八九、egg.js进阶
Debug
添加 npm scripts 到 package.json:
{
"scripts": {
"debug": "egg-bin debug"
}
}
egg-bin 会智能选择调试协议,在 8.x 之后版本使用 Inspector Protocol 协议,低版本使用 Legacy Protocol。
同时也支持自定义调试参数:
egg-bin debug --inpsect=9229
执行 debug 命令时,应用也是以 env: local 启动的,读取的配置是 config.default.js 和 config.local.js 合并的结果。
chrome浏览器调试窗口

调式步骤
- 打开
chrome-devtools://devtools/bundled/inspector.html?experiments=true&v8only=true&ws=127.0.0.1:9999/__ws_proxy__ - 选择sources
- 找到你需要调试的地方,打上断点
- 进行http访问
日志
日志对于 Web 开发的重要性毋庸置疑,它对于监控应用的运行状态、问题排查等都有非常重要的意义。
框架内置了强大的企业级日志支持,由 egg-logger 模块提供。
日志路径
所有日志文件默认都放在 ${appInfo.root}/logs/${appInfo.name} 路径下。
如果想自定义日志路径:
一般生产环境下才需要自定义日志
// config/config.${env}.js
exports.logger = {
dir: '/path/to/your/custom/log/dir',
};
日志分类
框架内置了几种日志,分别在不同的场景下使用:
- appLogger
${appInfo.name}-web.log,例如example-app-web.log,应用相关日志,供应用开发者使用的日志。我们在绝大数情况下都在使用它。 - coreLogger
egg-web.log框架内核、插件日志。 - errorLogger
common-error.log实际一般不会直接使用它,任何 logger 的.error()调用输出的日志都会重定向到这里,重点通过查看此日志定位异常。 - agentLogger
egg-agent.logagent 进程日志,框架和使用到 agent 进程执行任务的插件会打印一些日志到这里。
如果想自定义以上日志文件名称,可以在 config 文件中覆盖默认值:
// config/config.${env}.js
module.exports = appInfo => {
return {
logger: {
appLogName: `${appInfo.name}-web.log`,
coreLogName: 'egg-web.log',
agentLogName: 'egg-agent.log',
errorLogName: 'common-error.log',
},
};
};
日志级别
日志分为 NONE,DEBUG,INFO,WARN 和 ERROR 5 个级别。
日志打印到文件中的同时,为了方便开发,也会同时打印到终端中。
- Error 错误
- Warn 警告,比如vue没有加key
- Info 性能分析,这里一定是有用的信息
- Debug 打印一些随意的信息
- None 不要去打印
如何打印日志
如果我们在处理请求时需要打印日志,这时候使用 Context Logger,用于记录 Web 行为相关的日志。
ctx.logger.debug('debug info');
ctx.logger.info('info');
ctx.logger.warn('WARNNING!!!!');
如果我们想做一些应用级别的日志记录,如记录启动阶段的一些数据信息,可以通过 App Logger 来完成。
// app.js
module.exports = app => {
app.logger.debug('debug info');
app.logger.info('启动耗时 %d ms', Date.now() - start);
app.logger.warn('warning!');
app.logger.error(someErrorObj);
};
对于框架和插件开发者会使用到的 App Logger 还有 app.coreLogger。
// app.js
module.exports = app => {
app.coreLogger.info('启动耗时 %d ms', Date.now() - start);
};
在开发框架和插件时有时会需要在 Agent 进程运行代码,这时使用 agent.coreLogger。
// agent.js
module.exports = agent => {
agent.logger.debug('debug info');
agent.logger.info('启动耗时 %d ms', Date.now() - start);
agent.logger.warn('warning!');
agent.logger.error(someErrorObj);
};
文件日志级别
默认只会输出 INFO 及以上(WARN 和 ERROR)的日志到文件中。
可通过如下方式配置输出到文件日志的级别:
打印所有级别日志到文件中:
// config/config.${env}.js
exports.logger = {
level: 'DEBUG',
};
关闭所有打印到文件的日志:
// config/config.${env}.js
exports.logger = {
level: 'NONE',
};
日志切割
