- Golang channel 死锁
羊城程序猿
golanggolang
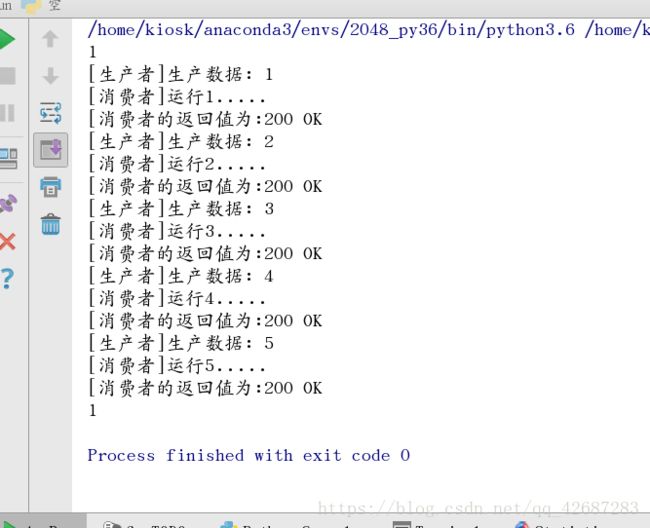
死锁是指两个或两个以上的协程的执行过程中,由于竞争资源或由于彼此通信而造成的一种阻塞的现象,若无外力作用,他们将无法推进下去,以下是总结出来的几种死锁情况。1.死锁1:一个通道在一个主go程里同时进行读和写2.死锁2:go程开启之前使用通道3.死锁3:通道1中调用了通道2,通道2中调用通道14.死锁4:直接读取空channel的死锁5.死锁5:超过channel缓存继续写入数据导致死锁6.向已关闭
- golang学习笔记--MPG模型
xxzed
golang#学习笔记学习笔记golang
MPG模式:M(Machine):操作系统的主线程P(Processor):协程执行需要的资源(上下文context),可以看作一个局部的调度器,使go代码在一个线程上跑,他是实现从N:1到N:M映射的关键G(Goroutine):协程,有自己的栈。包含指令指针(instructionpointer)和其它信息(正在等待的channel等等),用于调度。一个P下面可以有多个G1、当前程序有三个M,
- [Golang] goroutine
沉着冷静2024
Golanggolang后端
[Golang]goroutine文章目录[Golang]goroutine并发进程和线程协程goroutine概述如何使用goroutine并发进程和线程谈到并发,大多都离不开进程和线程,什么是进程、什么是线程?进程可以这样理解:进程就是运行着的程序,它是程序在操作系统的一次执行过程,是一个程序的动态概念,进程是操作系统分配资源的基本单位。线程可以这样理解:线程是一个进程的执行实体,它是比进程粒
- Python笔记6----数组
weixin_34293911
python数据结构与算法c/c++
1、Python中的数组形式:用list和tuple等数据结构表示数组一维数组:list=[1,2,3,4]二维数组:list=[[1,2,3],[4,5,6],[7,8,9]]用array模块:array模块需要加载,而且运用的较少通过array函数创建数组(数组中的元素可以不是同一种类型),array.array('B',range(5))>>array('B',[1,2,3,4,5])提供a
- golang中创建协程以及协程间的相互通信
忍界英雄
golang开发语言
golang中创建协程以及协程间的相互通信。在golang中创建协程在Go语言中,使用协程来实现并发模型。协程是Go语言的并发执行单元,它比传统的线程更轻量级,允许我们并发执行多个任务。Go会在内部使用一组线程来运行创建的协程,并在这些线程之间高效地分配协程执行,这样可以在不增加太多操作系统线程的情况下执行大量的协程。在golang中,我们可以方便的使用gofunc(){}()语句用于启动一个新的
- 【代码随想录python笔记整理】第一课 · A+B 问题1
南星六月雪
Python刷题笔记笔记python
前言:本笔记仅仅只是对内容的整理和自行消化,并不是完整内容,如有侵权,联系立删。一、数据类型Python中有一些常见数据类型,包括数字类型,布尔类型,字符串类型。其中,数字类型又分为整数类型和浮点数类型。整数类型-1、0、1浮点数类型3.14布尔类型True=1;False=0字符串类型'Hello'、"Helllo"二、输入输出1、输入:输入采用input()函数,再将变量与其建立联系。在inp
- golang学习笔记14——golang性能问题的处理方法
