Redis-底层数据结构解析
1. 常用的五种数据类型
| 数据类型 | 结构存储的值 | 常用命令 | 使用场景 |
|---|---|---|---|
| String | 可以是字符串或数字 | GET/SET/DEL | 存储 json 字符串;主键自增 |
| Hash | 包含键值对的无序散列表 | HSET/HGET/HDEL | 存储对象类数据,如个人信息。相比string更加灵活 |
| List | 一个可进行头尾增删的双向链表 | RPUSH/RPOP/LRANGE/RINDEX | 消息队列;最新内容 |
| Set | 无序字符串 | SADD/SMENBERS/SISMEMBER | 共同好友:取交集 |
| Zset | 使用分值的概念有序保存元素 | ZADD/ZRANGE | 基于共同好友,加上排序功能——好友排序 |
2.redis中得几种数据结构底层
SDS(简单动态字符串)
Redis 中 SDS 数据结构的定义为:
struct sdshdr{
int len;
int free;
char buf[];
}
一个保存了字符串Redis的 SDS 示例图如下:
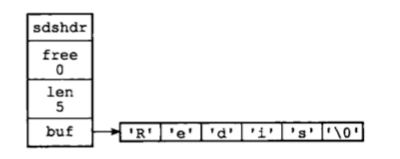
- len=5, 说明当前存储的字符串长度为 5.
- free=0, 说明这个结构体实例中,所有分配的空间长度已经被使用完毕。
- buf 属性是一个 char 类型的数组,保存了实际的字符串信息。
带有 free 空间的 SDS 示例:
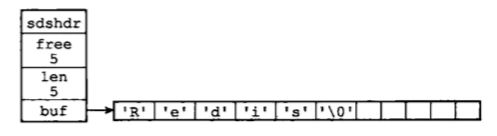
可以看到 len 属性和 buf 属性的已使用部分都和第一个示例相同,但是 free 属性为 5, 同时 buf 属性的除了保存了真实的字符串内容之外,还有 5 个空的未使用空间 ('0’结束字符不在长度中计算)。
SDS的空间分配策略
SDS 在进行修改之后,会对接下来可能需要的空间进行预分配。这也就是 free 属性存在的意义,记录当前预分配了多少空间。
空间预分配策略:
- 如果当前 SDS 的长度小于 1M, 那么分配等于已占用空间的未使用空间,即让 free 等于 len.
- 如果当前 SDS 的长度大于 1M, 那么分配 1M 的 free 空间。
惰性释放内存
- 当 SDS 进行了缩短操作,那么多余的空间不着急进行释放,暂时留着以备下次进行增长时使用。
- 对于空间不足的设备,SDS 也提供了对应的 API, 在需要的时候,会自己释放掉多余的未使用空间。
二进制安全
C 语言的字符串不是二进制安全的,因为它使用空间符’0’来判断一个字符串的结尾。也就是说,假如你的字符串是 abc\0aa\0 哈哈哈、0, 那么你就不能使用 C 语言的字符串,因为它识别到第一个空字符’0’的时候就结束识别了,它认为这次的字符串值是’abc0’.