默认日志切割方式,在每日 00:00 按照 .log.YYYY-MM-DD 文件名进行切割。
我们也可以按照文件大小进行切割。例如,当文件超过 2G 时进行切割。
例如,我们需要把 egg-web.log 按照大小进行切割:
// config/config.${env}.js
const path = require('path');
module.exports = appInfo => {
return {
logrotator: {
filesRotateBySize: [
path.join(appInfo.root, 'logs', appInfo.name, 'egg-web.log'),
],
maxFileSize: 2 * 1024 * 1024 * 1024,
},
};
};
我们也可以选择按照小时进行切割,这和默认的按天切割非常类似,只是时间缩短到每小时。
// config/config.${env}.js
const path = require('path');
module.exports = appInfo => {
return {
logrotator: {
filesRotateByHour: [
path.join(appInfo.root, 'logs', appInfo.name, 'common-error.log'),
],
},
};
};
性能
通常 Web 访问是高频访问,每次打印日志都写磁盘会造成频繁磁盘 IO,为了提高性能,我们采用的文件日志写入策略是:日志同步写入内存,异步每隔一段时间(默认 1 秒)刷盘
多进程模型和进程间通信
我们知道 JavaScript 代码是运行在单线程上的,换句话说一个 Node.js 进程只能运行在一个 CPU 上。那么如果用 Node.js 来做 Web Server,就无法享受到多核运算的好处。作为企业级的解决方案,我们要解决的一个问题就是:
如何榨干服务器资源,利用上多核 CPU 的并发优势?
而 Node.js 官方提供的解决方案是 Cluster 模块
- 负责启动其他进程的叫做 Master 进程,他好比是个『包工头』,不做具体的工作,只负责启动其他进程。
- 其他被启动的叫 Worker 进程,顾名思义就是干活的『工人』。它们接收请求,对外提供服务。
const cluster = require('cluster');
const http = require('http');
const numCPUs = require('os').cpus().length;
if (cluster.isMaster) {
// Fork workers.
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on('exit', function(worker, code, signal) {
console.log('worker ' + worker.process.pid + ' died');
});
} else {
// Workers can share any TCP connection
// In this case it is an HTTP server
http.createServer(function(req, res) {
res.writeHead(200);
res.end("hello world\n");
}).listen(8000);
}
egg多进程模型
作为企业级的解决方案,要考虑的东西还有很多。
- Worker 进程异常退出以后该如何处理?
- 多个 Worker 进程之间如何共享资源?
- 多个 Worker 进程之间如何调度?
进程守护
健壮性(又叫鲁棒性)是企业级应用必须考虑的问题,除了程序本身代码质量要保证,框架层面也需要提供相应的『兜底』机制保证极端情况下应用的可用性。
一般来说,Node.js 进程退出可以分为两类:
未捕获异常
当代码抛出了异常没有被捕获到时,进程将会退出,此时 Node.js 提供了 process.on('uncaughtException', handler) 接口来捕获它,但是当一个 Worker 进程遇到 未捕获的异常 时,它已经处于一个不确定状态,此时我们应该让这个进程优雅退出:
- 关闭异常 Worker 进程所有的 TCP Server(将已有的连接快速断开,且不再接收新的连接),断开和 Master 的 IPC 通道,不再接受新的用户请求。
- Master 立刻 fork 一个新的 Worker 进程,保证在线的『工人』总数不变。
- 异常 Worker 等待一段时间,处理完已经接受的请求后退出。

OOM,系统异常
而当一个进程出现异常导致 crash 或者 OOM 被系统杀死时,不像未捕获异常发生时我们还有机会让进程继续执行,只能够让当前进程直接退出,Master 立刻 fork 一个新的 Worker。
- OOM
- 内存用尽
在框架里,我们采用 graceful 和 egg-cluster 两个模块配合实现上面的逻辑。这套方案已在阿里巴巴和蚂蚁金服的生产环境广泛部署,且经受过『双11』大促的考验,所以是相对稳定和靠谱的。
Agent机制
egg和nodejs原生多进程不同的地方
说到这里,Node.js 多进程方案貌似已经成型,这也是我们早期线上使用的方案。但后来我们发现有些工作其实不需要每个 Worker 都去做,如果都做,一来是浪费资源,更重要的是可能会导致多进程间资源访问冲突。举个例子:生产环境的日志文件我们一般会按照日期进行归档,在单进程模型下这再简单不过了:
- 每天凌晨 0 点,将当前日志文件按照日期进行重命名
- 销毁以前的文件句柄,并创建新的日志文件继续写入
