一、概述
本文主要是从deep learning for nlp课程的讲义中学习、总结google word2vector的原理和词向量的训练方法。文中提到的模型结构和word2vector的代码实现并不一致,但是可以非常直观的理解其原理,对于新手学习有一定的帮助。(首次在写技术博客,理解错误之处,欢迎指正)
二、词向量及其历史
1. 词向量定义
词向量顾名思义,就是用一个向量的形式表示一个词。为什么这么做?机器学习任务需要把任何输入量化成数值表示,然后通过充分利用计算机的计算能力,计算得出最终想要的结果。词向量的一种表示方式是one-hot的表示形式:
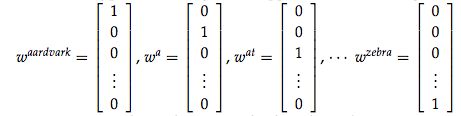
首先,统计出语料中的所有词汇,然后对每个词汇编号,针对每个词建立V维的向量,向量的每个维度表示一个词,所以,对应编号位置上的维度数值为1,其他维度全为0。这种方式存在问题并且引发新的质疑:
1)无法衡量相关词之间的距离
从语义上讲,hotel 和motel 更相关,和cat更不相关,但是无法表示这种差异。
2)V维表示语义空间是否有必要
one-hot的每一维度表示具体的词,我们假设存在更加抽象的维度能够表示词和词之间的相似性和差异性,并且词向量的维度远远小于V。例如,这些维度可以是时态,单复数等
2.词向量获取方法
1)基于奇异值分解的方法(奇异值分解)
a、单词-文档矩阵
基于的假设:相关词往往出现在同一文档中,例如,banks 和 bonds, stocks,money 更相关且常出现在一篇文档中,而 banks 和 octous, banana, hockey 不太可能同时出现在一起。因此,可以建立词和文档的矩阵,通过对此矩阵做奇异值分解,可以获取词的向量表示。
b、单词-单词矩阵
基于的假设:一个词的含义由上下文信息决定,那么两个词之间的上下文相似,是否可推测二者非常相似。设定上下文窗口,统计建立词和词之间的共现矩阵,通过对矩阵做奇异值分解获得词向量。
2)基于迭代的方法
目前基于迭代的方法获取词向量大多是基于语言模型的训练得到的,对于一个合理的句子,希望语言模型能够给予一个较大的概率,同理,对于一个不合理的句子,给予较小的概率评估。具体的形式化表示如下:


第一个公式:一元语言模型,假设当前词的概率只和自己有关;第二个公式:二元语言模型,假设当前词的概率和前一个词有关。那么问题来了,如何从语料库中学习给定上下文预测当前词的概率值呢?
a、Continuous Bag of Words Model(CBOW)
给定上下文预测目标词的概率分布,例如,给定{The,cat,(),over,the,puddle}预测中心词是jumped的概率,模型的结构如下:
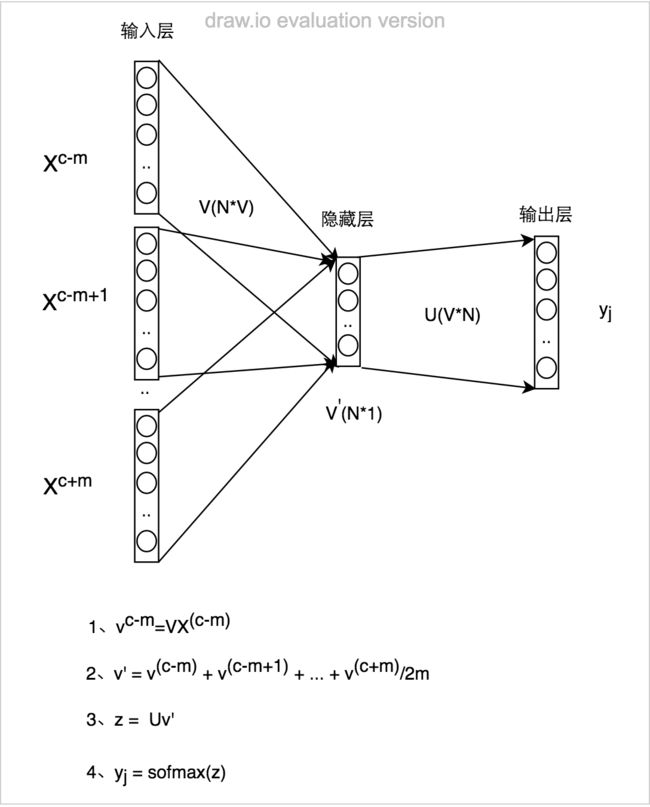
如何训练该模型呢?首先定义目标函数,随后通过梯度下降法,优化此神经网络。目标函数可以采用交叉熵函数:

由于yj是one-hot的表示方式,只有当yj=i 时,目标函数才不为0,因此,目标函数变为:
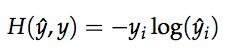
代入预测值的计算公式,目标函数可转化为:
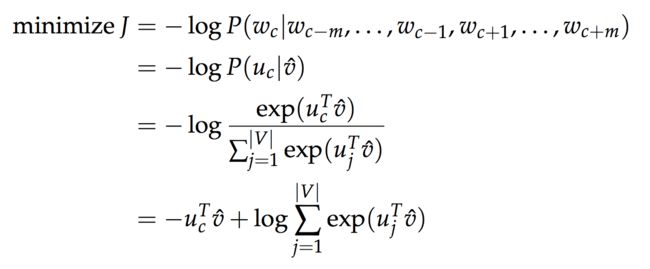
b、Skip-Gram Model
skip-gram模型是给定目标词预测上下文的概率值,模型的结构如下:
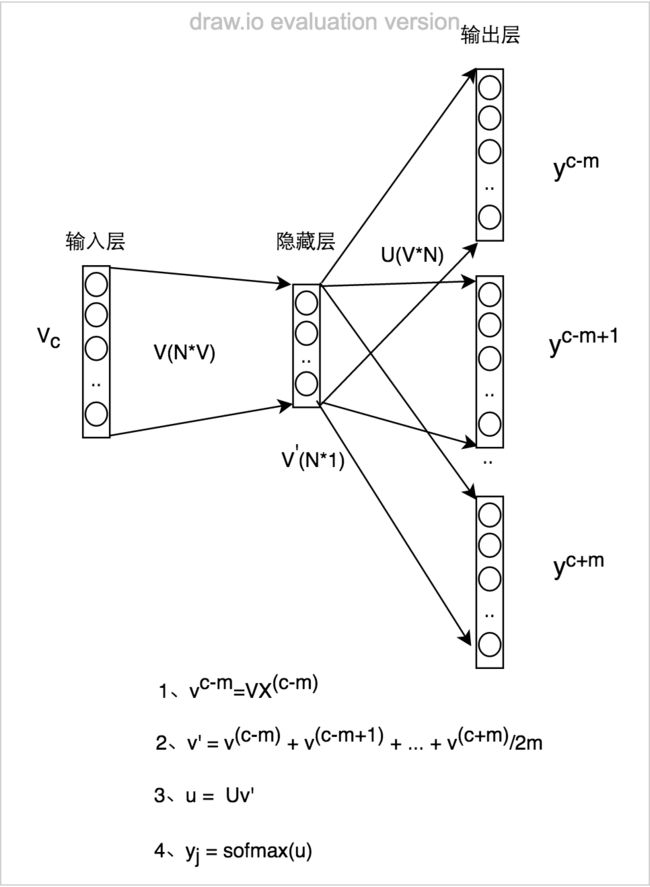
同理,对于skip-ngram模型也需要设定一个目标函数,随后采用优化方法找到该model的最佳参数解,目标函数如下:

分析上述model发现,预概率时的softmax操作,需要计算隐藏层和输出层所有V中单词之间的概率,这是一个非常耗时的操作,因此,为了优化模型的训练,minkov文中提到Hierarchical softmax 和 Negative sampling 两种方法对上述模型进行训练,具体详细的推导可以参考文献1和文献2。
三、参考文献
1.word2vec Explained: Deriving Mikolov et al.’s Negative-Sampling Word-Embedding Method
2.word2vec Parameter Learning Explained
3.Deep learning for nlp Lecture Notes 1
4.Neural Word Embedding as Implicit Matrix Factorization(证明上述model本质是矩阵分解)
5.Improving Distributional Similarity with Lessons Learned from Word Embeddings(实际应用中如何获得更好的词向量)
6.Hierarchical Softmax in neural network language model
7.word2vec 中的数学原理详解(四)基于 Hierarchical Softmax 的模型
8.Softmax回归
9.霍夫曼编码