BUAA面向对象第一单元总结
我的博客原文链接戳这里
OO Unit1总结博客
(「・ω・)「 我用的是IntelliJ IDEA,下面的功能和插件都基于IDEA,所有的图如果觉得字太小可以右键查看高清大图~
程序设计思路
第一单元主要做了含有幂函数和三角函数及其嵌套的表达式求导。
第一次作业由于只有幂函数,而且幂函数的形式很单一,所以可以直接用正则表达式
| 1 |
|
然后用matcher的find()即可方便的分离出每一个项,这个正则不能识别常数项,但是由于常数项求导后就是0,所以可以忽略不计。
第二作业加入了sin(x), cos(x)相乘,所以每一项实际上都有固定的格式:
系数*x^幂指数*sin(x)^正弦指数*cos(x)^余弦指数
第二次作业的基本思路如下:
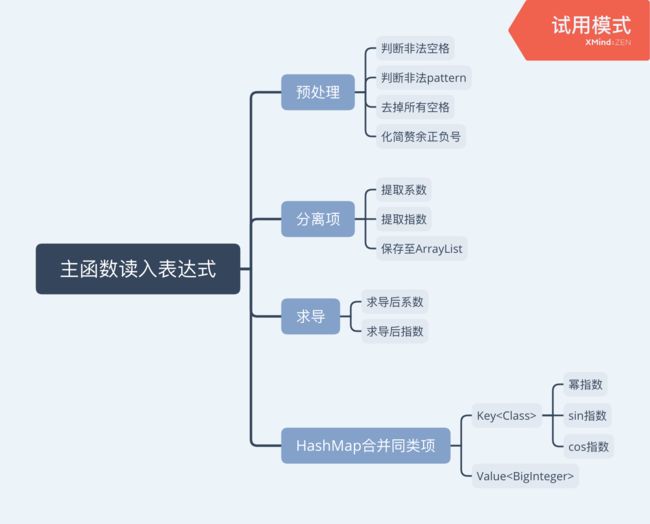
第三次作业加入了嵌套和表达式因子,思维导图如下:

写程序时如何避免难以定位错误的情况?
-
不同功能单独分离模块,在写完一个类就立即对它进行测试,否则后期找Bug会很困难
-
IDEA的Debug功能很好用,每一个变量都可以追踪,但是后面看会很费眼睛
-
在方法当中穿插“println”来判断某个模块(部分)功能有没有正确完成。println 方法
虽然被诟病,运行的时候清晰明了,如果有中途不期望的输出,可以只关注最重要的信息,是哪个关键部位出了问题,定位也比较快
基于度量分析程序结构
Complexity Metrics(复杂度分析)
在Method的分析结果中可以看到ev, iv, v这几栏,分别代指基本复杂度(Essential Complexity (ev(G))、模块设计复杂度(Module Design Complexity (iv(G)))、Cyclomatic Complexity (v(G))圈复杂度。
-
ev(G)基本复杂度是用来衡量程序非结构化程度的,非结构成分降低了程序的质量,增加了代码的维护难度,使程序难于理解。
因此,基本复杂度高意味着非结构化程度高,难以模块化和维护。实际上,消除了一个错误有时会引起其他的错误。
-
Iv(G)模块设计复杂度是用来衡量模块判定结构,即模块和其他模块的调用关系。
软件模块设计复杂度高意味模块耦合度高,这将导致模块难于隔离、维护和复用。模块设计复杂度是从模块流程图中移去那些不包含调用子模块的判定和循环结构后得出的圈复杂度,因此模块设计复杂度不能大于圈复杂度,通常是远小于圈复杂度。
-
v(G)是用来衡量一个模块判定结构的复杂程度,数量上表现为独立路径的条数,即合理的预防错误所需测试的最少路径条数,圈复杂度大说明程序代码可能质量低且难于测试和维护。
经验表明,程序的可能错误和高的圈复杂度有着很大关系。
-
对于Class,有OCavg和WMC两个项目,分别代表类的方法的平均循环复杂度和总循环复杂度。
第一次作业Complexity Metrics
| Method | ev(G) | iv(G) | v(G) |
|---|---|---|---|
| DeriItem.deri(BigInteger,BigInteger) | 1 | 4 | 4 |
| DeriItem.fixCoeff(BigInteger) | 1 | 1 | 1 |
| DeriItem.getDeriCoeff() | 1 | 1 | 1 |
| DeriItem.getDeriExpo() | 1 | 1 | 1 |
| Derivation.coeff(int) | 1 | 1 | 1 |
| Derivation.exopo(int) | 1 | 1 | 1 |
| Derivation.findInvalid(Matcher) | 6 | 5 | 6 |
| Derivation.getTotalItemNum() | 1 | 1 | 1 |
| Derivation.main(String[]) | 5 | 11 | 11 |
| Derivation.print() | 3 | 15 | 15 |
| Derivation.printZero() | 2 | 3 | 4 |
| Derivation.setTotalItemNum(int) | 1 | 1 | 1 |
| Item.Get(String) | 7 | 10 | 21 |
| Item.getCoeff() | 1 | 1 | 1 |
| Item.getExponent() | 1 | 1 | 1 |
| Class | OCavg | WMC |
|---|---|---|
| DeriItem | 1.5 | 6 |