SDS 判断字符串的长度时使用 len属性的,截取 字节数组 buf 中的前 len 个字符即可。因此,在 SDS 中,可以存储任意格式的二进制数据,也就是我们常说的,Redis 的字符串是二进制安全的。
intSet
intset(整数集合)是 Reids 用于保存整数值的集合抽象数据结构,可以保存 16,31,64 位的整数且保证不重复。
它的结构定义为:
typedef struct intset{
// 编码方法,指定当前存储的是 16 位,32 位,还是 64 位的整数
int32 encoding;
// 集合中的元素数量
int32 length;
// 保存元素的数组
int<T> contents;
}
- encoding 属性有三种取值,分别代表当前整数集合存储方式是用 16 位整数数组,32 位整数数组或者 64 位整数数组。整数集合内部封装了对 16 位,32 位,64 位整数的类型转换,使得整数集合可以灵活的避免类型错误,同时又可以尽量的节约内存,减少用大的数据类型装小的数据的内存浪费。
- length 属性保存了当前整数集合中有多少个整数。
- contents 是一个数组,具体是多少位整数的数组,取决 encoding 的值。
linkedList(双向链表)
链表节点的定义:
typedef struct listNode{
// 前置节点
struct listNode *prev;
// 后置节点
struct listNode *next;
// 节点的值
void *value;
}listNode
通过这个节点,我们就可以构造出来一个链表了。
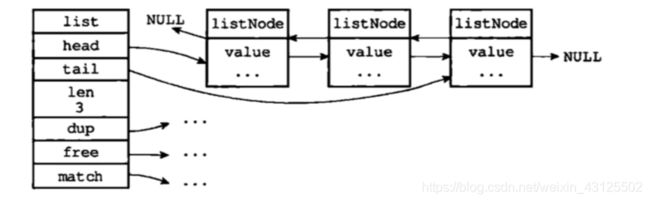
但是 Redis 为了更好的操作,封装了一个链表结构 list. 结构如下:
typedef struct list {
// 表头结点
listNode *head;
// 表尾节点
listNode *tail;
// 链表所包含的节点数量
unsigned long len;
// 其他函数
...
}list;
list 结构为链表提供了表头指针 head, 表尾指针 tail, 以及链表长度的计数器 len. 来方便的对链表进行一个双端的遍历,或者查看链表长度。一个linkedlist结构图:
zipList(压缩列表)
链表的前后指针是一个非常耗费内存的结构,因此在数据量小的时候,这一部分的空间尤其显得浪费。因此为了节省内存,压缩列表的核心思想就是在一块连续的内存中,模拟出一个列表的结构。 ziplist同样能够反向遍历。
压缩列表的定义为:
struct ziplist<T>{
// 整个压缩列表占用字节数
int32 zlbytes;
// 最后一个节点到压缩列表起始位置的偏移量,可以用来快速的定位到压缩列表中的最后一个元素
int32 zltail_offset;
// 压缩列表包含的元素个数
int16 zllength;
// 元素内容列表,用数组存储,内存上紧挨着
T[] entries;
// 压缩列表的结束标志位,值永远为 0xFF.
int8 zlend;
}

压缩列表的每一个节点的定义为:
struct entry{
// 前一个 entry 的长度
int<var> prevlous_entry_length;
// 编码方式
int<vat> encoding;
// 内容
optional bute[] content;
}
prevlous_entry_length 属性,就是为了反向遍历而记录的。想一下,首先拿到尾部节点的偏移量zltail_offset,找到最尾部的节点,然后调用prevlous_entry_length属性,就可以拿到前一个节点,然后不断向前遍历了。
zipList只适合数据量小的场景
ziplist 是连续存储的数据结构,内存是没有冗余的(前面的文章讲过的 SDS 中就有冗余空间), 也就是说,每一次新增节点,都需要进行内存申请,然后将如果当前内存连续块够用,那么将新节点添加,如果申请到的是另外一块连续内存空间,那么需要将所有的内容拷贝到新的地址。
也就是说,每一次新增节点,都需要内存分配,可能还需要进行内存拷贝。当 ziplist 中存储的值太多,内存拷贝将是一个很大的消耗。
也是因此,Redis 只在一些数据量小的场景下使用 ziplist.
quickList
quicklist 是 ziplist 和 linkedlist 的一个结合体。它的结构定义如下:
struct ziplist_compressed{
int32 size;
byte[] compressed_data;
}
struct quicklistNode {
quicklistNode* prev;
quicklistNode* next;
// 指向压缩列表
ziplist* zi;
// ziplist 的字节总数
int32 size;
// ziplist 的元素总数
int 16 count;
// 存储形式,是原生的字节数组,还是 LZF 压缩存储
int2 encoding;
}
struct quicklist{
// 头结点
quicklistNode* head;
// 尾节点
quicklistNode* tail;
// 元素总数
long count;
// ziplist 节点的个数
int nodes;
// LZF 算法压缩深度
int compressDepth;
}
从结构定义中可以看到,quicklist 的定义和 链表的很像,本质上也是一个双端的链表,只是把普通的节点换成了 quicklistNode, 在这个节点中,保存的不是一个简单的值,而是一个 ziplist.
优劣
纯粹的使用 Linkedlist, 也就是普通链表来存储数据有两个弊端:
每个节点都有自己的前后指针,指针所占用的内存有点多,太浪费了。每个节点单独的进行内存分配,当节点过多,造成的内存碎片太多了。影响内存管理的效率。因此,定义了 quicklist, 将 linkedlist 和 ziplist 结合起来,形成一个,将多个 ziplist 通过前后指针互相连接起来的结构,可以在一定程度上缓解上面说到的两个问题。
为了进一步节约内存,Reids 还可以对 ziplist 进行压缩存储,应用 LZF 算法压缩。
skipList
什么是跳表
redis中的跳表
字典
https://segmentfault.com/a/1190000021604679
3. 五种数据类型对应的底层数据结构
String
String的底层有三种情况:
- int:如果一个字符串对象,保存的值是一个整数值,并且这个整数值在 long 的范围内,那么 redis 用整数值来保存这个信息,并且将字符串编码设置为 int.
- raw:如果字符串对象保存的是一个字符串, 并且长度大于 32 个字节,它就会使用**SDS(简单动态字符串)**数据结构来保存这个字符串值,并且将字符串对象的编码设置为raw.
- embstr:如果字符串对象保存的是一个字符串, 但是长度小于 32 个字节,它就会使用embstr来保存了,embstr编码不是一个数据结构,而是对 SDS 的一个小优化,当使用 SDS 的时候,程序需要调用两次内存分配,来给 字符串对象 和 SDS 各自分配一块空间,而embstr只需要一次内存分配,因为他需要的空间很少,所以采用 连续的空间保存,即将 SDS 的值和 字符串对象的值放在一块连续的内存空间上。这样能在短字符串的时候提高一些效率。但是在 Redis 中,embstr编码的值其实是 只读的,只要发生修改,立刻将编码转换成 raw.
Hash
- ziplist:ziplist 编码下的哈希对象,使用了压缩列表作为底层实现数据结构,用两个连续的压缩列表节点来表示哈希对象中的一个键值对。实现方式类似于上面的有序集合的场景。键值对的键和值的长度都小于 64 字节,且 键值对个数小于 512使用该结构
- hashtable
List
- quickList:底层实现基本上就是将 双向链表和压缩列表进行了结合,用双向的指针将压缩列表进行连接,这样不仅避免了压缩列表存储大量元素的性能压力,同时避免了双向链表连接指针占用空间过多的问题。
Set
- intset:当集合中的所有元素都是整数,且元素的数量不大于 512 个的时候,使用 intset 编码。
- hashtable:当元素不符合全部为整数值且元素个数小于 512时,集合对象使用的编码方式为 hashtable.
Zset
- ziplist:每个集合的元素 (key-value), 使用两个紧挨着的压缩列表的节点来表示,第一个节点保存集合元素的成员 (member), 第二个节点保存集合元素的分支 (score)。在压缩列表的内部,集合元素按照分值从小到大进行排序。
元素数量少于 128 且 所有元素成员的长度小于 64 字节时使用该数据结构 - skiplist + 字典:使用skiplist按序保存元素及分值,使用dict来保存元素和分值的映射关系。
- 当我们只使用字典来实现,我们可以以 O(1) 的时间复杂度获取成员的分值,但是由于字典是无序的,当我们需要进行范围性操作的时候,需要对字典中的所有元素进行排序,这个时间复杂度至少需要 O(nlogn).
- 当我们只使用跳跃表来实现,我们可以在 O(logn) 的时间进行范围排序操作,但是如果要获取到某个元素的分值,时间复杂度也是 O(logn).
- 因此,将字典和跳跃表结合进行使用,可以在 O(1) 的时间复杂度下完成查询分值操作,而对一些范围操作,使用跳跃表可以达到 O(logn) 的时间复杂度。