GoppViper
golang学习笔记golang学习笔记编程语言golang性能性能优化后端
推荐学习文档基于golang开发的一款超有个性的旅游计划app经历golang实战大纲golang优秀开发常用开源库汇总golang学习笔记01——基本数据类型golang学习笔记02——gin框架及基本原理golang学习笔记03——gin框架的核心数据结构golang学习笔记04——如何真正写好Golang代码?golang学习笔记05——golang协程池,怎么实现协程池?golang学习笔
- python并发与并行(十一) ———— 让asyncio的事件循环保持畅通,以便进一步提升程序的响应能力
bug404_
python并发与并行python开发语言
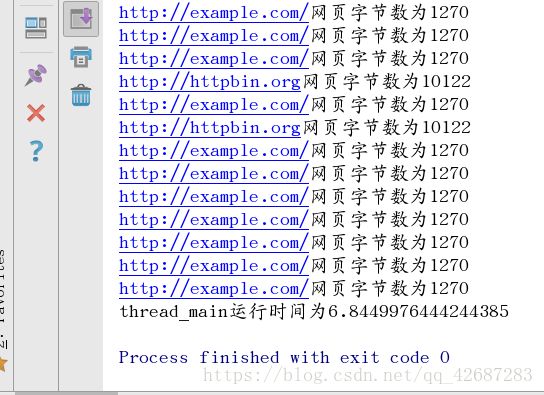
前一篇blog说明了怎样把采用线程所实现的项目逐步迁移到asyncio方案上面。迁移后的run_tasks协程,可以将多份输入文件通过tail_async协程正确地合并成一份输出文件。importasyncio#OnWindows,aProactorEventLoopcan'tbecreatedwithin#threadsbecauseittriestoregistersignalhandlers
- Unity协程搭配队列开发Tips弹窗模块
傻Q爱
Unity技术unityjava游戏引擎
概述在Unity游戏开发过程中,提示系统是提升用户体验的重要组成部分。一个设计良好的提示窗口不仅能及时传达信息给玩家,还应当做到不干扰游戏流程。本文将探讨如何使用Unity的协程(Coroutine)配合队列(Queue)数据结构来构建一个高效且可扩展的Tips弹窗模块。技术模块介绍1.Unity协程(Coroutines)协程是Unity中的一种特殊函数类型,允许异步操作的实现。它能够在执行过程
- Python异步编程入门
旖风刈草
Pythonpython开发语言个人开发
一、何为异步?说起异步模型,不得不提老生常谈的同步模型,此二者是相对的概念。同步模型即程序必须按照顺序依次执行,当程序在执行一个需要等待外部资源的操作时(网络数据收发、文件读写),会陷入阻塞状态,只有在外部资源到位后才会继续执行。与之相反,异步模型具有非阻塞的特点,程序在等待外部资源时,会继续执行其他代码。在3.4版本中,Python引入了对异步编程的支持,在同一个线程下通过事件循环对多个协程进行
- golang线程池ants-四种使用方法
liupenglove
golang后端多线程
目录1、ants介绍2、使用方式汇总3、各种使用方式详解3.1默认池3.2普通模式3.3带参函数3.4多池多协程4、总结1、ants介绍众所周知,goroutine相比于线程来说,更加轻量、资源占用更少、无线程上下文切换等优势,但是也不能无节制的创建使用,如果系统中开启的goroutine过多而没有及时回收,也会造成系统内存资源耗尽。ants是一款高性能的协程管理池,实现了协程的创建、缓存、复用、
- android plaid,Plaid 开源库学习
AI沃浪讯
androidplaid
Plaid库是google之前的一个demo库,近期利用kotlin进行了重写.某种程度上,是Kotlin和Jetpack的一个实践。以下内容从三个方面来说:Plaid项目划分Plaid的代码结构Plaid的代码实现-coroutines协程实现1.Plaid项目划分Plaid模块化结构图:plaid代码结构模块化图属于多模块化的设计,core是继承模块,其他模块是业务模块。2.Plaid每个模块