| Derivation | 4.25 | 34 |
| Item | 5.33 | 16 |
由表可见,Item.Get(String)这个函数复杂度过高,是由于我在这段代码中含有很多的 if / else 语句。
但是解析一个幂函数的系数和指数并不需要toCharArray一个个字符地去判断,这个地方写的冗余了,以后改进。
第二次作业Complexity Metrics
| Method | ev(G) | iv(G) | v(G) |
|---|---|---|---|
| CosFunc.GetCosNum(String) | 1 | 3 | 3 |
| CosFunc.getCosCoeff() | 1 | 1 | 1 |
| CosFunc.getCosExpo() | 1 | 1 | 1 |
| Item.Cut() | 1 | 3 | 3 |
| Item.DeriItem() | 1 | 5 | 5 |
| Item.getDeriItem1() | 1 | 1 | 1 |
| Item.getDeriItem2() | 1 | 1 | 1 |
| Item.getDeriItem3() | 1 | 1 | 1 |
| Item.initializeMap(HashMap |
1 | 1 | 1 |
| Item.serString(String) | 1 | 1 | 1 |
| Mainclass.CheckInvalid(String) | 5 | 11 | 11 |
| Mainclass.MergeItem(Merge,Merge,Merge) | 7 | 13 | 13 |
| Mainclass.SplitString(String) | 7 | 11 | 11 |
| Mainclass.main(String[]) | 4 | 2 | 4 |
| Mainclass.preTreatment(String) | 1 | 2 | 2 |
| Mainclass.printAll() | 3 | 12 | 12 |
| Merge.Compare(Merge) | 2 | 3 | 4 |
| Merge.fixCoeff(BigInteger) | 1 | 1 | 1 |
| Merge.getCoeff() | 1 | 1 | 1 |
| Merge.getCosExpo() | 1 | 1 | 1 |
| Merge.getPowerExpo() | 1 | 1 | 1 |
| Merge.getSinExpo() | 1 | 1 | 1 |
| Merge.setMerge(HashMap |
1 | 1 | 1 |
| NormalFunc.JudgeType() | 1 | 12 | 12 |
| NormalFunc.getCoeff() | 1 | 1 | 1 |
| NormalFunc.getExpo() | 1 | 1 | 1 |
| NormalFunc.setItem(String) | 1 | 1 | 1 |
| PowerFunc.GetPowerNum(String) | 1 | 12 | 12 |
| PowerFunc.getPowCoeff() | 1 | 1 | 1 |
| PowerFunc.getPowExpo() | 1 | 1 | 1 |
| SinFunc.GetSinNum(String) | 1 | 3 | 3 |
| SinFunc.getSinCoeff() | 1 | 1 | 1 |
| SinFunc.getSinExpo() | 1 | 1 | 1 |
| Class | OCavg | WMC |
|---|---|---|
| CosFunc | 1.67 | 5 |
| Item | 1.86 | 13 |
| Mainclass | 7.67 | 46 |
| Merge | 1.14 | 8 |
| NormalFunc | 2.75 | 11 |
| PowerFunc | 3.67 | 11 |
| SinFunc | 1.67 | 5 |
由于幂函数的解析部分我直接套用了第一次作业的,故第二次作业复杂度高的方法依然出现在了幂函数提取系数和指数的地方。
第三次作业Complexity Metrics
| Method | ev(G) | iv(G) | v(G) |
|---|---|---|---|
| Constant.Constant(BigInteger) | 1 | 1 | 1 |
| Constant.getConstant() | 1 | 1 | 1 |
