腾讯算法大赛
本文参考于我协会前会长吴师兄的文档
腾讯社交广告高校算法大赛是面向高校大学生的算法大赛,作为腾讯核心的广告业务单元,腾讯社交广告通过对海量社交数据进行深入分析,构建多样广告场景,与8亿用户连接对话。在大数据、机器学习领域的持续创新投入,驱动社交广告生态发展。本次大赛旨在开放腾讯在社交和数字广告领域的真实数据,面向高校学生征集最智慧的算法解决方案。
详细的赛题见腾讯算法大赛, 记得也把 FAQ 看完, 里面也包含了许多重要信息
赛题比较难理解, 因为赛题属于广告学范畴, 如果实在难以理解赛题的可以先看看这篇文章, 看完再重新看一遍赛题就会通透许多转化率预估
官方已经不再关闭数据的下载通道了, 不过之前已经备份到了百度云, 在这里提供给大家官方数据下载
赛题要求
官方提供17-30天移动 APP 的广告、用户的转化情况,及相关上下文, 根据这些数据预测第31天指定用户和对应广告的转化率.
评估方式 (赛题中提供的计算公式)
通过Logarithmic Loss评估(越小越好),公式如下:
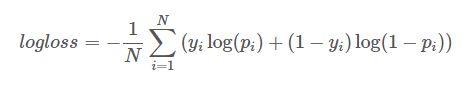
其中,
N是测试样本总数,
yi是二值变量,取值0或1,表示第i个样本的label,
pi为模型预测第i个样本 label为1的概率。
示例代码(Python语言实现):

项目目的
主要在于剖析和学习大赛中取得 第64 名大牛的分享, 对其代码进行理解和分析, 主要着重点在于特征工程。
机器学习的主要流程
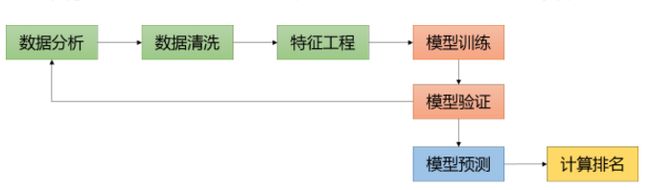
数据分析和清洗方法

关于数据分析,阅读FAQ可知:
App 的激活定义为用户下载后启动了该App,即发生激活行为。从用户点击广告到广告系统得知用户激活了App(如果有),通常会有较长的时间间隔,主要由以下两方面原因导致:
1) 用户可能在下载之后过了很久才启动App;
2) 用户启动App的行为需要广告主上报回传给广告系统,通常会有一定的延时。
这里回流时间表示了广告主把App激活数据上报给广告系统的时间,回流时间超过5天的数据会被系统忽略。
值得注意的是,本次竞赛的训练数据提供的截止第31天0点的广告日志,因此,对于最后几天的训练数据,某些label=0并不够准确,可能广告系统会在第31天之后得知label实际上为1。
即
某些app和用户的记录比较少
最后几天有部分数据不准确
对于这个问题, 这里采用了比较暴力的方法, 将最后几天这些可能会出现问题的数据删除
特征工程
特征工程即根据基本的数据提取出更多有用的数据, 然后结合基本特征来选取最终决定需要采用训练的特征数据, 往往特征工程决定了最终预测的效果
基本数据在官方已经提供了数据描述的表格, 这个一定要好好理解每一个字段的作用, 这里就不重复描述数据的字段了
在这里先强调一下,在做完特征工程之后, 我们得到了更多的特征, 但并不是每一个特征都对模型的训练有用, 故此我们需要对特征进行筛选 (不仅仅是单方面的取舍, 还需要根据重要的程度进行权重的分配)
通过数据分析,计划以下的特征作为最终的训练数据标签
1.基础特征:计数特征、转化率、比例特征等各种基本的特征(各种ID)
2.用户当天行为特征:基于当天数据统计的用户行为、app行为的特征
3.用户历史行为特征:word2vec 计算用户行为与历史行为的关联
1. 基础特征
基础特征即腾讯官方提供的数据,各种的ID标签,将一些没用的标签去掉即可,不需
要作过多的处理
2、3 用户行为特征的处理
用户行为特征的处理逻辑较为繁琐, 也是整个项目中最繁琐的操作, 逻辑比较难理
清,建议通过源码来理解