强联通分量及缩点法
概念
1.连通性:如果在图中存在一条路径将顶点u,v连接在了一起,则称u,v是连通的。
2.连通分量:无向图G的极大连通子图称为G的连通分量( Connected Component),就是再加入一个新点,这个新点不能与分量中所有点连通
3.强连通分量:有向图中, u可达v不一定意味着v可达u. 相互可达则属于同一个强连通分量(Strongly Connected Component)
4.连通图:如果图中所有顶点都是互相连通的,则称这个图是一个连通图
强连通分量及缩点法
我们可以将每个强连通分量看作一个内外隔绝的包裹,忽略包裹内部的冗余边,并将这个包裹同外部点的相连的边保留,将其打包压缩成一个新的点存储下来,这就是缩点法。

如图,s1,s2,s3就是图的三个强连通分量,可以把他们压缩成3个新点,压缩后的新点形成的一定是个有向无环图,如果新点成环的话就意味着环上的任意两点相互连通,意味着两个强连通分量中的点相互连通,则这两点同属于一个强连通分量,矛盾
所以缩点法形成的新图一定是有向无环图,这个性质有时对解决问题会有极大的帮助。
求连通分量的具体算法主要有三种,Kosaraju,Gabow和Tarjan算法,下面对这三种算法逐一进行介绍。
Tarjan算法
由于强连通分量中的点相互连通,所以如果用dfs遍历到这个分量时,一定会回溯到已经遍历过的同属于这个分量的点
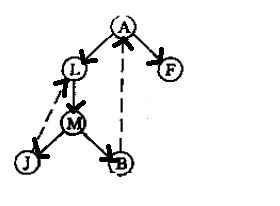
如图所示,图的一个强连通分量会在dfs时会形成以A为根节点的子树,我们只需要找出这个子树,并能够取出这个子树,也即利用Targan算法,Targan算法基于DFS和栈来实现,每次遍历到一个点时就把该点压栈。
首先建立两个数组DFN[] 和 LOW[], DFN[]用来记录点被遍历到的时候的时间,(会再定义一个全局变量做计时器),作用在于区分点,以及识别根,因为,当DFS走到强连通分量中的第一个点时,这个点的DFN[]一定是最小的,如图中的A。
LOW[]记录每个点能够回溯到的点的最小的DFN值,如B能够回溯到A,他的LOW实际就是A的DFN
LOW值一定小于DFN
一旦点的DFN不等于其LOW时,意味着他可以回溯到更早的点,所以这个点一定不是根节点。
当一个点的DFN==LOW时,这个点就是根,就将栈中该点及之上的所有点出栈,他们同属于一个强连通分量。
vector G[10010];
stack s;
int low[10010];
int dfn[10010];
int time = 0;
int scc[10010];
int sccnum = 0;
int visit[10010];
int numinscc[10010];
int outdegree[10010];
void Targan(int u)
{
low[u] = dfn[u] = ++time;
visit[u] = 1;
s.push(u);
for(int i=0;i 得到强连通分量之后可以遍历每条边,如果边的两顶点不在同一个强连通分量,则可以把这个缩点的出度加1
Gabow算法
Gabow算法的原理和Targan算法类似,只是Gabow算法将LOW数组用另一个栈代替,即用双栈实现算法
每次遍历到新点时,就把该点同时压入两个栈,因为强连通分量是由一个个环组成的,所以每当回溯到栈中的点导致成环时
就把栈2中该环内根节点以上的点弹出,只保留根节点,当从某点出发全部dfs完了之后,栈二的顶点就是该点,那么这个点就是强连通分量的根节点,这时栈1该点及以上的所有点就组成了强连通分量,即慢慢剥离强连通分量中的环达到定位根节点的目的
Gabow算法也利用了数组DFN来为节点编序。
vector G[10010];
stack s1;
stack s2;
//int low[10010];
int dfn[10010];
int time = 0;
int scc[10010];
int sccnum = 0;
int visit[10010];