| CosFunc.CosFunc(String) | 1 | 4 | 4 |
| CosFunc.DeriCos() | 1 | 4 | 4 |
| CosFunc.getCosCoeff() | 1 | 1 | 1 |
| CosFunc.getCosExpo() | 1 | 1 | 1 |
| Expression.DeriExp() | 3 | 3 | 4 |
| Expression.Expression(String) | 6 | 16 | 21 |
| Item.DeriItem() | 1 | 2 | 4 |
| Item.Item(String) | 1 | 1 | 1 |
| Item.Parse() | 6 | 8 | 9 |
| Item.cut() | 1 | 16 | 16 |
| MainClass.CheckValid(String) | 7 | 15 | 15 |
| MainClass.DeriMain() | 1 | 2 | 2 |
| MainClass.Distribute(String) | 6 | 7 | 11 |
| MainClass.main(String[]) | 1 | 4 | 4 |
| MainClass.preTreatment(String) | 1 | 2 | 2 |
| Nested.DeriNest() | 1 | 3 | 7 |
| Nested.JudgeFactor() | 14 | 15 | 25 |
| Nested.Nested(String) | 1 | 12 | 25 |
| NodeContent.DeriContent() | 7 | 7 | 7 |
| NodeContent.JudgeExp(String) | 11 | 10 | 22 |
| NodeContent.JudgeItem(String) | 7 | 1 | 8 |
| NodeContent.getType() | 1 | 1 | 1 |
| NodeContent.setContent(String) | 1 | 18 | 21 |
| PowerFunc.DeriPower() | 1 | 3 | 5 |
| PowerFunc.PowerFunc(String) | 1 | 15 | 15 |
| PowerFunc.getPowCoeff() | 1 | 1 | 1 |
| PowerFunc.getPowExpo() | 1 | 1 | 1 |
| SinFunc.DeriSin() | 1 | 4 | 4 |
| SinFunc.SinFunc(String) | 1 | 4 | 4 |
| SinFunc.getSinCoeff() | 1 | 1 | 1 |
| SinFunc.getSinExpo() | 1 | 1 | 1 |
| TreeNode.Deri() | 1 | 1 | 1 |
| TreeNode.TreeNode() | 1 | 1 | 1 |
| TreeNode.TreeNode(String) | 1 | 1 | 1 |
| TreeNode.contentType() | 1 | 1 | 1 |
| TreeNode.setChild(TreeNode) | 1 | 1 | 1 |
| Class | OCavg(平均循环复杂度) | WMC(总循环复杂度) |
|---|---|---|
| Constant | 1 | 2 |
| CosFunc | 2.5 | 10 |
| Expression | 9 | 18 |
| Item | 6.25 | 25 |
| MainClass | 4.2 | 21 |
| Nested | 12.33 | 37 |
| NodeContent | 9 | 45 |
| PowerFunc | 4.5 | 18 |
| SinFunc | 2.5 | 10 |
| TreeNode | 1 | 5 |
第三次作业中,单一函数类平均循环复杂度还是很小的,说明这几个模块耦合低,分离得比较成功,也便于维护。但是嵌套和表达式因子相关的类复杂度较大,容易出现 Bug,Debug的时间也更长。尤其是Nested类中有几个函数圈复杂度大于20,应该在重构的时候考虑如何分散这些功能。
Dependency Metrics(依赖度分析)
依赖度分析度量了类之间的依赖程度。有如下几种项目:
-
Cyclic:指和类直接或间接相互依赖的类的数量。这样的相互依赖可能导致代码难以理解和测试。
-
Dcy和Dcy*:计算了该类直接依赖的类的数量,带*表示包括了间接依赖的类。
-
Dpt和Dpt*:计算了直接依赖该类的类的数量,带*表示包括了间接依赖的类。
第一次作业Dependency
| Class | Cyclic | Dcy | Dcy* | Dpt | Dpt* |
|---|---|---|---|---|---|
| DeriItem | 0 | 0 | 0 | 1 | 1 |
| Derivation | 0 | 2 | 3 | 0 | 0 |
| Item | 0 | 1 | 1 | 1 | 1 |
第二次作业Dependency
| Class | Cyclic | Dcy | Dcy* | Dpt | Dpt* |
|---|---|---|---|---|---|
| CosFunc | 0 | 0 | 0 | 1 | 3 |
| Item | 0 | 2 | 5 | 1 | 1 |
| Mainclass | 0 | 3 | 7 | 0 | 0 |
| Merge | 0 | 0 | 0 | 1 | 1 |
| NormalFunc | 0 | 3 | 4 | 1 | 2 |
| PowerFunc | 0 | 1 | 1 | 1 | 3 |
| SinFunc | 0 | 0 | 0 | 1 | 3 |
第三次作业Dependency
| Class | Cyclic | Dcy | Dcy* | Dpt | Dpt* |
|---|---|---|---|---|---|
| Constant | 0 | 0 | 0 | 0 | 0 |
| CosFunc | 0 | 0 | 0 | 2 | 6 |
| Expression | 4 | 1 | 8 | 2 | 5 |
| Item | 4 | 6 | 8 | 1 | 5 |
| MainClass | 0 | 1 | 9 | 0 | 0 |
| Nested | 4 | 2 | 8 | 2 | 5 |
| NodeContent | 4 | 7 | 8 | 1 | 5 |
| PowerFunc | 0 | 1 | 1 | 2 | 6 |
| SinFunc | 0 | 0 | 0 | 2 | 6 |
| TreeNode | 4 | 1 | 8 | 3 | 5 |
由表可见,前两次作业的类之间相互依赖的情况为0,而第三次出现了。
类图
由于第一次作业只有三个类,当时没有面向对象的思维,写出来的方法都是互相调用的,耦合度高,不具有代表性,第二次作业和第三次作业结构类似,故这里以第三次作业为例子:
下面用IDEA的PlantUML插件,步骤戳这里
记得点击“Show Dependencies”这个小按钮才可以看到类与类之间的连接情况
最终类图如下:

发现右上角有个落单的常数项类,在本次求导中没有用上,在Item当中发现常数项直接返回了0。
分析自己程序的Bug
被Hack样例
最主要的特征:没有正确判断出格式错误,误将合法式子判断成格式错误
-
第一次作业
-
错误样例1:
++x^++2 -
错误原因:幂次后的指数前两个 ‘ + ’ 没有判断成WRONG FORMAT
-
错误样例2:
-- x^ + x -
错误原因:非法不可见空格\f, \v等没有判断成WRONG FORMAT
-
-
第二次作业
-
错误样例1:
+08*cos(x)^ 00* x*x*+6* x* sin(x)++ -3* sin(x)*cos(x)^ +9* sin(x)*3*cos(x)^ +93*-41 -
错误原因:乘号后加有符号数误判成WRONG FORMAT
-
错误样例2:
x + x * +1 -
错误原因:乘号后加有符号数误判成WRONG FORMAT,与样例1同质
-
错误样例3:
sin(x)* -
错误原因:没有识别末尾的
*或者+判断WRONG FORMAT
-
-
第三次作业
互测中没有被Hack,强测有两个同质Bug
-
错误样例:
sin(((x+x)*(cos(x)+cos(x))+(sin(x)+cos(x))*(sin(cos(x))))) -
错误原因:没有识别被嵌套的表达式因子括号前的
-,+误判成WRONG FORMAT
修复如下:
-

if (content.startsWith("(") && content.endsWith(")")) {
input = string.substring(1,string.length() - 1);
} else if (content.startsWith("-(") && content.endsWith(")")) { // 这是后面加的
