FlinkSQL使用DDL语句创建kafka源表
在Flink1.9.x版本中,社区版本的 Flink 新增 了一个 SQL DDL 的新特性,但是暂时还不支持流式的一些概念的定义,比如说水位(watermark). 下面主要介绍一下怎么使用DDL创建kafak源表.
定义create table语句从kafka中读取数据
"""
|CREATE TABLE PERSON (
| name VARCHAR COMMENT '姓名',
| age VARCHAR COMMENT '年龄',
| city VARCHAR COMMENT '所在城市',
| address VARCHAR COMMENT '家庭住址',
| ts TIMESTAMP COMMENT '时间戳'
|)
|WITH (
| 'connector.type' = 'kafka', -- 使用 kafka connector
| 'connector.version' = '0.11', -- kafka 版本
| 'connector.topic' = 'xxx', -- kafka topic
| 'connector.startup-mode' = 'latest-offset', -- 从最新的 offset 开始读取
| 'connector.properties.0.key' = 'zookeeper.connect', -- 连接信息
| 'connector.properties.0.value' = 'xxx',
| 'connector.properties.1.key' = 'bootstrap.servers',
| 'connector.properties.1.value' = 'xxx',
| 'update-mode' = 'append',
| 'format.type' = 'json', -- 数据源格式为 json
| 'format.derive-schema' = 'true' -- 从 DDL schema 确定 json 解析规则
|)
如上面的 sql,基本语法是 create table () with ()
with 后面是一些基本的属性,比如 connector.type 描述了 从 kafka 中读取数据
connector.version 描述了 使用的是哪个版本的 kafka
connector.topic 描述了 从 哪个 topic 中读取数据
connector.startup-mode 描述了 从 哪个位置开始读取数据 等等。
可能有同学会觉得其中的 connector.properties.0.key 等参数比较奇怪,社区计划将在下一个版本中改进并简化 connector 的参数配置。
需要注意的是:
1,表的字段要区分大小写
2,字段里面不能有timestamp ,watermark等关键字
完整的代码如下
package flink.ddl
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.EnvironmentSettings
import org.apache.flink.table.api.scala._
import org.apache.flink.types.Row
/**
* @program: Flink1.9.0
* @description: ${description}
* @author: JasonLee
* @create: 2020-01-14 19:49
*/
object FlinkKafkaDDLDemo {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(3)
val settings = EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build()
val tEnv = StreamTableEnvironment.create(env, settings)
val createTable =
"""
|CREATE TABLE PERSON (
| name VARCHAR COMMENT '姓名',
| age VARCHAR COMMENT '年龄',
| city VARCHAR COMMENT '所在城市',
| address VARCHAR COMMENT '家庭住址',
| ts TIMESTAMP COMMENT '时间戳'
|)
|WITH (
| 'connector.type' = 'kafka', -- 使用 kafka connector
| 'connector.version' = '0.11', -- kafka 版本
| 'connector.topic' = 'xxx', -- kafka topic
| 'connector.startup-mode' = 'latest-offset', -- 从最新的 offset 开始读取
| 'connector.properties.0.key' = 'zookeeper.connect', -- 连接信息
| 'connector.properties.0.value' = 'xxx',
| 'connector.properties.1.key' = 'bootstrap.servers',
| 'connector.properties.1.value' = 'xxx',
| 'update-mode' = 'append',
| 'format.type' = 'json', -- 数据源格式为 json
| 'format.derive-schema' = 'true' -- 从 DDL schema 确定 json 解析规则
|)
""".stripMargin
tEnv.sqlUpdate(createTable)
val query =
"""
|SELECT name,COUNT(age) FROM PERSON GROUP BY name
""".stripMargin
val result = tEnv.sqlQuery(query)
result.toRetractStream[Row].print()
tEnv.execute("Flink SQL DDL")
}
}
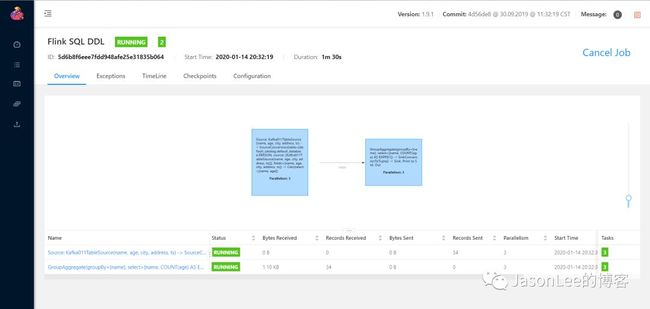
我们把上面的代码提交到集群,可以看到任务的DAG图,如下图所示:
然后我们向上面配置的topic写入数据,可以看下Flink的UI输出的结果:
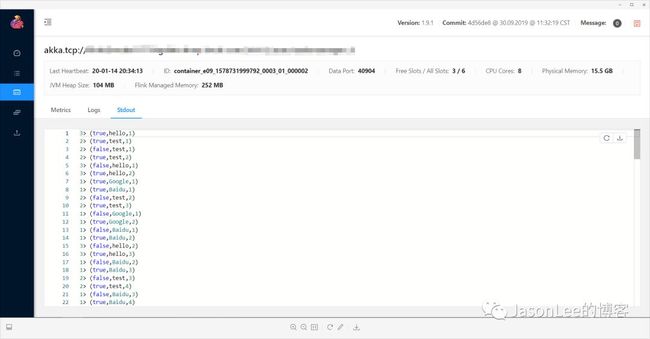
可以看到这是上面那个SQL打印的结果.也可以通过DDL直接把结果写入mysql库中,今天就主要介绍到这里,后面会带来更多相关的内容.
