spark之combineByKey函数源码
1.源码:
/**
* Simplified version of combineByKeyWithClassTag that hash-partitions the output RDD.
* This method is here for backward compatibility. It does not provide combiner
* classtag information to the shuffle.
*
* @see `combineByKeyWithClassTag`
*/
def combineByKey[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C,
numPartitions: Int): RDD[(K, C)] = self.withScope {
combineByKeyWithClassTag(createCombiner, mergeValue, mergeCombiners, numPartitions)(null)
}
调用combineByKeyWithClassTag
/**
* :: Experimental ::
* Generic function to combine the elements for each key using a custom set of aggregation
* functions. Turns an RDD[(K, V)] into a result of type RDD[(K, C)], for a "combined type" C
*
* Users provide three functions:
*
* - `createCombiner`, which turns a V into a C (e.g., creates a one-element list)
* - `mergeValue`, to merge a V into a C (e.g., adds it to the end of a list)
* - `mergeCombiners`, to combine two C's into a single one.
*
* In addition, users can control the partitioning of the output RDD, and whether to perform
* map-side aggregation (if a mapper can produce multiple items with the same key).
*
* @note V and C can be different -- for example, one might group an RDD of type
* (Int, Int) into an RDD of type (Int, Seq[Int]).
*/
@Experimental
def combineByKeyWithClassTag[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C,
partitioner: Partitioner,
mapSideCombine: Boolean = true,
serializer: Serializer = null)(implicit ct: ClassTag[C]): RDD[(K, C)] = self.withScope {
require(mergeCombiners != null, "mergeCombiners must be defined") // required as of Spark 0.9.0
if (keyClass.isArray) {
if (mapSideCombine) {
throw new SparkException("Cannot use map-side combining with array keys.")
}
if (partitioner.isInstanceOf[HashPartitioner]) {
throw new SparkException("HashPartitioner cannot partition array keys.")
}
}
val aggregator = new Aggregator[K, V, C](
self.context.clean(createCombiner),
self.context.clean(mergeValue),
self.context.clean(mergeCombiners))
if (self.partitioner == Some(partitioner)) {
self.mapPartitions(iter => {
val context = TaskContext.get()
new InterruptibleIterator(context, aggregator.combineValuesByKey(iter, context))
}, preservesPartitioning = true)
} else {
new ShuffledRDD[K, V, C](self, partitioner)
.setSerializer(serializer)
.setAggregator(aggregator)
.setMapSideCombine(mapSideCombine)
}
}
1.1跟踪aggregator
aggregator中的mergeValue和mergeCombiners类似于mapreduce中的map和reduce过程。
val aggregator = new Aggregator[K, V, C](
self.context.clean(createCombiner),
self.context.clean(mergeValue),
self.context.clean(mergeCombiners))
1.2 combineByKeyWithClassTag核心逻辑
其中最核心的代码逻辑:大概的意思是,RDD本身的partitioner和传入的partitioner相等时, 即不需要重新shuffle, 直接map即可,则在partitioner使用mapPartitions对每个元素使用combineValuesByKey,如果partition不相等,则new ShuffledRDD,也是使用mapSideCombine的方式先在每个partiton中聚合,然后再reduce聚合。
self.partitioner == Some(partitioner) :表示分区早就分好了,相同的key他已经在同一个partition中了,不需要shuffle。
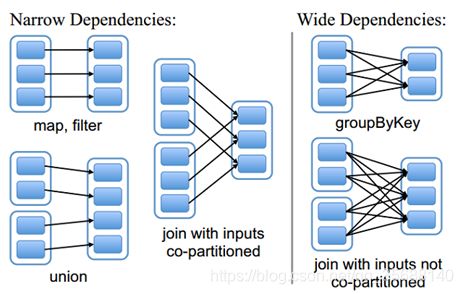
其实这里就是判断本次聚合是窄依赖还是宽依赖。
从图中可知:
窄依赖:是指每个父RDD的一个Partition最多被子RDD的一个Partition所使用,例如map、filter、union等操作都会产生窄依赖;(独生子女)
宽依赖:是指一个父RDD的Partition会被多个子RDD的Partition所使用,例如groupByKey、reduceByKey、sortByKey等操作都会产生宽依赖;(超生)
需要特别说明的是对join操作有两种情况:
(1)图中左半部分join:如果两个RDD在进行join操作时,一个RDD的partition仅仅和另一个RDD中已知个数的Partition进行join,那么这种类型的join操作就是窄依赖,例如图1中左半部分的join操作(join with inputs co-partitioned);
(2)图中右半部分join:其它情况的join操作就是宽依赖,例如图1中右半部分的join操作(join with inputs not co-partitioned),由于是需要父RDD的所有partition进行join的转换,这就涉及到了shuffle,因此这种类型的join操作也是宽依赖。
if (self.partitioner == Some(partitioner)) {
self.mapPartitions(iter => {
val context = TaskContext.get()
new InterruptibleIterator(context, aggregator.combineValuesByKey(iter, context))
}, preservesPartitioning = true)
} else {
new ShuffledRDD[K, V, C](self, partitioner)
.setSerializer(serializer)
.setAggregator(aggregator)
.setMapSideCombine(mapSideCombine)
}
2.通过案例分析
scala> rdd6.collect
res3: Array[(Int, String)] = Array((1,dog), (1,cat), (2,gnu), (2,salmon), (2,rabbit), (1,turkey), (2,wolf), (2,bear), (2,bee))
scala> rdd6.combineByKey(List(_),(x:List[String],y:String)=>x:+y,(a:List[String],b:List[String])=>a++b).collect
res6: Array[(Int, List[String])] = Array((1,List(turkey, dog, cat)), (2,List(salmon, rabbit, gnu, wolf, bear, bee)))
1.很明显数据的分区为:
partitioner1:(1,dog), (1,cat), (2,gnu)
partitioner2:(2,salmon), (2,rabbit), (1,turkey)
partitioner3:(2,wolf), (2,bear), (2,bee)
分区的方法:ParallelCollectionRDD中分区的源码
def positions(length: Long, numSlices: Int): Iterator[(Int, Int)] = { (0 until numSlices).iterator.map { i => val start = ((i * length) / numSlices).toInt val end = (((i + 1) * length) / numSlices).toInt (start, end) } }可以看出,计算分区直接是使用数据的长度除以分区的个数,平均将数据分给每个分区
2.第一步合并数据aggregator
partitioner1:(1,(dog,cat)), (2,gnu)
partitioner2:(2,(salmon,rabbit)), (1,turkey)
partitioner3:(2,(wolf,bear,bee))
3.调用List( _ ),对value中的第一元素使用List( _ )
partitioner1:(1,(List(dog),cat)), (2,List(gnu))
partitioner2:(2,(List(salmon),rabbit)), (1,List(turkey))
partitioner3:(2,(List(wolf),bear,bee))
4.调用(x:List[String],y:String)=>x:+y
partitioner1:(1,(List(dog,cat))), (2,List(gnu))
partitioner2:(2,(List(salmon,rabbit))), (1,List(turkey))
partitioner3:(2,(List(wolf,bear,bee)))
5.调用 (a:List[String],b:List[String])=>a++b
讲不同的partition之间的数据合并:(1,List(turkey, dog, cat)), (2,List(salmon, rabbit, gnu, wolf, bear, bee))