- 【Python笔记】向量:@classmethod与 @staticmethod。零基础
万物皆可.C
Python笔记python
类成员比较@classmethod与@staticmethod共同点:两个都是装饰器,装饰的成员函数可以通过类名.方法名(…)来调用区别:最显著的特点是classmethod需要传递一个参数cls,而staticmethod不需要。因此可以访问、修改类的属性,类的方法,实例化对象等,避免硬编码;而staticmethod不行,classmethod可以判断出自己是通过基类被调用,还是通过某个子类被
- python学习笔记08_赋值运算、逻辑运算、表达式、短路原则
flamingocc
python笔记081.赋值运算符num+=1等价于num=num+1num-=1等价于num=num-1num*=1等价于num=num*1num/=1等价于num=num/1num//2等价于num=num//2num%=2等价于num/2的余数num**2等价于num=num*num2.逻辑运算符逻辑运算符包含:not、and、or2.1and的用法:(且、并且)写法:条件1and条件2eg
- Python实现多线程、多进程及协程
闲人编程
pythonpython开发语言多线程多进程协程并发异步
目录Python实现多线程、多进程及协程引言1.多线程(Threading)1.1多线程的基本概念1.2多线程的优点和缺点1.3Python多线程的实现2.多进程(Multiprocessing)2.1多进程的基本概念2.2多进程的优点和缺点2.3Python多进程的实现3.协程(Coroutine)3.1协程的基本概念3.2协程的优点和缺点3.3Python协程的实现4.三种并发模型的对比与选择
- 浅谈Unity协程的工作机制
王维志
unitywindows游戏引擎
一.什么是协程协程概述在Unity中,协程(Coroutine)是一种非常常用的机制,用于非阻塞地处理需要跨越多个帧、等待某些条件或延迟一段时间才能完成的任务。Unity的协程通过C#的IEnumerator和yieldreturn实现,使得你可以在游戏主线程中以一种简洁的方式执行异步操作,而不需要使用复杂的多线程或回调。协程允许你暂停代码的执行,并在稍后的某个时间点恢复执行。适合处理游一些常见需
- Unity实现自己的协程系统
王维志
unity游戏引擎
概述:自定义Unity协程调度器(不依赖Mono)实现了一个协程调度器,允许在程序中以非阻塞的方式调度协程。协程可以在满足特定条件后暂停和恢复,如等待特定的帧数、时间、或等待其他协程执行完毕。它的设计思想与Unity的协程机制类似,但它不依赖Unity的YieldInstruction,因此适用于非Unity环境。协程可以在以下情况下暂停:"yieldnull;"等一帧;"yield一个int值"
- Python 异步编程介绍与代码示例
大霸王龙
python网络服务器异步编程
Python异步编程介绍与代码示例一、异步编程概述异步编程是一种编程范式,它旨在处理那些需要等待I/O操作完成或执行耗时任务的情况。在传统的同步编程中,代码会按照顺序逐行执行,直到遇到一个耗时操作,它会阻塞程序的执行直到该操作完成。这种阻塞式的模型在某些场景下效率低下,因为代码在等待操作完成时无法执行其他任务。异步编程通过非阻塞I/O和协程(coroutine)来提高效率,使得程序在等待某些操作时
- Python异步编程_asyncio
代码输入中...