试想如果现在是 4 个进程来做同样的事情,是不是就乱套了。所以,对于这一类后台运行的逻辑,我们希望将它们放到一个单独的进程上去执行,这个进程就叫 Agent Worker,简称 Agent。Agent 好比是 Master 给其他 Worker 请的一个『秘书』,它不对外提供服务,只给 App Worker 打工,专门处理一些公共事务。现在我们的多进程模型就变成下面这个样子了

那我们框架的启动时序如下:
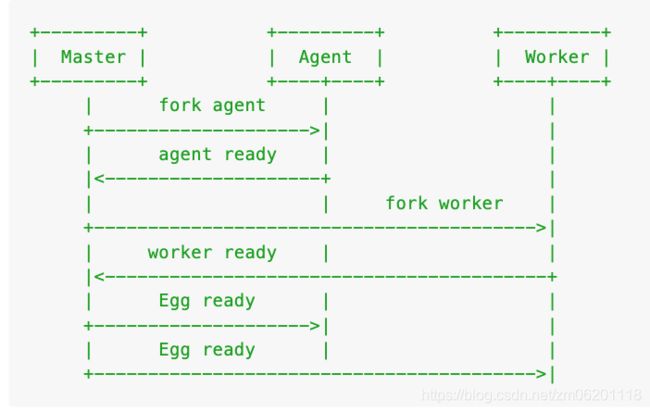
- Master 启动后先 fork Agent 进程
- Agent 初始化成功后,通过 IPC 通道通知 Master
- Master 再 fork 多个 App Worker
- App Worker 初始化成功,通知 Master
- 所有的进程初始化成功后,Master 通知 Agent 和 Worker 应用启动成功
另外,关于 Agent Worker 还有几点需要注意的是:
- 由于 App Worker 依赖于 Agent,所以必须等 Agent 初始化完成后才能 fork App Worker
- Agent 虽然是 App Worker 的『小秘』,但是业务相关的工作不应该放到 Agent 上去做,不然把她累垮了就不好了
- 由于 Agent 的特殊定位,我们应该保证它相对稳定。当它发生未捕获异常,框架不会像 App Worker 一样让他退出重启,而是记录异常日志、报警等待人工处理
Agent用法
你可以在应用或插件根目录下的 agent.js 中实现你自己的逻辑(和启动自定义 用法类似,只是入口参数是 agent 对象)
// agent.js
module.exports = agent => {
// 在这里写你的初始化逻辑
// 也可以通过 messenger 对象发送消息给 App Worker
// 但需要等待 App Worker 启动成功后才能发送,不然很可能丢失
agent.messenger.on('egg-ready', () => {
const data = { ... };
agent.messenger.sendToApp('xxx_action', data);
});
};
// app.js
module.exports = app => {
app.messenger.on('xxx_action', data => {
// ...
});
};
master VS agent VS worker
当一个应用启动时,会同时启动这三类进程。

master
在这个模型下,Master 进程承担了进程管理的工作(类似 pm2),不运行任何业务代码,我们只需要运行起一个 Master 进程它就会帮我们搞定所有的 Worker、Agent 进程的初始化以及重启等工作了。
Master 进程的稳定性是极高的,线上运行时我们只需要通过 egg-scripts 后台运行通过 egg.startCluster 启动的 Master 进程就可以了,不再需要使用 pm2 等进程守护模块。
agent
在大部分情况下,我们在写业务代码的时候完全不用考虑 Agent 进程的存在,但是当我们遇到一些场景,只想让代码运行在一个进程上的时候,Agent 进程就到了发挥作用的时候了。
由于 Agent 只有一个,而且会负责许多维持连接的脏活累活,因此它不能轻易挂掉和重启,所以 Agent 进程在监听到未捕获异常时不会退出,但是会打印出错误日志,我们需要对日志中的未捕获异常提高警惕。
- 应用场景
- 长连接
worker
Worker 进程负责处理真正的用户请求和定时任务的处理。而 Egg 的定时任务也提供了只让一个 Worker 进程运行的能力,所以能够通过定时任务解决的问题就不要放到 Agent 上执行。
Worker 运行的是业务代码,相对会比 Agent 和 Master 进程上运行的代码复杂度更高,稳定性也低一点,当 Worker 进程异常退出时,Master 进程会重启一个 Worker 进程。
进程间通信
虽然每个 Worker 进程是相对独立的,但是它们之间始终还是需要通讯的,叫进程间通讯(IPC)。下面是 Node.js 官方提供的一段示例代码
'use strict';
const cluster = require('cluster');
if (cluster.isMaster) {
const worker = cluster.fork();
worker.send('hi there');
worker.on('message', msg => {
console.log(`msg: ${msg} from worker#${worker.id}`);
});
} else if (cluster.isWorker) {
process.on('message', (msg) => {
process.send(msg);
});
}
细心的你可能已经发现 cluster 的 IPC 通道只存在于 Master 和 Worker/Agent 之间,Worker 与 Agent 进程互相间是没有的。那么 Worker 之间想通讯该怎么办呢?是的,通过 Master 来转发。

messenger 对象
-
app.messenger.broadcast(action, data):发送给所有的 agent / app 进程(包括自己) -
app.messenger.sendToApp(action, data): 发送给所有的 app 进程- 在 app 上调用该方法会发送给自己和其他的 app 进程
- 在 agent 上调用该方法会发送给所有的 app 进程
-
