据后台消费至指定文件;

统计测试结果。
| Table | Rows | Size(MB) | BTime | ETime | UTm(s) | AS(MB/s) |
|---|---|---|---|---|---|---|
| 6 | 206216 | 27.47 | 2019-12-16:16:16:44 | 2019-12-16:16:17:24 | 40 | 0.69 |
结果分析:
此次测试共使用6张表,共计206216条数据,DSG加载数据共消耗40s,加载效率0.69MB/s。多表数据同步无误。
4.2.5. 场景四
测试用例:多表实时同步
测试目的:
测试多表全量增量实时同步的同步时间及同步准确性
测试过程:
oracle数据准备;
后台执行可执行sql文件【realtime.sql】;
进行kafka数据后台消费至指定文件,如图1;
统计测试结果。