python开发语言深度学习numpy
1.协程协程不是计算机提供的,它是程序员创造的。协程-Co_routine,也可以称之为微线程,是一种用户态内的上下文切换技术,简而言之,其实就是通过一个线程实现代码块相互切换执行。实现协程的几种方法:greenlet,早期模块yield关键字asyncio装饰器(python3.4及其之后)async、await关键字(python3.5及其之后)【推荐】1.1greenlet实现协程pip3i
- Python 协程 & 异步编程 (asyncio) 入门介绍
linmeiyun
后端pythonpython爬虫学习开发语言机器学习
在近期的编码工作过程中遇到了async和await装饰的函数,查询资料后了解到这种函数是基于协程的异步函数。这类编程方式称为异步编程,常用在IO较频繁的系统中,如:Tornadoweb框架、文件下载、网络爬虫等应用。协程能够在IO等待时间就去切换执行其他任务,当IO操作结束后再自动回调,那么就会大大节省资源并提供性能。接下来便简单的讲解一下异步编程相关概念以及案例演示。1.协程简介1.1协程的含义
- Kotlin 协程使用手册,2024年最新面试官没礼貌
2401_84167109
程序员kotlin开发语言android
协程的定义其实不太好描述,那我干脆由用途及定义,简述一下协程。轻量级的线程标题的说法可能不太准确,但也能一窥其功用。协程是工作在线程之上的。我们知道线程是由系统(语言系统或者操作系统)进行调度的,切换时有着一定的开销。而协程,它的切换由程序自己来控制,无论是CPU的消耗还是内存的消耗都大大降低。从这一点出发,它的应用场景可能就在于提高硬件性能的瓶颈。譬如说,你启动十万个协程不会有什么问题,但你启动
- Unity协程和C#迭代器的关系
qq_39260270
unityunityc#游戏引擎
从本质上来说Unity中的协程就是利用了C#中迭代器的特性IEnumeratorIEnumerator定义了一个适用于任何集合的迭代方式。也就是说只要一个集合实现了IEnumerator,那么就可以通过IEnumerator迭代其中的元素。IEnumerator的定义如下:publicinterfaceIEnumerator{objectCurrent{get;}boolMoveNext();vo
- Kotlin 枚举类
wjs2024
开发语言
Kotlin枚举类概述Kotlin是一种现代的编程语言,由JetBrains开发,旨在提高开发者的工作效率和代码质量。它运行在Java虚拟机(JVM)上,与Java完全兼容,同时提供了许多现代语言特性,如空安全、扩展函数和协程等。Kotlin的设计哲学是简洁和表达性,这使得它成为Android开发的官方语言,并在后端开发中也越来越受欢迎。Kotlin枚举类简介枚举类是Kotlin中的一种特殊类,用
- python(二)基础之async与await
阿无,
python
什么是协程、异步举个例子:假设有1个洗衣房,里面有10台洗衣机,有一个洗衣工在负责这10台洗衣机。那么洗衣房就相当于1个进程,洗衣工就相当1个线程。如果有10个洗衣工,就相当于10个线程,1个进程是可以开多线程的。这就是多线程!那么协程呢?先不急。大家都知道,洗衣机洗衣服是需要等待时间的,如果10个洗衣工,1人负责1台洗衣机,这样效率肯定会提高,但是不觉得浪费资源吗?明明1个人能做的事,却要10个
- Android中的线程(一)
川峰
Android知识笔记android多线程线程安全线程池线程通信
本文主要是对Android当中的线程相关的知识进行复习和总结。文章目录newThreadAsyncTaskHandlerThreadIntentServiceJobIntentServiceJobSchedulerWorkManager线程中断守护线程线程优先级线程状态线程池线程安全线程通信kotlin协程newThread缺乏统一管理,无限制创建,可能占用过多系统资源导致死机或oom,不推荐。A
- golang学习笔记06——怎么实现本地文件及目录监控-fsnotify
GoppViper
golang学习笔记golang开发语言后端文件操作
推荐学习文档基于golang开发的一款超有个性的旅游计划app经历golang实战大纲golang优秀开发常用开源库汇总golang学习笔记01——基本数据类型golang学习笔记02——gin框架及基本原理golang学习笔记03——gin框架的核心数据结构golang学习笔记04——如何真正写好Golang代码?golang学习笔记05——golang协程池,怎么实现协程池?背景我们总有这样的
- AttributeError: module ‘asyncio‘ has no attribute ‘run‘ 或者是 “create_task”
小二丶上酒
Python
asyncio异步协程写法在python3.7之前asyncdeff1(num):print("f1start")awaitasyncio.sleep(num)print("f1end")asyncdeff2(num):print("f3start")awaitasyncio.sleep(num)print("f3end")asyncdeff3(num):print("f3start")await
- Python. 协程asyncio、gevent
u010373106
pythonpython开发语言
