字符集和字符编码
基本概念
字符
计算机科学和信息科学中字符(character,或译为字元)是一个信息单位,通常来说就是一个字母、一个汉字、一个数字、一个标点符号。另外,还存在着一些控制字符,通常是不可打印的(不可见的,或称为是功能性的),有特定用途,以及emoji(绘文字)之类特殊的符号。字符集
字符集(character set)指的是指定若干字符组成的一个集合,通常这个集合具有一定的规模和合理性,比如囊括一个国家或地区日常使用的文字字符、数字、标点符号和控制字符等。不同的国家和地区由于历史和文化的原因,使用不同的语言文字,因此存在各种不同的字符集。字符编码
字符编码(character encoding)是把字符集中的字符映射为指定集合中某一对象(例如数字系统中表示为某个特定的二进制数),以便文本在计算机中存储和在通信网络传递。乱码
有字符的编码,就有相应的解码,解码出错就会导致乱码问题。乱码指的是由于使用不同的字符集或字符编码方式,导致显示的部分或全部字符无法被正常的阅读,如常见的文本、网页、邮件乱码。更多,可以参见cenalulus’s tech blog
字符集和字符编码的关系
字符集是书写系统字母与符号的集合,而字符编码则是将字符映射为一特定的字节或字节序列,是一种规则。通常特定的字符集采用特定的编码方式(即一种字符集对应一种字符编码,但Unicode不是,它采用现代的模型),因此基本上可以将两者视为同义词。
下面是关于常见字符集(字符编码)的介绍。
字符集很多,我们可以参见一下表格:
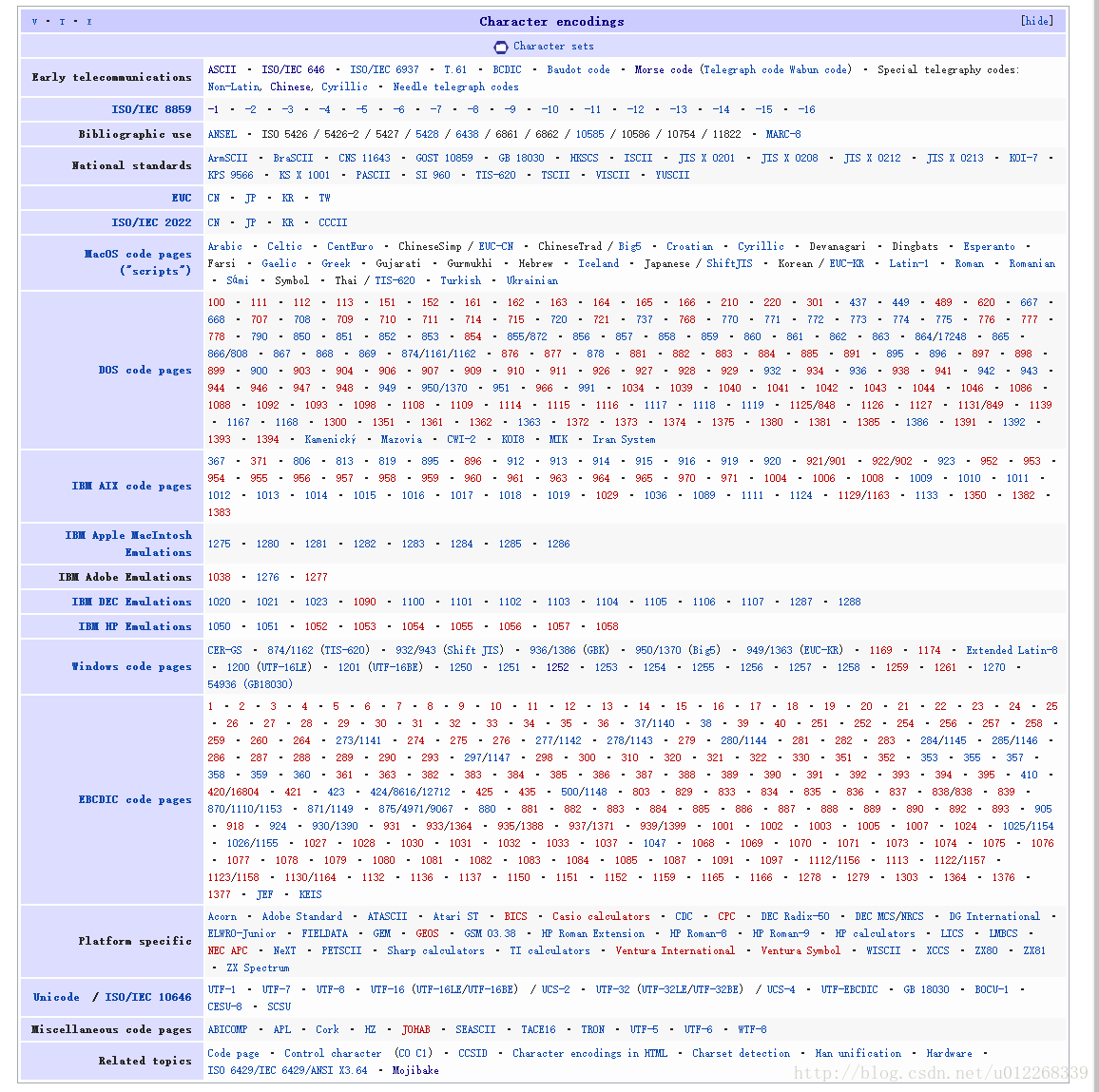
早期:计算机时代之前
密码学中加密,可以认为是一种广义的字符编码,但它的目的与本文所阐释的有所不同,因此不予展开。早期字符编码的一个最好的例子是在通信领域(无线电)存在的摩尔斯电码。
摩尔斯电码(又译为摩斯密码,Morse code)是一种时通时断的信号代码,通过不同的排列顺序来表达不同的英文字母、数字和标点符号。它发明于1837年,以美国人塞缪尔·莫尔斯(Samuel F. B. Morse,1791年4月27日 – 1872年4月2日)命名。 摩尔斯电码代码包括五种: 点(dots或dits)、划(dashes或dashs)、点和划之间的停顿、每个字符间短的停顿(在点和划之间)、每个词之间中等的停顿以及句子之间长的停顿。