app.messenger.sendToAgent(action, data): 发送给 agent 进程- 在 app 上调用该方法会发送给 agent 进程
- 在 agent 上调用该方法会发送给 agent 自己
-
agent.messenger.sendRandom(action, data):- app 上没有该方法(现在 Egg 的实现是等同于 sentToAgent)
- agent 会随机发送消息给一个 app 进程(由 master 来控制发送给谁)
-
app.messenger.sendTo(pid, action, data): 发送给指定进程
// app.js
module.exports = app => {
// 注意,只有在 egg-ready 事件拿到之后才能发送消息
app.messenger.once('egg-ready', () => {
app.messenger.sendToAgent('agent-event', { foo: 'bar' });
app.messenger.sendToApp('app-event', { foo: 'bar' });
});
}
上面所有 app.messenger 上的方法都可以在 agent.messenger 上使用。
上面的示例中提到,需要等
egg-ready消息之后才能发送消息。只有在 Master 确认所有的 Agent 进程和 Worker 进程都已经成功启动(并 ready)之后,才会通过 messenger 发送egg-ready消息给所有的 Agent 和 Worker,告知一切准备就绪,IPC 通道可以开始使用了。
在 messenger 上监听对应的 action 事件,就可以收到其他进程发送来的信息了。
app.messenger.on(action, data => {
// process data
});
app.messenger.once(action, data => {
// process data
});
异常捕获( 错误处理 )
得益于框架支持的异步编程模型,错误完全可以用 try catch 来捕获。在编写应用代码时,所有地方都可以直接用 try catch 来捕获异常。
// app/service/test.js
try {
const res = await this.ctx.curl('http://eggjs.com/api/echo', { dataType: 'json' });
if (res.status !== 200) throw new Error('response status is not 200');
return res.data;
} catch (err) {
this.logger.error(err);
return {};
}
按照正常代码写法,所有的异常都可以用这个方式进行捕获并处理,但是一定要注意一些特殊的写法可能带来的问题。打一个不太正式的比方,我们的代码全部都在一个异步调用链上,所有的异步操作都通过 await 串接起来了,但是只要有一个地方跳出了异步调用链,异常就捕获不到了。
// app/controller/home.js
class HomeController extends Controller {
async buy () {
const request = {};
const config = await ctx.service.trade.buy(request);
// 下单后需要进行一次核对,且不阻塞当前请求
setImmediate(() => {
ctx.service.trade.check(request);
});
}
}
在这个场景中,如果 service.trade.check 方法中代码有问题,导致执行时抛出了异常,尽管框架会在最外层通过 try catch 统一捕获错误,但是由于 setImmediate 中的代码『跳出』了异步链,它里面的错误就无法被捕捉到了。因此在编写类似代码的时候一定要注意。
当然,框架也考虑到了这类场景,提供了 ctx.runInBackground(scope) 辅助方法,通过它又包装了一个异步链,所有在这个 scope 里面的错误都会统一捕获。
class HomeController extends Controller {
async buy () {
const request = {};
const config = await ctx.service.trade.buy(request);
// 下单后需要进行一次核对,且不阻塞当前请求
ctx.runInBackground(async () => {
// 这里面的异常都会统统被 Backgroud 捕获掉,并打印错误日志
await ctx.service.trade.check(request);
});
}
}
为了保证异常可追踪,必须保证所有抛出的异常都是 Error 类型,因为只有 Error 类型才会带上堆栈信息,定位到问题。
框架层统一异常处里
尽管框架提供了默认的统一异常处理机制(dev 会显示堆栈信息),但是应用开发中经常需要对异常时的响应做自定义,特别是在做一些接口开发的时候。框架自带的 onerror 插件支持自定义配置错误处理方法,可以覆盖默认的错误处理方法。
// config/config.default.js
module.exports = {
onerror: {
all(err, ctx) {
// 在此处定义针对所有响应类型的错误处理方法
// 注意,定义了 config.all 之后,其他错误处理方法不会再生效
ctx.body = 'error';
ctx.status = 500;
},
},
};
404