1、协程是一种轻量级的并发机制,允许你在单个线程内模拟并发执行多个任务。协程非常适合用于I/O密集型任务,如网络请求、文件读写等,在等待I/O操作完成时,协程可以继续执行其他任务而不是阻塞。生成器:协程的基础是生成器(generator)。生成器是一种特殊的迭代器,它可以使用yield表达式暂停其执行,并在后续调用next()方法时恢复执行。生成器可以使用yield表达式返回一个值,并保存当前的状
- python 异步编程
Anuttarasamyasambodh
python服务器linux
Python的异步编程主要通过以下几种方式实现:使用生成器(Generators)和协程(Coroutines):Python的生成器和协程可以用来实现异步编程。生成器可以暂停执行并在需要时恢复执行,而协程则可以用来实现更复杂的异步行为。asyncio库:Python3.4版本引入了asyncio库,该库提供了一种方便的方法来编写异步代码。使用asyncio库,可以将异步操作定义为协程,然后使用a
- 如何通过Docker搭建一个swoft开发环境
八重樱。
Dockerswooleswoftphp
本篇文章给大家分享的内容是关于如何通过Docker搭建一个swoft开发环境,内容很详细,有需要的朋友可以参考一下,希望可以帮助到你们。Swoft首个基于Swoole原生协程的新时代PHP高性能协程全栈组件化框架,内置协程网络服务器及常用的协程客户端,常驻内存,不依赖传统的PHP-FPM,全异步非阻塞IO实现,以类似于同步客户端的写法实现异步客户端的使用,没有复杂的异步回调,没有繁琐的yield,
- mondb入手
木zi_鸣
mongodb
windows 启动mongodb 编写bat文件,
mongod --dbpath D:\software\MongoDBDATA
mongod --help 查询各种配置
配置在mongob
打开批处理,即可启动,27017原生端口,shell操作监控端口 扩展28017,web端操作端口
启动配置文件配置,
数据更灵活
- 大型高并发高负载网站的系统架构
bijian1013
高并发负载均衡
扩展Web应用程序
一.概念
简单的来说,如果一个系统可扩展,那么你可以通过扩展来提供系统的性能。这代表着系统能够容纳更高的负载、更大的数据集,并且系统是可维护的。扩展和语言、某项具体的技术都是无关的。扩展可以分为两种:
1.
- DISPLAY变量和xhost(原创)
czmmiao
display
DISPLAY
在Linux/Unix类操作系统上, DISPLAY用来设置将图形显示到何处. 直接登陆图形界面或者登陆命令行界面后使用startx启动图形, DISPLAY环境变量将自动设置为:0:0, 此时可以打开终端, 输出图形程序的名称(比如xclock)来启动程序, 图形将显示在本地窗口上, 在终端上输入printenv查看当前环境变量, 输出结果中有如下内容:DISPLAY=:0.0
- 获取B/S客户端IP
周凡杨
java编程jspWeb浏览器
最近想写个B/S架构的聊天系统,因为以前做过C/S架构的QQ聊天系统,所以对于Socket通信编程只是一个巩固。对于C/S架构的聊天系统,由于存在客户端Java应用,所以直接在代码中获取客户端的IP,应用的方法为:
String ip = InetAddress.getLocalHost().getHostAddress();
然而对于WEB
- 浅谈类和对象
朱辉辉33
编程
类是对一类事物的总称,对象是描述一个物体的特征,类是对象的抽象。简单来说,类是抽象的,不占用内存,对象是具体的,
占用存储空间。
类是由属性和方法构成的,基本格式是public class 类名{
//定义属性
private/public 数据类型 属性名;
//定义方法
publ
- android activity与viewpager+fragment的生命周期问题
肆无忌惮_
viewpager
有一个Activity里面是ViewPager,ViewPager里面放了两个Fragment。
第一次进入这个Activity。开启了服务,并在onResume方法中绑定服务后,对Service进行了一定的初始化,其中调用了Fragment中的一个属性。
super.onResume();
bindService(intent, conn, BIND_AUTO_CREATE);
- base64Encode对图片进行编码
843977358
base64图片encoder
/**
* 对图片进行base64encoder编码
*
* @author mrZhang
* @param path
* @return
*/
public static String encodeImage(String path) {
BASE64Encoder encoder = null;
byte[] b = null;
I
- Request Header简介
aigo
servlet
当一个客户端(通常是浏览器)向Web服务器发送一个请求是,它要发送一个请求的命令行,一般是GET或POST命令,当发送POST命令时,它还必须向服务器发送一个叫“Content-Length”的请求头(Request Header) 用以指明请求数据的长度,除了Content-Length之外,它还可以向服务器发送其它一些Headers,如:
- HttpClient4.3 创建SSL协议的HttpClient对象
alleni123
httpclient爬虫ssl
public class HttpClientUtils
{
public static CloseableHttpClient createSSLClientDefault(CookieStore cookies){
