MongoDB 学习笔记(五):固定集合、GridFS文件系统与服务器端脚本
一、count、distinct与group
1、count函数:查询文档数,如下图:

2、distinct:去重,用法:db.runCommand({distinct:"集合名", key:"查询的键"}),如下图:

3、group:分组,语法如下:首先会按照key指定的键进行分组,每组的每一个文档都要执行$reduce指定的方法,该方法接收2个参数,一个是组内本条文档,一个是累加器数据。
db.runCommand({group:{
ns: 集合名,
key: 分组的键,
initial: 初始化累加器,
$reduce: 组分解器,
condition: 条件,
finalize: 组完成器
}})比如,查询每个班中年龄大于18岁,得分最高的学生信息,如下图:

而使用finalize组完成器,可以对最终要返回的结果集加以额外的修饰,如下图:

4、用函数格式化分组的键
如下图,最后一条文档不包含class这个键,而有clAss这个键。

在分组时却要把该条文档的clAss这个键当作class键进分组,那么可以使用函数格式化分组的键,如下图:

二、数据库命令操作
1、命令执行器runCommand
之前有说过这个命令,也有使用过。比如删除集合可以使用db.集合名.drop(),而使用该命令执行drop命令也可以删除一个集合:db.runCommand({drop: "集合名"})。
2、查询MongoDB提供的可以供runCommand执行的命令
- shell中查看:db.listCommands()。
- 登录数据库服务器web端:http://localhost:28017/_commands。前提是在启动数据库服务时加入了rest参数,如下图:

3、常用命令
- 查询服务器版本与主机操作系统等信息

- 查询某个集合的详细信息:

- 查询操作某个集合的最后一次错误信息:

三、固定集合
1、创建一个空的普通集合:db.createCollection("集合名")

2、创建一个新的固定集合,要求大小是100字节(?),且可以存储5个文档

3、把一个普通集合转换成固定集合

4、固定集合的特性
- 如果在固定集合文档数达到指定的最大文档数量时继续插入文档,它会删除集合中最后一个文档,然后在该位置插入新的文档。

- 固定集合的顺序是确定的,所以查询速度是非常块的。
5、反向排序(对于普通集合和固定集合都适用)
当使用find函数查询集合时,如果不指定任何排序规则,默认就是按照插入的顺序进行排序的,等同于使用sort函数,并指定$natural键为1(大于-1的数字即可),如下图:

指定$natural键小于0,就可以按照插入顺序的反向顺序进行排序,如下图:

6、尾部游标
这是个特殊的只能用在固定集合上的游标,它在没有结果的时候也不会自动销毁,而是一直等到结果的到来。shell中不支持,一些高级的驱动才支持。
四、GridFS文件系统
1、GridFS是MongoDB自带的文件系统。
2、上传一个文件到GridFS文件系统中:mongofiles -d 数据库名字 -l "要上传的文件的完整路径名" put "上传后的文件名"。如下图:

然后在mdb数据库中就会多出2个集合,它们存储了GridFS文件系统的所有文件信息,查询这两个集合就能看到上传的那个文件的一些信息,如下图:

3、从GridFS文件系统中下载一个文件到本地:mongofiles -d 数据库名字 -l "将文件保存在本地的完整路径名" get "GridFS文件系统中的文件名",如下图:如果不写-l以及后面的路径参数,则保存到当前位置。

4、查看GridFS文件系统中所有文件:mongofiles -d 数据库名字 list,如下图:

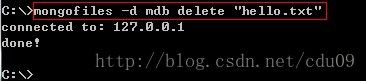
5、删除GridFS文件系统中的某个文件:mongofiles -d 数据库名字 delete "文件名",如下图:
五、服务器端脚本
1、服务器端运行eval,如下图:

2、JavaScript的存储
在数据库服务器端可以保存js变量或者函数到system.js这个特殊集合中,以供全局调用,如下图:当执行eval时就会到system.js集合中查看有没有_id键为age的全局变量,如果找不到在看看age是不是一个已经定义了的局部变量,否则报错。

如果是定义成函数就类似于关系型数据库中的存储过程,如下图:
