Scaling Memcache at Facebook 阅读笔记
这篇笔记是对于https://www.usenix.org/system/files/conference/nsdi13/nsdi13-final170_update.pdf
这篇文档的阅读记录,文中按照“延迟和负载” “区域内机制” “区域间机制”等三个方面对于Facebook的缓存系统进行了一个介绍,但是内容的排布让人难以一下理解其系统的原本面貌,在此做读书笔记,按照自己的理解对于文中的内容和机制进行整理,以期一览其大概
总览
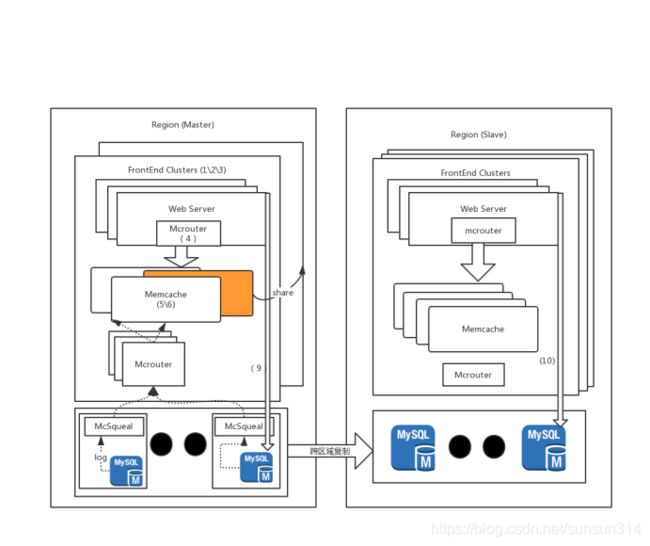
上图是我在读了文章之后对于整个缓存系统的理解,其中每个标号为后续会讨论到的步骤:
- FaceBook的基本架构,Front-End集群
- 在同一个Region中的数据分布
- 在web server数据存取的具体操作
- mcrouter的工作模式
- Memcache pool是如何组织的,怎么分
- 处理在缓存查询期间发生的错误的问题
- region之间的memcached server share的作用
- 冷集群启动的热集群依附
- 读写本地DB的时候是如何使得缓存值更新或者失效的
- 按照区域划分的时候写的是从库怎么办 remote marker机制的作用
FaceBook web系统的基本架构
首先在第一个部分描述一个场景前提,FaceBook这个项目其实和微博或者是朋友圈的项目有非常大的类似之处,就是读请求远远大于产生的写请求,并且写请求的生效实时性并不是要求很高,即使发布一个心情或者消息在几秒之后才能生效也是一个在容忍范围内的故事。
作为FaceBook这么打体量的一个全球性提供服务的公司来说,必然会在世界各地都部署足够的服务,以便于用户就近访问数据,所以整个项目的架构基础就是按照区域进行部署web server
在按照区域进行web server部署的这么一个大前提下,为了能够让web server提供足够快的服务,自然而然缓存和DB数据也都是要跟着web server进行全球部署,所以在整个FaceBook声称的区域Region中包含以下三个基本内容:
- Web server (web 服务)
- Memche (缓存服务)
- DB (数据库服务)
其中,一部分的web server和一部分的memche则组成一个可能以数据中心也可能是机房为单位的这么一个Front-End Cluster面向用户提供服务,而多个同一区域的Front-END cluster访问同一组的DB存储集群服务
Region中的数据分布
在图中可以看到,数据被存储在多个DB中,并且有多个memche进行缓存,所以其中的数据必然是按照一定的规则进行了分布式的存储,不然每个一个服务能够单独承载这个级别的数据。
而其数据分布存储的规则则是由提供给web server使用的client依赖mcrouter,在client中提供数据分片,请求合并,容错超时控制等等功能
但是,由于缓存数据往往存在热点的问题,并且存在一部分冷数据的问题,所以在缓存中,其数据并非像传统的分库分表那样。在缓存中部分热数据为了降低负载,会将负载分发到更多机器上,而部分冷数据可能由于数据使用量过小,可以让多个同一Region内的Front-Cluster来分享同一个memche server
Web server的数据存取方式
基础对于web server的大概缓存使用方式和其他地方的并无差别,基础逻辑如下图所示
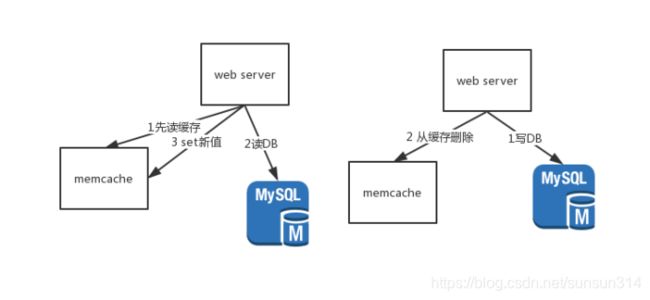
读请求:
- 优先读缓存
- 缓存无数据则读DB
- 读DB之后将新值更新给缓存
写请求:
- 直接写DB
- 从缓存中把DB的key进行删除
在大致的逻辑明确的基础上,FaceBook对于其中的几个进行了一些特殊的处理
平行请求以及请求合并
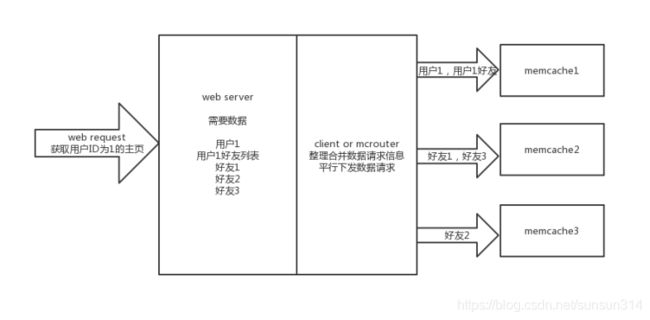
说白了就是对于可以并行获取的数据进行尽量的并行,并且为了防止过多的数据交互,尽量使得每个数据包承载的数据量趋于合理,将多个小请求进行合并成一个,降低网络交互的次数和可能由此引起的等待时间
基于UDP和TCP混合使用的网络交互
由于 TCP连接和UDP连接使用上存在较大的差别,TCP连接需要三次握手才能建立连接,之后再通过网络包进行数据的交互和查询,但是UDP连接直接能够省略其连接建立的过程
在一般的项目中,TCP连接自带的校验以及确保传输的功能非常有用,并且三次握手的消耗也基本感觉不到,所以TCP在一般网络项目中比较常见
Facebook这个缓存项目却有着不一样的看法,因为缓存的目的本身就是为了更快的提供服务,所以UDP协议能更好的提供“快”这一属性,因为对于这个服务来说,确保传输的缓慢网络远远比不上大部分能功能顺利的高速交互
最终,FaceBook采用了以下图中的交互方式,查询的部分走UDP提高速度,而具体有传输质量需求的部分使用TCP进行交互
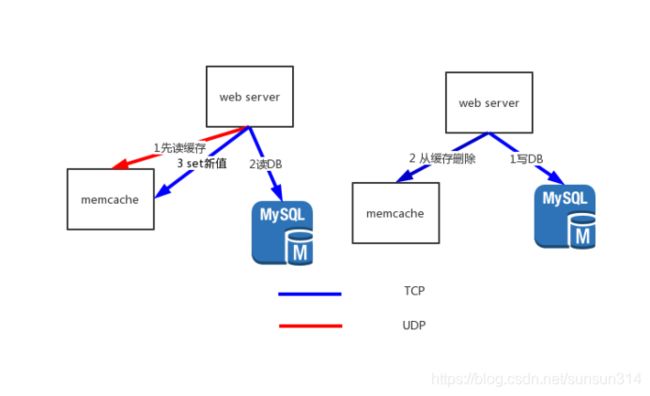
并且针对UDP不可靠交互的使用新增了如下的规则:
当UDP交互超过时间没能获取应答时,视作获取缓存失败,从DB获取新数据,但之后跳过更新缓存信息的步骤
基于滑动窗口的流量控制
TCP协议除了能提供确保包传输之外,还能提供一系列其他功能,包括包验证、基于滑动窗口的连接流量控制等等。
FaceBook使用UDP进行数据交互的时候只能自己设计了一套基于UDP协议的滑动窗口机制来确保对于流量进行控制
滑动窗口的基本原理并非什么独创的技术,TCP的原本实现中就有现成的案例,在这里就不进行展开了
Mcrouter的工作模式
上文中有提及Mcrouter是作为web server连接memcache的一个客户端进行使用,并且当web server需要查询特定key值的时候,Mcrouter可以对于当前key值进行计算,知晓具体去哪个或者哪几个memcache中获取数据
但是mcrouter和memcache还是存在着一些交互上的问题,特别是并发这个因素被引入系统之后,比较大的问题为以下两个
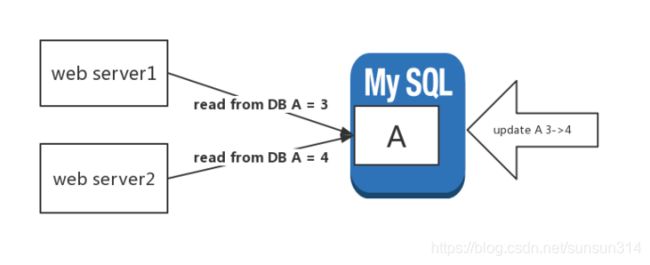
旧值覆盖
当存在如下这种情况时,有web server 1,2同时查询值A,并有其他请求实时更新A的值,致使A的值从3变成4,而server 1,2正好分别获取到一个值的两种状态3和4
根据上文中所属的缓存未命中的策略,A的值将被set到memcache中,以便于后续的缓存命中

但是由于两个时并行进行的,并且网络或者时机器边界上的数据我们没法控制其顺序,所以在memcache中的A的最终缓存值是不稳定的,并且由于后续的其他数据请求都能在memcache中查询到A的值,不论到底是多少,所以其他后续的请求不会去DB中校验A值的正确性
而我们可以知道,在这个场景中只有A的值一直是4才是符合正确这一要求的,也就是由于并发的关系A=3这个比较旧的状态可能会被覆盖到缓存中A=4的状态,导致后续的请求获取到的A都是3这个不正确的数据
Thundering herd
这个相对比较好理解,因为有时候单个热点数据会被各个方向的请求来回读写,造成了在缓存中热点数据被反复修改为无效,大量请求的数据获取击穿缓存直接将压力穿透到DB上,可能造成DB宕机或者连接超限等等灾难性后果,并且由于faceBook以及类似微博这样的服务上的数据特性,这个场景并非少见。
解决方式---lease
为了解决以上的两个问题,FaceBook采用了一种租约的方式来避免。
大致的工作方式如下
- 当一个查询没能命中缓存时,返回给这个查询一个租约lease 64位的taken
- 当此查询从DB中查询得到数据并set回缓存中时,需要提供lease
- 如果在lease提供出去之后的时间段内如果有请求使得key无效,则set数据不成功
- 并且针对每个key值,每10s只提供一个lease,若出现并发查询某个key值,则除了最快者获得lease,未获得lease的请求停滞短时间之后重试
通过这个机制,papper中声称将17k/s的DB查询缩减到1.3K/s,并且在这里文中提供了一种骚操作,当某个请求在更新一些key值时,部分key值需要被重新从DB获取,这就使得其他请求需要等待重试。
但是在FaceBook的实际应用场景中,可能数据的实时性不是特别重要,反而时及时响应更加重要,这个时候被删除或者标记为无效的key就会被返回作为查询值,使用过时的数据来获得更高的响应速度。
这种骚操作在我看来可能使用的场景比较有限,除了FaceBook这种高查询的之外可能少有能够应用的部分
Memcache pool
系统中的缓存信息在缓存系统中一般不会一视同仁,正如某个二八神教的理论说,什么东西都是二八分成的,虽然我平时不敢苟同,但是大致上数据的不平等性确实时客观存在的
在FaceBook的缓存系统中,将不同类型的key值分成不同的pool来进行管理,分别分成:
- 查询不频繁,缓存不命中影响小的
- 查询平凡或则缓存不命中从DB中获取数据耗时长的
当重要数据的pool资源不够的时候,就能通过pool的区分对于非重要数据的机器以及memcache资源进行挤压,来达到整体延迟消耗最小的结果
另一种机制则是在单个pool中如果发现热点机器或者热点的memcache server的时候,会有另一种key值切分的机制来进行负载的保护,通过将原来热点机器上面100个KEY值分割到两个机器或者时两个memcache中,每个各50个,增加整体缓存系统对于高并发的延迟性能体现
缓存查询的错误处理
错误处理往往是一个分布式项目的关键指标或者是关键特性,但是FaceBook这套系统对于错误处理的使用却特别的新奇,他们认为一般的错误只分成两种:
- 小规模的,部分机器和服务出现的错误
- 大规模的,整个集群发生的系统性的错误
当大规模的在某个Front cluster的缓存系统发生故障,那这Front cluster对应的缓存服务就被认定为不可用,对应集群中的web server则切换其缓存服务指向到其他相邻的缓存系统中去。
小规模的机器或者服务出现失败的时候,就会有部分冗余的机器和服务Gutter顶替失败节点的功能,这些冗余的节点大概占据了普通节点1%左右的机器
大致的参与情况如下
- Client查询memcache发现无数据
- 标记memcache server可能失败,查询Gutter是否有数据
- 若Gutter无数据再查询DB,并把结果写入Gutter
通过Gutter这种空闲节点的参与,当部分节点小规模的意外失败的时候,Gutter能很好的保护DB的负载不会被穿透得太高,以免因为某一两个服务或者机器的意外造成整体系统的崩溃
Region之间的缓存共享
正如分库分表中存在全局表的概念那样,一个整体的数据系统中,总是有部分数据存在这样的一种特性,数据基本不变化,并且负载并不高
对于这种类型的数据,在每个集群中给与一个数据的备份,特别是memcache的备份就有点不太经济了,特别还是在同一个区域甚至是机房中
这个时候FaceBook就有一种负载统计的机制,将部分访问频率低的数据放入一些特殊的memcache之中,并且将这些memcache被整个区域中的多个Front cluster共享,从而提高内存存储数据的效用
冷集群的启动方式
根据之前介绍的机制,很显然,当一个memcache集群启动的时候,里面的数据是要依靠从其他地方查询得到然后再进行缓存的,这里的其他地方如果是DB,那么就是说存在这么一种情况,只要是有新的memcache集群上线,那么就会有大量的请求击穿缓存直接将压力施加于DB之上,这么以来就带来了整个DB集群被压垮的风险,显然是不能被接受的
针对这种情况,FaceBook采用了一种妥协的方式,将新上线集群的后端指向已稳定运行的集群,当一开始大量请求击穿新缓存集群的时候,能够通过将压力转移到已有的缓存集群的方式进行疏导
直到新集群中的缓存命中达到一定比例之后,才将缓存未命中的流量直接发送给DB进行查询
写数据库如何更新缓存
前文中有提及,为了确保缓存数据至少在大部分情况下是最新的或者说是有效的,当web server对于某个既有的数据进行更新或者是 删除的过程中,需要在DB中执行完成操作之后再去缓存集群中将对应的key值进行无效化
但若是这个操作交给web server或者是web server使用的Mcrouter来进行,却又会带来响应速度的不利影响。于是FaceBook的团队想到了一种比较方便的方法来进行对应的key值无效化,当然这个是建立在一个基础之上的“部分提供旧有的数据对于项目不会有太大的影响”
其具体的操作流程如下图所示
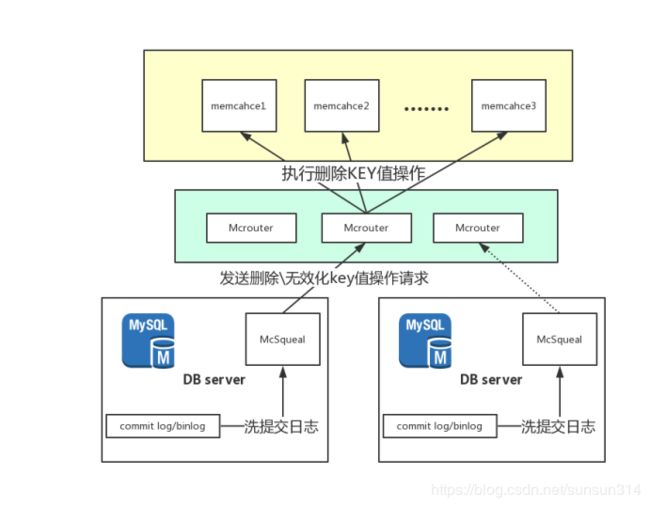
简单的描述为:
通过新增了一个数据库机器上本地的进程McSqueal来对于数据库的提交日志进行清洗,并根据清洗出来的数据发送给Mcrouter进行执行对应key值的无效化操作,并且最终由Mcrouter服务来执行并保证执行效果
这么以来出现了一个限制,也就是每个对于DB数据进行更新/删除的操作都需要带有自身的缓存KEY值,当然这点限制在FaceBook的团队来看不是什么问题
对比于直接由web server进行删除key的操作,这么进行项目的部署给FaceBook带来了两个好处:
- 当web server需要额外处理这个无效化时,需要执行更多的操作,会降低web server提供负载的能力,特别当需要一次性无效大量key值时
- 当出现偶发失败的情况下可以更加轻巧的重试或者时修复此次失败,因为web server对于这个操作的数据无法落地,所以存在丢失的风险,当这个信息丢失时,为了确保数据的正确性,往往需要重构memcache来进行恢复。但基于sql日志的操作可以一直重试一直读日志,直到成功为止,没有数据丢失的风险
写从库的数据库的处理方式
最后简单介绍下从库区域,或者说时非主机房区域的服务需要进行DB写入的时候时如何操作的,这种情况直接写从库一般都会出现各种各样的问题,比如生成的主键冲突,数据不一致,主从延迟高等等问题,特别时FaceBook的机房还分布于全世界的各个地方。
为了解决这个问题FaceBook提供了一种名为remote marker的机制来使得数据保持正确。
- 当web server准备更新一个key K的时候,web server获取一个Rk在这个Region中
- 写master机房的DB并且时K的缓存无效化
- 在本地的Region中删除K的缓存
当出现后续请求查询K的值时,本地缓存无法查询到数据,检查是否存在Rk区域标记,若标记存在,则不读取本地区域的DB,而是直接查询远端Master的DB数据,这么一来即使远端的数据和本地的数据存在复制的延迟,但是在本地新写入的数据也能被正常的查询到
后记:从FaceBook的缓存系统设计看缓存设计的关键
首先,缓存从整个FaceBook缓存系统的设计上来看,整个缓存的系统设计存在两个明显的目标
- 保护DB不被高并发击穿导致整体系统的宕机,因为DB才是所有数据的基础
- 提供更高的响应速度,使得用户的体验尽量好
在服务于这两个指标的同时,存在以下的问题上的尽量优化
- 尽量提供正确的数据,而非错误的或者过时的数据
- 提示用户的体验,可以在用户不关心的数据上提供过时数据,但是不能在用户关心的数据上出错
在以上的一些原则的指导下,所以整体系统设计的时候使用的机制存在几个特点
- 高并发或者是高压力下,一切以确保不让DB承受太高压力为最优先(包括租约、Gutter、缓存重分布机制、冷集群上线机制)
- 一般情况下以响应速度为优先(UDP查询使用,一般key值失效的异步洗日志机制)
- 而在用户关心的数据上以确保正确性为优先(远程标记机制确保用户的从区域的修改能被立刻查询到)