框架并不会将服务端返回的 404 状态当做异常来处理,但是框架提供了当响应为 404 且没有返回 body 时的默认响应。
- 当请求被框架判定为需要 JSON 格式的响应时,会返回一段 JSON:
{ "message": "Not Found" }
- 当请求被框架判定为需要 HTML 格式的响应时,会返回一段 HTML:
404 Not Found
框架支持通过配置,将默认的 HTML 请求的 404 响应重定向到指定的页面。
// config/config.default.js
module.exports = {
notfound: {
pageUrl: '/404.html',
},
};
自定义404响应
在一些场景下,我们需要自定义服务器 404 时的响应,和自定义异常处理一样,我们也只需要加入一个中间件即可对 404 做统一处理:
// app/middleware/notfound_handler.js
module.exports = () => {
return async function notFoundHandler(ctx, next) {
await next();
if (ctx.status === 404 && !ctx.body) {
if (ctx.acceptJSON) {
ctx.body = { error: 'Not Found' };
} else {
ctx.body = 'Page Not Found
';
}
}
};
};
在配置中引入中间件:
// config/config.default.js
module.exports = {
middleware: [ 'notfoundHandler' ],
};
多实例插件
许多插件的目的都是将一些已有的服务引入到框架中,如 egg-mysql, egg-oss。他们都需要在 app 上创建对应的实例。而在开发这一类的插件时,我们发现存在一些普遍性的问题:
- 在一个应用中同时使用同一个服务的不同实例(连接到两个不同的 MySQL 数据库)。
- 从其他服务获取配置后动态初始化连接(从配置中心获取到 MySQL 服务地址后再建立连接)。
如果让插件各自实现,可能会出现各种奇怪的配置方式和初始化方式,所以框架提供了 app.addSingleton(name, creator) 方法来统一这一类服务的创建。需要注意的是在使用 app.addSingleton(name, creator) 方法时,配置文件中一定要有 client 或者 clients 为 key 的配置作为传入 creator 函数 的 config。
插件写法
我们将 egg-mysql 的实现简化之后来看看如何编写此类插件:
// egg-mysql/app.js
module.exports = app => {
// 第一个参数 mysql 指定了挂载到 app 上的字段,我们可以通过 `app.mysql` 访问到 MySQL singleton 实例
// 第二个参数 createMysql 接受两个参数(config, app),并返回一个 MySQL 的实例
app.addSingleton('mysql', createMysql);
}
/**
* @param {Object} config 框架处理之后的配置项,如果应用配置了多个 MySQL 实例,会将每一个配置项分别传入并调用多次 createMysql
* @param {Application} app 当前的应用
* @return {Object} 返回创建的 MySQL 实例
*/
function createMysql(config, app) {
// 省略。。。通过config,创建一个mysql实例
return client;
}
初始化方法也支持 Async function,便于有些特殊的插件需要异步化获取一些配置文件。
单实例
- 在配置文件中声明 MySQL 的配置。
// config/config.default.js
module.exports = {
mysql: {
client: {
host: 'mysql.com',
port: '3306',
user: 'test_user',
password: 'test_password',
database: 'test',
},
},
};
- 直接通过
app.mysql访问数据库。
// app/controller/post.js
class PostController extends Controller {
async list() {
const posts = await this.app.mysql.query(sql, values);
},
}
多实例
- 同样需要在配置文件中声明 MySQL 的配置,不过和单实例时不同,配置项中需要有一个
clients字段,分别申明不同实例的配置,同时可以通过default字段来配置多个实例中共享的配置(如 host 和 port)。需要注意的是在这种情况下要用get方法指定相应的实例。(例如:使用app.mysql.get('db1').query(),而不是直接使用app.mysql.query()得到一个undefined)。
// config/config.default.js
exports.mysql = {
clients: {
// clientId, access the client instance by app.mysql.get('clientId')
db1: {
user: 'user1',
password: 'upassword1',
database: 'db1',
},
db2: {
user: 'user2',
password: 'upassword2',
database: 'db2',
},
},
// default configuration for all databases
default: {
host: 'mysql.com',
port: '3306',
},
};
- 通过
app.mysql.get('db1')来获取对应的实例并使用。
// app/controller/post.js
class PostController extends Controller {
async list() {
const posts = await this.app.mysql.get('db1').query(sql, values);
},
}
动态创建实例
// app.js
module.exports = app => {
app.beforeStart(async () => {
// 从配置中心获取 MySQL 的配置 { host, post, password, ... }
const mysqlConfig = await app.configCenter.fetch('mysql');
// 动态创建 MySQL 实例
app.database = await app.mysql.createInstanceAsync(mysqlConfig);
});
};
通过 app.database 来使用这个实例。
// app/controller/post.js
class PostController extends Controller {
async list() {
const posts = await this.app.database.query(sql, values);
},
}
注意,在动态创建实例的时候,框架也会读取配置中 default 字段内的配置项作为默认配置。
多进程增强版
在前面讲解 的多进程模型中, 其中适合使用 Agent 进程的有一类常见的场景:一些中间件客户端需要和服务器建立长连接,理论上一台服务器最好只建立一个长连接,但多进程模型会导致 n 倍(n = Worker 进程数)连接被创建。
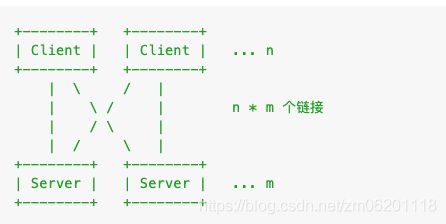
为了尽可能的复用长连接(因为它们对于服务端来说是非常宝贵的资源),我们会把它放到 Agent 进程里维护,然后通过 messenger 将数据传递给各个 Worker。这种做法是可行的,但是往往需要写大量代码去封装接口和实现数据的传递,非常麻烦。
另外,通过 messenger 传递数据效率是比较低的,因为它会通过 Master 来做中转;万一 IPC 通道出现问题还可能将 Master 进程搞挂。
我们提供一种新的模式来降低这类客户端封装的复杂度。通过建立 Agent 和 Worker 的 socket 直连跳过 Master 的中转。Agent 作为对外的门面维持多个 Worker 进程的共享连接。
核心思想
-
受到 Leader/Follower 模式的启发。
-
客户端会被区分为两种角色:
- Leader: 负责和远程服务端维持连接,对于同一类的客户端只有一个 Leader。
- Follower: 会将具体的操作委托给 Leader,常见的是订阅模型(让 Leader 和远程服务端交互,并等待其返回)。
-
如何确定谁是 Leader,谁是 Follower 呢?有两种模式:
- 自由竞争模式:客户端启动的时候通过本地端口的争夺来确定 Leader。例如:大家都尝试监听 7777 端口,最后只会有一个实例抢占到,那它就变成 Leader,其余的都是 Follower。
- 强制指定模式:框架指定某一个 Leader,其余的就是 Follower。
-
框架里面我们采用的是强制指定模式,Leader 只能在 Agent 里面创建,这也符合我们对 Agent 的定位
-
框架启动的时候 Master 会随机选择一个可用的端口作为 Cluster Client 监听的通讯端口,并将它通过参数传递给 Agent 和 App Worker。
-
Leader 和 Follower 之间通过 socket 直连(通过通讯端口),不再需要 Master 中转。
新的模式下,客户端的通信方式如下:

客户端接口类型抽象
抽象是类的描述
我们将客户端接口抽象为下面两大类,这也是对客户端接口的一个规范,对于符合规范的客户端,我们可以自动将其包装为 Leader/Follower 模式。
-
订阅、发布类(subscribe / publish):
subscribe(info, listener)接口包含两个参数,第一个是订阅的信息,第二个是订阅的回调函数。publish(info)接口包含一个参数,就是订阅的信息。
-
调用类 (invoke),支持 callback, promise 和 generator function 三种风格的接口,但是推荐使用 generator function。
客户端示例
const Base = require('sdk-base');
class Client extends Base {
constructor(options) {
super(options);
// 在初始化成功以后记得 ready
this.ready(true);
}
/**
* 订阅
*
* @param {Object} info - 订阅的信息(一个 JSON 对象,注意尽量不要包含 Function, Buffer, Date 这类属性)
* @param {Function} listener - 监听的回调函数,接收一个参数就是监听到的结果对象
*/
subscribe(info, listener) {
// ...