SSLContext sslContext=null;
try
{
sslContext=new SSLContextBuilder().l
- java取反 -右移-左移-无符号右移的探讨
百合不是茶
位运算符 位移
取反:
在二进制中第一位,1表示符数,0表示正数
byte a = -1;
原码:10000001
反码:11111110
补码:11111111
//异或: 00000000
byte b = -2;
原码:10000010
反码:11111101
补码:11111110
//异或: 00000001
- java多线程join的作用与用法
bijian1013
java多线程
对于JAVA的join,JDK 是这样说的:join public final void join (long millis )throws InterruptedException Waits at most millis milliseconds for this thread to die. A timeout of 0 means t
- Java发送http请求(get 与post方法请求)
bijian1013
javaspring
PostRequest.java
package com.bijian.study;
import java.io.BufferedReader;
import java.io.DataOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURL
- 【Struts2二】struts.xml中package下的action配置项默认值
bit1129
struts.xml
在第一部份,定义了struts.xml文件,如下所示:
<!DOCTYPE struts PUBLIC
"-//Apache Software Foundation//DTD Struts Configuration 2.3//EN"
"http://struts.apache.org/dtds/struts
- 【Kafka十三】Kafka Simple Consumer
bit1129
simple
代码中关于Host和Port是割裂开的,这会导致单机环境下的伪分布式Kafka集群环境下,这个例子没法运行。
实际情况是需要将host和port绑定到一起,
package kafka.examples.lowlevel;
import kafka.api.FetchRequest;
import kafka.api.FetchRequestBuilder;
impo
- nodejs学习api
ronin47
nodejs api
NodeJS基础 什么是NodeJS
JS是脚本语言,脚本语言都需要一个解析器才能运行。对于写在HTML页面里的JS,浏览器充当了解析器的角色。而对于需要独立运行的JS,NodeJS就是一个解析器。
每一种解析器都是一个运行环境,不但允许JS定义各种数据结构,进行各种计算,还允许JS使用运行环境提供的内置对象和方法做一些事情。例如运行在浏览器中的JS的用途是操作DOM,浏览器就提供了docum
- java-64.寻找第N个丑数
bylijinnan
java
public class UglyNumber {
/**
* 64.查找第N个丑数
具体思路可参考 [url] http://zhedahht.blog.163.com/blog/static/2541117420094245366965/[/url]
*
题目:我们把只包含因子
2、3和5的数称作丑数(Ugly Number)。例如6、8都是丑数,但14
- 二维数组(矩阵)对角线输出
bylijinnan
二维数组
/**
二维数组 对角线输出 两个方向
例如对于数组:
{ 1, 2, 3, 4 },
{ 5, 6, 7, 8 },
{ 9, 10, 11, 12 },
{ 13, 14, 15, 16 },
slash方向输出:
1
5 2
9 6 3
13 10 7 4
14 11 8
15 12
16
backslash输出:
4
3
- [JWFD开源工作流设计]工作流跳跃模式开发关键点(今日更新)
comsci
工作流
既然是做开源软件的,我们的宗旨就是给大家分享设计和代码,那么现在我就用很简单扼要的语言来透露这个跳跃模式的设计原理
大家如果用过JWFD的ARC-自动运行控制器,或者看过代码,应该知道在ARC算法模块中有一个函数叫做SAN(),这个函数就是ARC的核心控制器,要实现跳跃模式,在SAN函数中一定要对LN链表数据结构进行操作,首先写一段代码,把
- redis常见使用
cuityang
redis常见使用
redis 通常被认为是一个数据结构服务器,主要是因为其有着丰富的数据结构 strings、map、 list、sets、 sorted sets
引入jar包 jedis-2.1.0.jar (本文下方提供下载)
package redistest;
import redis.clients.jedis.Jedis;
public class Listtest
- 配置多个redis
dalan_123
redis
配置多个redis客户端
<?xml version="1.0" encoding="UTF-8"?><beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi=&quo
- attrib命令
dcj3sjt126com
attr
attrib指令用于修改文件的属性.文件的常见属性有:只读.存档.隐藏和系统.