input = string.substring(2,input.length() - 1);
coeff = BigInteger.ONE.negate();
} else if (content.startsWith("+(") && content.endsWith(")")) { // 也是后面加的
input = string.substring(2,input.length() - 1);
coeff = BigInteger.ONE;
}
Bug位置与设计结构之间的相关性
由上面的表格中不难看出,到了第三次作业后,由几个方法的复杂度,尤其是模块设计复杂度(iv(G))、圈复杂度(v(G))各项指标都很高。例如这几个方法:
| Method | ev(G) | iv(G) | v(G) |
|---|---|---|---|
| Item.Parse() | 6 | 8 | 9 |
| Item.cut() | 1 | 16 | 16 |
| MainClass.CheckValid(String) | 7 | 15 | 15 |
| Nested.JudgeFactor() | 14 | 15 | 25 |
| Nested.Nested(String) | 1 | 12 | 25 |
基本复杂度(ev(G))高意味着非结构化程度高,软件模块设计复杂度(iv(G))高意味模块耦合度高,圈复杂度大说明程序代码可能质量低且难于测试和维护,在这种情况下代码不易读和出现Bug是难以避免的。而我的第三次作业Bug恰恰出现在Nested类中。导致没有正确识别嵌套括号内部的一些符号。
说明程序还明显存在不完善的地方,今后应该更加注意“高内聚,低耦合”的思想来编程。
如何有效的发现别人的Bug?
读七人份的代码工作量太大,提出针对性的Bug对我来说不太现实,所以当然是瞎莽
但是这三次作业我分别成功Hack他人8次、11次、9次,基本保持在10次左右,具有可控性,Hack次数太多不仅是对别人不友好,而且实际上二十几次Hack很大概率会出现同质Bug。有效地Hack主要做以下几点:
构造完整测试集
包含但不限于以下方法:
-
功能正确性
-
嵌套多层能否正确拆分?
-
sin((x^3*cos(sin(x)^6)^2))
-
((-(x)*sin((x-x))))
-
-
表达式因子*表达式因子
-
-(x)*(--6)
-
(2*x^7*sin(x)^2)*(cos(x)*(sin(x)))
-
-
括号前带符号能否正确识别?
-
-(-sin(cos(x)))
-
-
表达式里若不含x自变量能否输出0?
-
2333*sin(-9)^233
-
-
-
鲁棒性
-
对所有格式错误的形式排列组合,放在同一个HackData.txt下,8个人的输出数据谁不是“WRONG FORMAT!”一目了然
-
压力测试,在允许的最大字符个数情况下尽可能多
-
非法不可见字符测试
-
空串测试
-
使用脚本进行测试
将装有一行一个测试数据的HackData.txt文件和当前要测试的Class文件放在同一个目录下,建立.sh文件,内容如下:
1 #! /bin/bash 2 i=1; 3 cat HackData.txt | while read line 4 do 5 echo "$i :" >> outSaber.txt # Print serial number 6 echo "$line" | java Exp >> outSaber.txt # Print result 7 let "i+=1" # i++ 8 done
其中“Exp”是Saber主程序所在类名,OutSaber.txt是这一组匿名代号为Saber的输出结果。
最后将七人的输出结果进行比对,有不同之处一定是有人出了Bug。
比对结果-Wolfram Alpha
在线计算,可以求导,积分,化简式子,点击这个传送门通往Wolfram Alpha
手机App也很好用呢!(iOS用户在Apple Store上花了18¥买的,大一的数分作业靠它摆渡)
下面是“一起来找茬”:左侧是化简了某同学的求导结果,右侧是正确的求导结果,发现系数和指数不一样了!

提高效率的小安利~
-
类图:IDEA的插件plantUML(还需要装Graphviz);更酷炫的StarUML
-
度量工具:IDEA的插件MetricsReloaded
-
装逼利器:IDEA的插件Power Mode II,一边敲代码还会出现特效,简直不要太爽
-
思维导图:Xmind
-
更多IDEA插件链接及其安装和使用,请戳这里
By Vanellope