Day47-JVM字节码(常量池、访问标志、方法表)
JVM字节码(常量池、访问标志、方法表)
- 常量池(constant pool)
- 常量池的总体结构
- 访问标志(Access_Flag)
- 方法表(methods)
- Code结构
- attribute_length
- max_stack
- max_locals
- code_length
- handler_pc
- LineNumberTable

常量池(constant pool)
紧接着主版本号之后就是常量池入口,一个Java类中定义的很多信息都是由常量池来维护和描述的,可以将常量池看作是Class文件的资源仓库,比如说Java类中定义的方法与变量信息,都是存储在常量池中。
常量池中主要存储两类常量:字面量与符号引用。
字面引用:如文本字符串,Java中声明为final的常量值等,而符号引用如类和接口的全局限定名,字段的名称和描述,方法的名称和描述符等。
常量池的总体结构
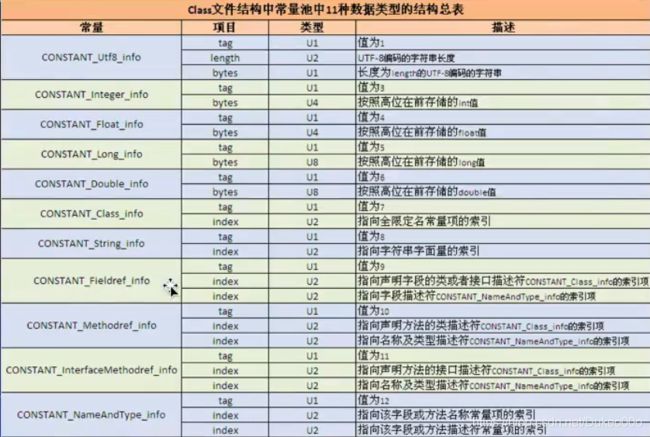
Java类所对应的常量池主要由常量池数量与常量池数组(常量表)这两部分共同构成。
常量池数量紧跟在主版本号后面,占据2个字节。
常量池数组则紧跟在常量池数量之后(从第11个字节开始)。
常量池数组中不同的元素的类型、结构都是不同的,长度当然也就不同;但是,每一种元素的第一个数据都是一个U1类型,该字节是个标志位,占据1个字节。JVM在解析常量池时,会根据这个U1类型来获取元素的具体类型。(U2两个字节、U4四个字节)
值得注意的是,常量池数组中元素的个数 = 常量池个数 - 1(其中0暂时不用),目的时满足某些常量池索引值的数据在特定情况下需要表达“不引用任何一个常量池”,根本原因在于,所以为0也是一个常量(保留常量),只不过他不位于常量表(常量池数组)中,这个常量就对应null值;所以,常量池的索引从1而非0开始。
在JVM规范中,每个都变量/字段都有描述信息,描述信息主要的作用是表述字段的数据类型、方法的参数列表(包括数量、类型与顺序)与返回值。根据描述符规则,基本数据类型和代表无返回值的void类型都用一个大写字符来表示,对象类型则使用字符L加对象的全限定名称来表示。为了压缩字节码文件的体积,对于基本数据类型,JVM都只使用一个大写字母来表示,如下所示:
- B - byte
- C - char
- D - double
- F - float
- I - int
- J - long
- S - short
- Z - boolean
- V - void
- L - 对象类型(Ljava/lang/String;)
对于数组类型来说,每一个维度使用一个前置的 [ 来表示,如int[] 被记录为[I , String[] []被记录为[[L/lang/String;
用描述符描述方法时,按照先参数列表,后返回值的顺序来描述。参数列表按照参数的严格顺序放在一组()之内,如方法:
String getNameByIdAndNickname(int id, String name)
的描述为:
(I,Ljava/lang/String;)Ljava/lang/String;
访问标志(Access_Flag)
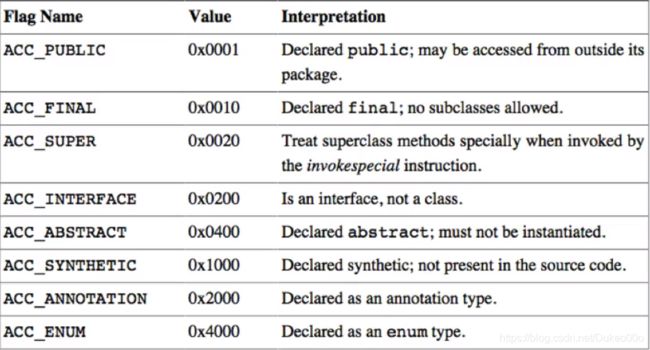
占据2个字节
取并集(00 21)就是ACC_PUBLIC、 ACC_SUPER,
方法表(methods)
U2 access_flags
U2 name_index
U2 descriptor_index
U2 attrlbutes_count
attribute_info attribute{
U2 attribute_name_index
U4 attribute_length(属性长度)
U1 info[attribute_length]
}
Code结构
Code attribute的作用是保存该方法的结构
Code_attribute{
U2 attribute_name_index;
U4 attribute_length;
U2 max_stack;
U2 max_locals;
U4 code_length;
U1 code[code_length];
U2 exception_table_length;{
U2 start_pc;
U2 end_pc;
U2 handler_pc;
U2 catch_type;
} exception_table[exception_table_length];
U2 attributes_count;
attribute_info attributes[attributes_count];
}
attribute_length
表示attribute所包含的字节数
max_stack
表示这个方法运行的任何时刻所能达到的操作数栈的最大深度
max_locals
表示方法执行期间创建的局部变量的数目
code_length
表示该方法所包含的字节码的字节数以及具体的指令码
具体字节码即是
handler_pc
表示处理异常的代码的开始处
LineNumberTable
这个属性用来表示code数组中的字节码和Java代码行数之间的关系
LineNumberTable_attribute{
U2 attribute_name_index;
U4 attribute_length;
U2 line_number_table_length;{
U2 start_pc;
U2 line_number;
} line_number_table[ line_number_table_length ];
}