只读属性是指文件只可以做读的操作.不能对文件进行写的操作.就是文件的写保护.
存档属性是用来标记文件改动的.即在上一次备份后文件有所改动.一些备份软件在备份的时候会只去备份带有存档属性的文件.
- Yii使用公共函数
dcj3sjt126com
yii
在网站项目中,没必要把公用的函数写成一个工具类,有时候面向过程其实更方便。 在入口文件index.php里添加 require_once('protected/function.php'); 即可对其引用,成为公用的函数集合。 function.php如下:
<?php /** * This is the shortcut to D
- linux 系统资源的查看(free、uname、uptime、netstat)
eksliang
netstatlinux unamelinux uptimelinux free
linux 系统资源的查看
转载请出自出处:http://eksliang.iteye.com/blog/2167081
http://eksliang.iteye.com 一、free查看内存的使用情况
语法如下:
free [-b][-k][-m][-g] [-t]
参数含义
-b:直接输入free时,显示的单位是kb我们可以使用b(bytes),m
- JAVA的位操作符
greemranqq
位运算JAVA位移<<>>>
最近几种进制,加上各种位操作符,发现都比较模糊,不能完全掌握,这里就再熟悉熟悉。
1.按位操作符 :
按位操作符是用来操作基本数据类型中的单个bit,即二进制位,会对两个参数执行布尔代数运算,获得结果。
与(&)运算:
1&1 = 1, 1&0 = 0, 0&0 &
- Web前段学习网站
ihuning
Web
Web前段学习网站
菜鸟学习:http://www.w3cschool.cc/
JQuery中文网:http://www.jquerycn.cn/
内存溢出:http://outofmemory.cn/#csdn.blog
http://www.icoolxue.com/
http://www.jikexue
- 强强联合:FluxBB 作者加盟 Flarum
justjavac
r
原文:FluxBB Joins Forces With Flarum作者:Toby Zerner译文:强强联合:FluxBB 作者加盟 Flarum译者:justjavac
FluxBB 是一个快速、轻量级论坛软件,它的开发者是一名德国的 PHP 天才 Franz Liedke。FluxBB 的下一个版本(2.0)将被完全重写,并已经开发了一段时间。FluxBB 看起来非常有前途的,
- java统计在线人数(session存储信息的)
macroli
javaWeb
这篇日志是我写的第三次了 前两次都发布失败!郁闷极了!
由于在web开发中常常用到这一部分所以在此记录一下,呵呵,就到备忘录了!
我对于登录信息时使用session存储的,所以我这里是通过实现HttpSessionAttributeListener这个接口完成的。
1、实现接口类,在web.xml文件中配置监听类,从而可以使该类完成其工作。
public class Ses
- bootstrp carousel初体验 快速构建图片播放
qiaolevip
每天进步一点点学习永无止境bootstrap纵观千象
img{
border: 1px solid white;
box-shadow: 2px 2px 12px #333;
_width: expression(this.width > 600 ? "600px" : this.width + "px");
_height: expression(this.width &
- SparkSQL读取HBase数据,通过自定义外部数据源
superlxw1234
sparksparksqlsparksql读取hbasesparksql外部数据源
关键字:SparkSQL读取HBase、SparkSQL自定义外部数据源
前面文章介绍了SparSQL通过Hive操作HBase表。
SparkSQL从1.2开始支持自定义外部数据源(External DataSource),这样就可以通过API接口来实现自己的外部数据源。这里基于Spark1.4.0,简单介绍SparkSQL自定义外部数据源,访
- Spring Boot 1.3.0.M1发布
wiselyman
spring boot
Spring Boot 1.3.0.M1于6.12日发布,现在可以从Spring milestone repository下载。这个版本是基于Spring Framework 4.2.0.RC1,并在Spring Boot 1.2之上提供了大量的新特性improvements and new features。主要包含以下:
1.提供一个新的sprin