有意思的是摩尔斯电码也存在不同的编码方式,有美式编码,德式和现在国际通行的ITU标准。下图是ITU标准的摩尔斯电码:

补充:
在电报的发展和传播是中,中国也出现了中文电码,最早是法国驻华人员威基杰(S.A. Viguer)于1873年参照《康熙字典》的部首排列方法,挑选了常用汉字6800多个,编成了第一部汉字电码本《电报新书》。它采用由四个阿拉伯数字代表一个汉字的方法,常称为“四码电报”。
单字节:ASCII和它的继承者们
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是 ANSI(American National Standard Institute,美国国家标准学会)为英语设计的单字节字符编码方案,主要包括英文字母、阿拉伯数字、英文标点符号和一些控制符号(来自早期的打字机),用于基于文本的数据。ASCII标准的工作由ASA( American Standards Association,美国标准联合会;即现在的ANSI)的下属部门于1960年开始,1963首版,1967经过重新修订,1986年是最新版本。ASCII总共包括128个字符,所以在只需要7位二进制数表示即可。由于计算机中1个字节是8位二进制数,一般表示时最高位设置为0。
它起始于50年代后期,在1967年定案。最初是美国国家标准,供不同计算机在相互通信时用作共同遵守的西文字符编码标准,它已被ISO(International Organization for Standardization, 国际标准化组织)和IEC(International Electrotechnical Commission,国际电工委员会)定为国际标准,称为ISO/IEC 646标准。参见下图:
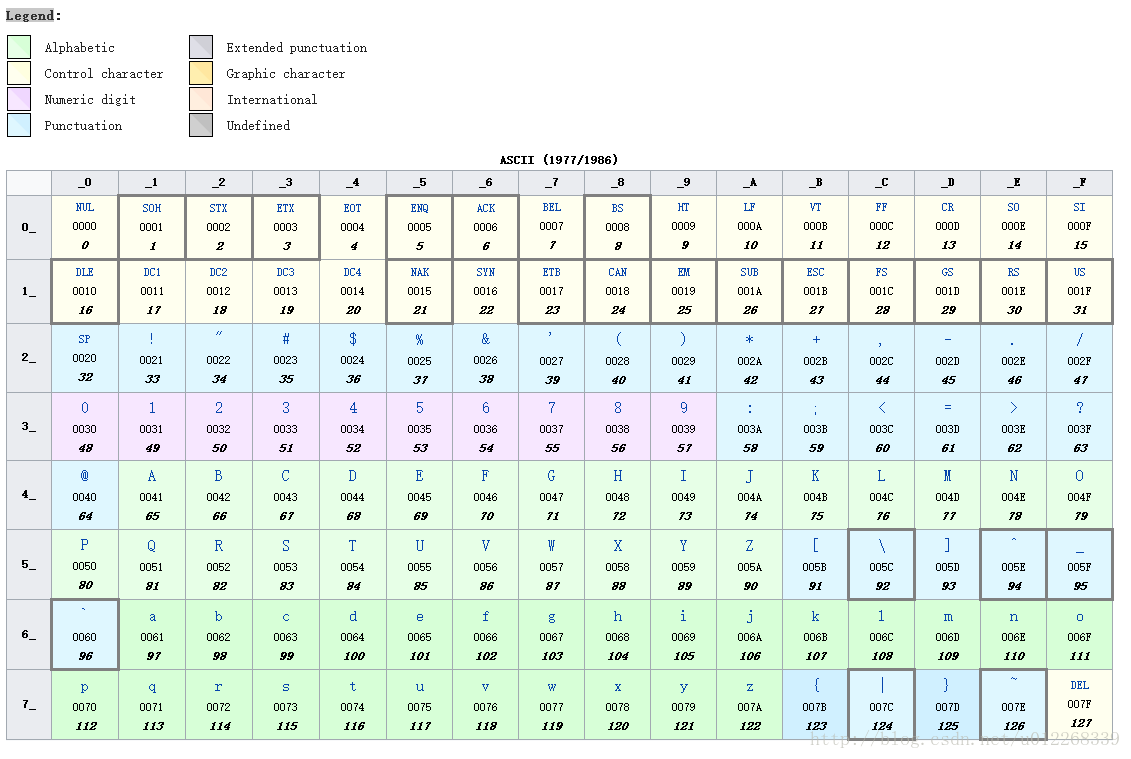
| 序号(十进制) | 十六进制范围 | 说明 |
|---|---|---|
| 0~31 | 0x00~0x1F | 控制字符 |
| 32~126 | 0x20~0xEE | 可显示(打印)字符,包括空格、标点符号、大小写字母和阿拉伯数字等 |
| 127 | 0xEF | 删除控制符(DEL) |
说明:
ASCII的方案参考之前存在的DEC SIXBIT编码表,与老式的打字机有关。另外,IBM在1963-1964年推出过自己字符编码方案,主要是根据早期的打孔机BCD编码有关,叫EBCDIC(Extended Binary Coded Decimal Interchange Code,扩展二进制编码转换十进制代码)。
对于非英语的欧洲国家,存在这不同的字母形式,因此需要扩充编码表,因此出现来EASCII(Extended ASCII,扩展ASCII)。EASCII使用8位二进制,可以表示256个不同字符,但现在很少使用了。
国际标准化的相关组织在ASCII的基础上进行了扩展,形成了ISO/IEC 8859系列标准(简称ISO 8859),兼容ASCII,包括ISO 8859-1到ISO 8859-16(共15个编码方案/字符集,其中12是空缺的)。其中ISO 8859-1(完整:ISO/IEC 8859-1:1998)也称为Latin-1,扩展部分主要包括西欧国家的字符,第一版出版于1987年。方案利用了第8位编码,相比ASCII多了0x80-0xFF,其中的0xA0-0xFF部分,被ISO/IEC 8859编码所用到。
ISO/IEC 6429编码标准是有关控制字符的编码标准,不仅定义了0x80-0x9F(称为C1控制字符),还定义了0x0-0x1F,即ASCII中的控制字符(称为C0控制字符)。
ISO 8859和ISO-8859的区别和联系
ISO 8859是ISO/IEC 8859标准集合的简称,对应包含了 ISO/IEC 8859-n,除去12之外的1到16,这共15种字符集合,是可见字符的编码。
ISO-8859,是ISO-8859-n的简称,是IANA(The Internet Assigned Numbers Authority,互联网数字分配机构)根据ISO/IEC 8859-n的标准,加上对应的前面提到的普通的ASCII字符,和ISO/IEC 6429所定义的的控制字符,所制定的标准。
不过,一般而言可是视为统一,即把包含所有的控制和可见字符。
补充:一个字节为何是8位(1 byte = 8 bits)?
总的而言是历史遗留问题,一方面考虑了二进制的特点(计算机原理),另一方面考虑了信息容量。8位表示1字节(1 byte = 8 bits)的标准最早来自与IBM system/360(1950年代到1960年代)。此外还设计早期存储介质的造价成本、商业利益。
另:计算机中还存在这内存字节边界对齐的问题和CPU读取指令和数据大端和小端的问题,IP地址的位数(IPv4和IPv6),不过目前这方面的争论不多,不像程序员(开发者)之间的大括号和编辑器的争论。
双字节:东方诸国的万“码”奔腾
亚洲,尤其是东亚国家和地区(中国、日本等),使用的并不是拼音文字,基本的字符基数相当大,因此单字节根本不够用,于是双字节的表示出现。(汉字这种象形文字,对于计算机编码和存储是相当不友好的,因此才会有早年多种汉字输入法探索与发展)
双字节的表示,可以表示65536个字符(2的16次方),因此一般情况下是够用的。与欧洲一样,亚洲各国和地区出现了各种互不相同的字符编码,如中国大陆的GB2312、港台的BIG-5、日本的Shift-JIS等。
字符的编码不仅仅是将字符排一个序,然后就直接挨个编号。考虑易用性和兼容性,字符编码需要一套科学的设计方案。比如ASCII方案中,阿拉伯数字('0'-'9')、大写字母('A'-'Z')、小写字母('a'-'z')是连续排列的,同时在使用进制中,分别以0x30、0x41和0x61开始。
下面细说以下国内的汉字编码方案
由于使用的目的不同,存在几种编码方案:
汉字的外码(输入码)
不同与英文,汉字数目众多,无法用按键一一表示,因此需要对键盘的输入进行额外的编码处理,于是有了外码。外码也叫输入码,是用来将汉字输入到计算机中的一组键盘符号。常用的输入码有拼音编码方案(如全拼输入法的智能ABC、双拼输入法的自然码等)、字形编码方案(如五笔输入法、郑码输入法等)、数字编码(如区位码)以及音形混合编码等。汉字的交换码(国标码)
信息交换码是为了应对人所使用是的符号(文字)和计算机所处理的符号(二进制)侧重不同而产生的。《信息交换用汉字编码字符集》是由中国国家标准总局(国家标准化管理委员会)1980年发布,1981年5月1日开始实施的一套国家标准,标准号是GB 2312-1980,也称为国标码。此编码重要通行于中国大陆。汉字的机内码(机器码)
根据国标码的规定,每一个汉字都有了确定的二进制代码,在计算机的内部汉字代码都用机内码,在磁盘上记录汉字代码也使用机内码。汉字的字形码(输出码)
字形码是汉字的输出码,主要用于显示或打印汉字。每一个汉字按照图形用一个点阵图表示(如16×16或24×24),由此得到的对应汉字的点阵代码(即字型码)。16×16的点阵表示一个汉字需要使用32个字节存储。通常用于显示的汉字字体集合称为显示字库,用于打印的字体集合叫打印字库,两者统称为汉字字库。另外字库可以分为软字库和硬字库:软字库以文件方式存在硬盘中,即通常的字体文件;硬字库则是将字库固化在单独的只读存储芯片中,通过接口设备与计算机连接,如早期计算机使用的汉卡。
输出汉字时都采用图形方式,无论汉字的笔画多少,每个汉字都可以写在同样大小的方块中。通常用16×16点阵来显示汉字。
几者的关系
通常而言机内码的基础是交换码(即国标码,也是本文讨论的字符编码),它是字符在计算机中二进制的表示形式。外码(输入码)是为了键盘等设备输入汉字而设计的编码方案,如全拼、五笔、区位码等。而字形码(输出码)是为了显示(或打印)汉字而使用的编码,等同于字体库。
中国大陆的字符编码方案
中国大陆的字符编码方案的主要有GB2312, GBK,GB1300, GB10830。相关文件:
- GB 2312-80《信息交换用汉字编码字符集-基本集》(1980年)
- GB 13000.1-93《信息技术 通用多八位编码字符集(UCS) 第一部分:体系结构和基本多文种平面》(1993年)
- GBK 《汉字内码扩展规范》1.0版(1995年)
- GB 18030-2000《信息技术 信息交换用汉字编码字符集 基本集的扩充》(2000年)
- GB 18030-2005《信息技术中文编码字符集》(2005年)
国标码 GB 2312:
GB 2312基本集共收入字符7445个,其中汉字6763个(其中一级汉字3755个,二级汉字3008个)和非汉字图形字符682个(包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个全角字符。)。缺陷在于仅收录了常用字,对于人名、古汉语中的罕见字缺少表示。
整个国标码由一个94×94的方阵构成,分为94个“区”,每区包含94个“位”,其中“区”的序号由01至94,“位”的序号也是从01至94。94个区中位置总数=94×94=8836个,其中7445个汉字和图形字符中的每一个占一个位置后,还剩下1391个空位,这1391个位置空下来保留备用。每个区位上只有一个字符,因此可用所在的区和位来对汉字进行编码,称为区位码,可以用作输入码。
| 区域范围 | 说明 |
|---|---|
| 01-09区 | 收录除汉字外的682个字符,有164个空位 |
| 10-15区 | 空白区,没有使用 |
| 16-55区 | 收录3755个一级汉字(简体),按拼音排序 |
| 56-87区 | 收录3008个二级汉字(简体),按部首/笔画排序 |
| 88-94区 | 空白区,没有使用 |
GB2312编码范围:A1A1-FEFE,其中汉字编码范围:B0A1-F7FE。
举例来说,“啊”字是GB2312编码中的第一个汉字,它位于16区的01位,所以它的区位码就是1601(十进制)。
国标码的发展:
GB13000
1993年,国际标准Unicode 1.1版本推出,收录中国大陆、台湾、日本及韩国通用字符集的汉字,总共有20,902个。
中国大陆订定了等同于Unicode 1.1版本的“GB 13000.1-93”,简称为GB13000。它兼容GB2312,同时收录更多汉字,包括新简化字、生僻字以及台湾和香港使用的繁体字,日语朝鲜语中的汉字等,共20,902个字符。GBK
1995年12月颁布的《汉字编码扩展规范》(GBK,国标扩),它只是一个“技术规范指导性文件”。它共包含23940个码位,收录了21003个汉字,完全兼容GB2312-80标准,支持国际标准ISO/IEC10646-1和国家标准GB13000-1中的全部中日韩汉字,并包含了BIG5编码中的所有汉字。GB18030
国家标准GB18030-2005《信息技术中文编码字符集》是我国继GB2312-1980和GB13000.1-1993之后最重要的汉字编码标准,是我国计算机系统必须遵循的基础性标准之一。
GB18030有两个版本:GB18030-2000(《信息交换用汉字编码字符集基本集的补充》)和GB18030-2005。GB18030-2000是GBK的取代版本,它的主要特点是在GBK基础上增加了CJK统一汉字扩充A的汉字,2000版本仅规定了常用非汉字符号和27533个汉字(包括部首、部件等)的编码。GB18030-2005是以汉字为主并包含多种我国少数民族文字(如藏、蒙古、傣、彝、朝鲜、维吾尔文等)的超大型中文编码字符集强制性标准,是在GB18030-2000基础上增加了CJK统一汉字扩充B的汉字,其中收入汉字70000余个,。
其他相关
半角和全角
全角符号的问题主要来自于双字节编码的历史遗留。印刷上纵横比为1:1的字符(块)称为全角,而早期为了在纯文本界面(终端)中将英文等单字节字符和中日韩的方块字符对齐,使得西文的字母、数字、标点等占用一个汉字的宽度。这与编程中常见的等宽字体类似。目前而言,这些等宽的的西文字母等几乎不再使用,但在Unicode字符集中进行了吸纳。全角和半角的切换:
部分输入法如搜狗拼音中有设置按钮,也可以使用快捷键【Shift+空格】。
东亚的其他国家
台湾、香港、澳门地区
台湾、香港、澳门通常采用的字符编码是Big5(大五码)。大五码是由资策会于1984年策划制定,拥有13053个中文字(繁体中文)、408个字符以及33个控制字符的字集,是早期中文电脑的业界标准和中文网络社区常用的电子汉字字集标准。
日本
日本常见的字符编码是Shift JIS(Shift Japanese Industrial Standards,也简称SJIS, MIME中称为Shift_JIS)。它是日本计算机系统中常用的编码表,能容纳全形及半形拉丁字母、平假名、片假名、符号及日本汉字。
韩国
韩国以前使用KS编码,如KS X 1001是用于书写的谚文和汉字的字符编码规格,它包含谚文2350个、汉字4888个、英文字母、数字和假名合计8226字。
CJKV
CJKV是Chinese、Japanese、Korean、Vietnamese这4种语言的合称,历史上,它们都属于东亚的汉字文化圈和儒家文化圈,日常使用涉及汉字或类似汉字的自造字(hànzì in Chinese, kanji, kana in Japanese, hanja, hangul in Korean, and Hán tự, chữ Nôm in Vietnamese)。
EUC
EUC(Extended Unix Code,扩展Unix系统代码),是一个使用8位编码来表示字符的方法。EUC最初是针对Unix系统,由一些Unix公司所开发,于1991年标准化。EUC基于ISO/IEC 2022的7位编码标准,因此单字节的编码空间为94,双字节的编码空间(区位码)为94x94。把每个区位加上0xA0来表示,以便符合ISO 2022。它主要用于表示及储存汉语文字、日语文字及朝鲜文字。包括EUC-CN,EUC-TW,EUC-JP,EUC-KR,EUC-KP。
多字节:Unicode分久必合的大一统梦想
互联网的出现,信息技术的高速发展,不同地域的资讯交流愈加频繁。不同国家和地区的计算机在交换数据的过程由于字符编码格式的不同,造成数据解析乱码,因此需要有一个统一的编码方式以方便大家使用。Unicode(统一码,或译为万国码、国际码、单一码)应运而生。它对世界上大部分的文字系统进行了整理、编码,使得计算机系统可以用更为简单有效的方式来呈现和处理文字.

历史上存在两个独立的尝试创立单一字符集的组织,即国际标准化组织(ISO)和统一码联盟(The Unicode Consortium,非正式译名)。
前者开发了ISO/IEC 10646项目(简称为ISO 10646),此标准所定义的字符集,称作为通用字符集(Universal Character Set,UCS)。后者成员主要是计算机软硬件厂商,它开发了Unicode项目。他们在项目启动不久便发现对方的存在,并有着相同的目的,于是两个组织便共同合作开发适用于各国语言的通用码,但依旧各自发表The Unicode Standard和ISO 10646字符集。虽然实质上两者确实为两个不同的标准,但实际上两者的字集编码相同,可以合称为Unicode/UCS,只是The Unicode Standard包含了更详尽的实现信息、涵盖了更多细节的主题。
2016年6月21日公布了Unicode 9.0.0版本,新增支持7500种新字符,总数达到128,172种,本次包括72种新emoji表情和、19种新电视符号和一些小众语言等。
Unicode的实现方式
Unicode只是一个字符集,规定了字符的二进制代码,而具体的实现方式并没有规定,因此出现了UTF-8、UTF-16和UTF-32等编码实现方式,其中UTF是指Unicode Transformation Format(统一码转换格式)。
UTF-8
UTF-8是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度,优点是兼容ASCII,但表示汉字通常需要3个字节。UTF-8的编码规则很简单,只有二条:- 对于单字节的符号,字节的第一位设为0,后面7位为这个符号的Unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的
- 对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的Unicode码
UTF-16
UTF-16是Unicode字符编码五层次模型的第三层:字符编码表(Character Encoding Form,也称为 “storage format”)的一种实现方式。即把Unicode字符集的抽象码位映射为16位长的整数(即码元)的序列,用于数据存储或传递。Unicode字符的码位,需要1个或者2个16位长的码元来表示,因此这是一个变长表示。另:根据16位中两个字节的排序顺序可分为UTF-16BE和UTF-16LE。UTF-32
UTF-32 (或 UCS-4)是一种将Unicode字符编码的协议,对每一个Unicode码位使用恰好32位,只在0到10FFFF的字码空间(百万个码位)。UTF 只有此一种定长编码。
UTF-32 原本是一个 UCS-4 的子集,但就现状而言,除了 UTF-32 标准包含额外的 Unicode 意义,UCS-4 和 UTF-32 大体是相同的。
其他(操作系统、编程语言)
代码页(Code Page)是操作系统中字符编码的另一种说法。它起源于IBM,并被微软等厂商采用。不同的厂商通常会有自己定义的代码页,不同的代码页对应不同的字符集。
Windows系统的字符编码
Windows中的Code Page,按照应用领域来划分,可以分为两类:Windows Code Page和 OEM Code Page。其中最广泛的是给予ANSI草案的Windows 1252,用于英语和西欧语言字符。
Windows Code Page(也叫ANSI Code Page),用于Windows系统中,本地编码是非Unicode的,图形用户界面(GUI)程序。
OEM Code Page主要Windows系统中的命令行界面,常见的cp 437(原始的IBM PC代码页,实现了扩展ASCII字符集), cp936(对应简体中文的GBK字符集), cp 65001(UTF-8实现的Unicode字符集)。
Windows记事本中的BOM问题
BOM(Byte Order Mark,字节顺序标记),出现在文本文件头部,Windows系统中用于标识文件采用的编码格式、文件/字符流的大小端(字节序),通常不可见。但对于一些编程语言而言,会误认为特殊字符而试图做出解析从而导致意想不到的后果。因此,编写程序不要使用Windows自带的记事本。
其他操作系统
Linux系统、macOS(OS X, Mac OS X)的本地文本编码实现一般是UTF-8。其他Unix系统以及衍生BSD系统不是很清楚,可以自己查询。
编程语言的支持
略。
传输协议中设计的编码
- Base 64
- MIME
- Quoted-Printable编码
参考
参考资料:
- 主要是维基百科、百度百科、知乎以及CNBLOG、简书等博客。
延伸阅读:
字符编码教程,版本:v2.3.1(Crifan Li, 2015)
http://www.crifan.com/files/doc/docbook/char_encoding/release/html/char_encoding.html十分钟搞清字符集和字符编码-为什么会出现乱码(卢钧轶,2015)
http://cenalulu.github.io/linux/character-encoding/#toc4Windows中的字符编码,记事本中的BOM(知乎知友,2012-2013)
https://www.zhihu.com/question/20650946/answer/15745831统一码联盟官网
http://www.unicode.org
插图说明:
- 图1(多种字符编码的表格)和图3(ASCII)来自维基百科相关英文词条的截图
- 图2( ITU标准的莫尔斯电码)来自维基百科英文词条(Morse Code)
- 图4(Unicode logo)来自维基百科英文词条(Unicode)
文件说明:
- 国内关于中文编码字符集的几个相关文件,在国家相关政府部分网站(标准化委员会、工信部等)并没有找到(可能是不得其法),但在网上搜一搜还是可以得到一些。