seq2seq模型案例分析
1 seq2seq模型简介
seq2seq 模型是一种基于【 Encoder-Decoder】(编码器-解码器)框架的神经网络模型,广泛应用于自然语言翻译、人机对话等领域。目前,【seq2seq+attention】(注意力机制)已被学者拓展到各个领域。seq2seq于2014年被提出,注意力机制于2015年被提出,两者于2017年进入疯狂融合和拓展阶段。
1.1 seq2seq原理
通常,编码器和解码器可以是一层或多层 RNN、LSTM、GRU 等神经网络。为方便讲述原理,本文以 RNN 为例。seq2seq模型的输入和输出长度可以不一样。如图,Encoder 通过编码输入序列获得语义编码 C,Decoder 通过解码 C 获得输出序列。
 seq2seq网络结构图
seq2seq网络结构图
Encoder

Decoder
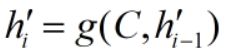
说明:xi、hi、C、h'i 都是列向量
1.2 seq2seq+attention原理
普通的 seq2seq 模型中,Decoder 每步的输入都是相同的语义编码 C,没有针对性的学习,导致解码效果不佳。添加注意力机制后,使得每步输入的语义编码不一样,捕获的信息更有针对性,解码效果更佳。
 seq2seq+attention网络结构图
seq2seq+attention网络结构图
Encoder
Decoder
![]()

(1)标准 attention
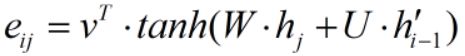
其中 ,v、W、U 都是待学习参数,v 为列向量,W、U 为矩阵
(2)attention 扩展
扩展的 attention 机制有3种方法,如下。其中,v、W 都是待学习参数,v 为列向量,W为矩阵。相较于标准的 attention,待学习的参数明显减少了些。

说明:xi、hi、Ci、h'i、wi 、ei 都是列向量,h 是矩阵
2 安装seq2seq
-
下载【https://github.com/farizrahman4u/recurrentshop】
,解压,通过cmd进入文件,输入 python setup.py install -
下载【https://github.com/farizrahman4u/seq2seq】
,解压,通过cmd进入文件,输入 python setup.py install -
重启编译器
若下载比较慢,可以先通过【码云】导入,再在码云上下载,如下:

本文以MNIST手写数字分类为例,讲解 seq2seq 模型和 AtttionSeq2seq 模型的实现。关于MNIST数据集的说明,见使用TensorFlow实现MNIST数据集分类。
笔者工作空间如下:

代码资源见-->seq2seq模型和基于注意力机制的seq2seq模型
3 SimpleSeq2Seq
SimpleSeq2Seq(input_length, input_dim, hidden_dim, output_length, output_dim, depth=1)- input_length:输入序列长度
- input_dim:输入序列维度
- output_length:输出序列长度
- output_dim:输出序列维度
- depth:Encoder 和 Decoder 的深度,取值可以为整数或元组。如 depth=3,表示 Encoder 和 Decoder 都有 3 层;depth=(3, 4) 表示 Encoder 有3层和 Decoder 有4层
SimpleSeq2Seq.py
from tensorflow.examples.tutorials.mnist import input_data
from seq2seq.models import SimpleSeq2Seq
from keras.models import Sequential
from keras.layers import Dense,Flatten
#载入数据
def read_data(path):
mnist=input_data.read_data_sets(path,one_hot=True)
train_x,train_y=mnist.train.images.reshape(-1,28,28),mnist.train.labels,
valid_x,valid_y=mnist.validation.images.reshape(-1,28,28),mnist.validation.labels,
test_x,test_y=mnist.test.images.reshape(-1,28,28),mnist.test.labels
return train_x,train_y,valid_x,valid_y,test_x,test_y
#SimpleSeq2Seq模型
def seq2Seq(train_x,train_y,valid_x,valid_y,test_x,test_y):
#创建模型
model=Sequential()
seq=SimpleSeq2Seq(input_dim=28,hidden_dim=32,output_length=10,output_dim=10)
model.add(seq)
model.add(Flatten()) #扁平化
model.add(Dense(10,activation='softmax'))
#查看网络结构
model.summary()
#编译模型
model.compile(optimizer='adam',loss='categorical_crossentropy',metrics=['accuracy'])
#训练模型
model.fit(train_x,train_y,batch_size=500,nb_epoch=25,verbose=2,validation_data=(valid_x,valid_y))
#评估模型
pre=model.evaluate(test_x,test_y,batch_size=500,verbose=2)
print('test_loss:',pre[0],'- test_acc:',pre[1])
train_x,train_y,valid_x,valid_y,test_x,test_y=read_data('MNIST_data')
seq2Seq(train_x,train_y,valid_x,valid_y,test_x,test_y)网络各层输出尺寸:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
model_14 (Model) (None, 10, 10) 10368
_________________________________________________________________
flatten_1 (Flatten) (None, 100) 0
_________________________________________________________________
dense_23 (Dense) (None, 10) 1010
=================================================================
Total params: 11,378
Trainable params: 11,378
Non-trainable params: 0网络训练结果:
Epoch 23/25
- 17s - loss: 0.1521 - acc: 0.9563 - val_loss: 0.1400 - val_acc: 0.9598
Epoch 24/25
- 17s - loss: 0.1545 - acc: 0.9553 - val_loss: 0.1541 - val_acc: 0.9536
Epoch 25/25
- 17s - loss: 0.1414 - acc: 0.9594 - val_loss: 0.1357 - val_acc: 0.9624
test_loss: 0.14208583533763885 - test_acc: 0.95679999589920044 AttentionSeq2Seq
AttentionSeq2Seq(input_length, input_dim, hidden_dim, output_length, output_dim, depth=1)- input_length:输入序列长度
- input_dim:输入序列维度
- output_length:输出序列长度
- output_dim:输出序列维度
- depth:Encoder 和 Decoder 的深度,取值可以为整数或元组。如 depth=3,表示 Encoder 和 Decoder 都有 3 层;depth=(3, 4) 表示 Encoder 有3层和 Decoder 有4层
AttentionSeq2Seq.py
from tensorflow.examples.tutorials.mnist import input_data
from seq2seq.models import AttentionSeq2Seq
from keras.models import Sequential
from keras.layers import Dense,Flatten
#载入数据
def read_data(path):
mnist=input_data.read_data_sets(path,one_hot=True)
train_x,train_y=mnist.train.images.reshape(-1,28,28),mnist.train.labels,
valid_x,valid_y=mnist.validation.images.reshape(-1,28,28),mnist.validation.labels,
test_x,test_y=mnist.test.images.reshape(-1,28,28),mnist.test.labels
return train_x,train_y,valid_x,valid_y,test_x,test_y
#AttentionSeq2Seq模型
def seq2Seq(train_x,train_y,valid_x,valid_y,test_x,test_y):
#创建模型
model=Sequential()
seq=AttentionSeq2Seq(input_length=28,input_dim=28,hidden_dim=32,output_length=10,output_dim=10)
model.add(seq)
model.add(Flatten()) #扁平化
model.add(Dense(10,activation='softmax'))
#查看网络结构
model.summary()
#编译模型
model.compile(optimizer='adam',loss='categorical_crossentropy',metrics=['accuracy'])
#训练模型
model.fit(train_x,train_y,batch_size=500,nb_epoch=25,verbose=2,validation_data=(valid_x,valid_y))
#评估模型
pre=model.evaluate(test_x,test_y,batch_size=500,verbose=2)
print('test_loss:',pre[0],'- test_acc:',pre[1])
train_x,train_y,valid_x,valid_y,test_x,test_y=read_data('MNIST_data')
seq2Seq(train_x,train_y,valid_x,valid_y,test_x,test_y)网络各层输出尺寸:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
model_102 (Model) (None, 10, 10) 24459
_________________________________________________________________
flatten_6 (Flatten) (None, 100) 0
_________________________________________________________________
dense_176 (Dense) (None, 10) 1010
=================================================================
Total params: 25,469
Trainable params: 25,469
Non-trainable params: 0网络训练结果:
Epoch 23/25
- 36s - loss: 0.0533 - acc: 0.9835 - val_loss: 0.0719 - val_acc: 0.9794
Epoch 24/25
- 37s - loss: 0.0511 - acc: 0.9843 - val_loss: 0.0689 - val_acc: 0.9800
Epoch 25/25
- 37s - loss: 0.0473 - acc: 0.9860 - val_loss: 0.0700 - val_acc: 0.9802
test_loss: 0.06055343023035675 - test_acc: 0.9825000047683716SimpleSeq2Seq 模型和 AttentionSeq2Seq 模型的预测精度分别为 0.9568、0.9825,说明添加注意力机制后,预测精度有了明显的提示。