}
/**
* 发布
*
* @param {Object} info - 发布的信息,和上面 subscribe 的 info 类似
*/
publish(info) {
// ...
}
/**
* 获取数据 (invoke)
*
* @param {String} id - id
* @return {Object} result
*/
async getData(id) {
// ...
}
}
异常处理
- Leader 如果“死掉”会触发新一轮的端口争夺,争夺到端口的那个实例被推选为新的 Leader。
- 为保证 Leader 和 Follower 之间的通道健康,需要引入定时心跳检查机制,如果 Follower 在固定时间内没有发送心跳包,那么 Leader 会将 Follower 主动断开,从而触发 Follower 的重新初始化。
具体使用方法
下面我用一个简单的例子,介绍在框架里面如何让一个客户端支持 Leader/Follower 模式:
- 第一步,我们的客户端最好是符合上面提到过的接口约定,例如:
// registry_client.js 就是进行socket的基础类
const URL = require('url');
const Base = require('sdk-base');
class RegistryClient extends Base {
constructor(options) {
super({
// 指定异步启动的方法
initMethod: 'init',
});
this._options = options;
this._registered = new Map();
}
/**
* 启动逻辑
*/
async init() {
this.ready(true);
}
/**
* 获取配置
* @param {String} dataId - the dataId
* @return {Object} 配置
*/
async getConfig(dataId) {
return this._registered.get(dataId);
}
/**
* 订阅
* @param {Object} reg
* - {String} dataId - the dataId
* @param {Function} listener - the listener
*/
subscribe(reg, listener) {
const key = reg.dataId; // 时间名称
this.on(key, listener);
const data = this._registered.get(key);
if (data) {
process.nextTick(() => listener(data));
}
}
/**
* 发布
* @param {Object} reg
* - {String} dataId - the dataId
* - {String} publishData - the publish data
*/
publish(reg) {
const key = reg.dataId;
let changed = false;
if (this._registered.has(key)) {
const arr = this._registered.get(key);
if (arr.indexOf(reg.publishData) === -1) {
changed = true;
arr.push(reg.publishData);
}
} else {
changed = true;
this._registered.set(key, [reg.publishData]);
}
if (changed) {
this.emit(key, this._registered.get(key).map(url => URL.parse(url, true)));
}
}
}
module.exports = RegistryClient;
- 第二步,使用
agent.cluster接口对RegistryClient进行封装:
// agent.js
const RegistryClient = require('registry_client');
module.exports = agent => {
// 对 RegistryClient 进行封装和实例化
agent.registryClient = agent.cluster(RegistryClient)
// create 方法的参数就是 RegistryClient 构造函数的参数
.create({});
agent.beforeStart(async () => {
await agent.registryClient.ready();
agent.coreLogger.info('registry client is ready');
});
};
- 第三步,使用
app.cluster接口对RegistryClient进行封装:
const RegistryClient = require('registry_client');
module.exports = app => {
app.registryClient = app.cluster(RegistryClient).create({});
app.beforeStart(async () => {
await app.registryClient.ready();
app.coreLogger.info('registry client is ready');
// 调用 subscribe 进行订阅
app.registryClient.subscribe({
dataId: 'demo.DemoService',
}, val => {
// ...
});
// 调用 publish 发布数据
app.registryClient.publish({
dataId: 'demo.DemoService',
publishData: 'xxx',
});
// 调用 getConfig 接口
const res = await app.registryClient.getConfig('demo.DemoService');
console.log(res);
});
};
最后推荐一个 js常用的utils合集,帮我点个star吧~
- github
- 文档