int outdegree[10010];
int numinscc[10010];
void Gabow(int u)
{
visit[u] =1;
dfn[u] = ++time;
s1.push(u);
s2.push(u);
for(int i=0;idfn[v])
s2.pop();
}
}
if(s2.top() == u)
{
int m;
sccnum++;
do
{
m=s1.top();
s1.pop();
scc[m] = sccnum;
numinscc[sccnum]++;
}while(m!=u);
}
} Kosaraju算法
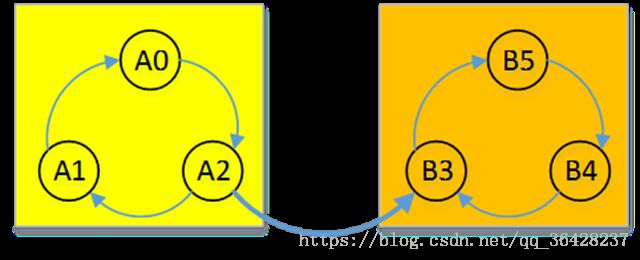
但是会发现,如果我们先遍历B中的顶点,则第一次DFS将遍历B3、B4、B5组成的强连通分量。第二次DFS将遍历A0、A1、A2
组成的强连通分量,这样我们就想到一个策略就是如果能得到一个顶点遍历的顺序,满足每次按顺序遍历一次DFS,就能遍历出一个强连通分量就好了,好的是这样的顺序是存在的
我们把原图反向,所有的边反向
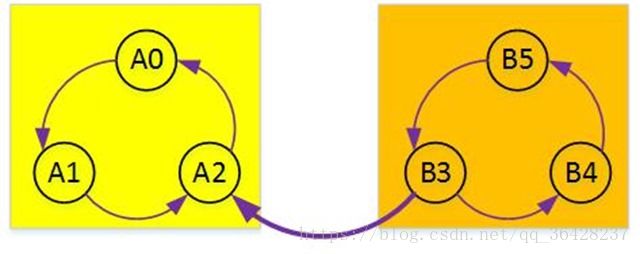
创建一个栈,在DFS,当顶点所有的边都被遍历完时,把这个顶点压入栈中
第一种情况,先遍历A0、A1、A2,则第一次DFS后,三点全部入栈,第二次DFS后B3、B4、B5入栈,满足B系列的点在A系列的点上面(在栈中)
第二种情况,先遍历B系列的点,因为压栈操作在所有的边被遍历完之后,所以当B系列的点要被压栈时,A系列的点已经遍历完了,所以B系列的点依然在A系列的点上面。这样从栈顶到栈顶的顶点形成的顺序就是我们要的序列。
按这个顺序DFS就得到了各强连通分量,这个方法对复杂情况也是成立的。即算法分为两步:
(1)对原图取反,从任意一个顶点开始对反向图进行逆后续DFS遍历
(2)按照逆后续遍历中栈中的顶点出栈顺序,对原图进行DFS遍历,一次DFS遍历中访问的所有顶点都属于同一强连通分量。
vectorG[maxn],G2[maxn];
vectorS;
int vis[maxn],sccno[maxn],scc_cnt;
void dfs1(int u)
{
if (vis[u]) return;
vis[u]=1;
for (int i=0;i=0;i--)
{
if (!sccno[S[i]])
{
scc_cnt++;
dfs2(S[i]);
}
}
}
例题:POJ2186

考虑这样一个例子,先求出图中的强连通分量,然后缩点成新图
则S3中的牛都是满足题意的受所有牛仰慕的牛,即缩点后的新图若只有一个出度为零的点,则这个点就是满足题意的点
该点内的所有牛都是满足题意的牛,若不止一个出度为0的点,则满足提议的牛为0
下面仅附上Targan算法程序
#include
#include
#include
#include
#include
#include
#include
using namespace std;
vector G[10010];
stack s;
int low[10010];
int dfn[10010];
int time = 0;
int scc[10010];
int sccnum = 0;
int visit[10010];
int numinscc[10010];
int outdegree[10010];
void Targan(int u)
{
low[u] = dfn[u] = ++time;
visit[u] = 1;
s.push(u);
for(int i=0;i>n>>m;
for(int i=1;i<=m;i++)
{
int u,v;
cin>>u>>v;
G[u].push_back(v);
}
for(int i=1;i<=n;i++)
{
if(scc[i]==0)
Targan(i);
}
for(int i =1;i<=n;i++)
{
for(int j=0;j