python学习的第二天
1.turtle的简单实用
-import turtle as t(起别名为t)
# Python标准库中的GUI界面 (turtle)
# turtle的简单使用
# 导入turtle as 是给起一个别名
import turtle as t
# 设置画笔的大小 10px
t.pensize(10)
#设置画笔颜色为黄色
t.color('yellow')
# 绘制 NEUSOFT
# 水平左移
# 抬笔
t.penup()
t.goto(-260, 0)
t.pd()
# 绘制 N
t.left(90)
t.forward(80)
t.right(145)
# 简写
t.fd(100)
t.lt(145)
t.fd(80)
# 绘制 O
t.penup()
t.goto(200, 40)
t.pd()
t.circle(30, 180)
# 让gui界面一直显示, 所有执行的代码要写在此函数之前
t.done()
2.python常用数据类型
2.1字符串
# 字符串
# 定义形式 '' ""
# 切片 对序列截取一部分的操作,适用于列表
# name = 'abcdefg'
# # name[1]
# # [起始位置:终止位置:步长] 左闭右开
# print(name[1:4])
# # a c e g
# print(name[0:7:2])
# # 全切片的时候可以省略初始和终止位置
# print(name[::2])
# 常用方法
# 去两端空格
# name = ' abcdefg '
# # 查看序列内元素的个数 len()
# print(len(name))
# name = name.strip()
# print('去空格之后', len(name))
# 替换
# price = '$999'
# price = price.replace('$','')
# print(price)
# # 列表变成字符串的方法 join
# li = ['a', 'b', 'c', 'd']
# a = '_'.join(li)
# print(a)
# print(type(a))
# 数字
2.2列表
# 列表: 与c语言中的数组很相似, 只不过可以存储不同类型的数据
# 优点:灵活 ,缺点: 效率低
# 定义方式 []
hero_name = ['鲁班七号', '安琪拉', '李白', '刘备']
# 输出
# print(hero_name)
# 遍历
# for hero in hero_name:
# print(hero)
# 常见操作
# 1.列表的访问
# 列表名[索引]
print(hero_name[2])
# 2.添加 append
hero_name.append('后羿')
print('添加后的列表', hero_name)
# 3.修改
hero_name[1] = 1000
print('修改后的列表',hero_name)
# 4.删除
del hero_name[1]
print('删除后的列表',hero_name)
2.3元组
# 元组 tuple 元组和列表很像只不过元组不可以修改
# 定义 ()
# a = ('zhangsan', 'lisi', 'wangwu',1000)
# print(a)
# print(type(a))
#
# # 访问
# print(a[1])
# # # 修改
# # a[3] = 'zhaoliu'
#
# # 关于元组需要注意的是 只有一个元素的元组
# b = ('lisi',) #是不是元组
# c = (1000,) #是不是元组
# print(type(b))
# print(type(c))
2.4字典
# 字典 dict java hashmap
# key-value数据结构
# 定义形式 {}
info = {'name':'李四', 'age':34, 'addr':'重庆市渝北区'}
print(len(info))
print(info)
# 1.字典的访问
print(info['name'])
# 2.修改
info['addr'] = '北京市朝阳区'
print('修改后字典',info)
# 3.增加
info['sex'] = 'female'
print('增加后字典',info)
# 获取字典中所有的键
print(info.keys())
# # 获取字典中所有的z值
print(info.values())
# 获取字典中所有的key-value
print(info.items())
d = [('name', '李四'), ('age', 34), ('addr', '北京市朝阳区'), ('sex', 'female')]
d1 = dict(d)
print(d1)
# 遍历字典
for k, v in info.items():
print(k, v)
2.5集合
# 集合
# 无序,不重复
set1 = {'zhangsan', 'lisi', 222}
#
print(type(set1))
# 遍历
for x in set1:
print(x)
3.掌握python常用数据类型和语法
# 列表的排序
# li = []
# for i in range(10):
# li.append(i)
# print(li)
# from random import shuffle
# shuffle(li)
# print('随机打乱的列表', li)
# li.sort(reverse=True)
# print('排序后的列表', li)
stu_info = [
{"name":'zhangsan', "age":18},
{"name":'lisi', "age":30},
{"name":'wangwu', "age":99},
{"name":'tiaqi', "age":3},
]
print('排序前', stu_info)
# def 函数名(参数):
# 函数体
def sort_by_age(x):
return x['age']
# key= 函数名 --- 按照什么进行排序
# 根据年龄大小进行正序排序
stu_info.sort(key=sort_by_age, reverse=True)
print('排序后', stu_info)
# 练习
name_info_list = [
('张三',4500),
('李四',9900),
('王五',2000),
('赵六',5500),
]
4.本地文件读取
1.python中使用open内置函数进行文件读取
f = open(file='./novel/threekingdom.txt', mode='r', encoding='utf-8')
data = f.read()
f.close()
print(data)
2.with as 上下文管理器 不用手动关闭流
with open(file='./novel/threekingdom.txt', mode='r',encoding='utf-8') as f1:
data1 = f1.read()
print(data1)
3.写入文件流
# eg1:
txt = 'i like python'
with open('python.txt', 'w', encoding='utf-8') as f2:
f2.write(txt)
# eg2:
text = """
Title
重庆师范欢迎你
"""
print(text)
with open('chongqingshifan.html', 'w', encoding='utf-8') as f3:
f3.write(text)
python中使用open内置函数进行文件读取
5.中文分词和绘制词云
使用Python做中文分词和绘制词云
4.1中文分词 jieba
- 关于安装jieba分词库
指定国内镜像安装
在用户目录下新建pip文件夹
新建pip.ini文件
添加
"""
[global]
index-url = http://mirrors.aliyun.com/pypi/simple/
[install]
trusted-host=mirrors.aliyun.com
"""
pip install jieba - 关于应用
①导入jieba
import jieba
seg = "我来到北京清华大学"
② 三种分词形式
a.精确模式
seg_list = jieba.lcut(seg)
print(seg_list)
b.全模式
seg_list1 = jieba.lcut(seg, cut_all=True)
print(seg_list1)
c.搜索引擎模式
seg_list2 = jieba.lcut_for_search(seg)
print(seg_list2)
d.三国演义分词
import jieba
# 读取小说
with open(file='./novel/threekingdom.txt', mode='r',encoding='utf-8') as fs:
words = fs.read()
print('原字数:', len(words))
words_list = jieba.lcut(words)
print('分词后字数:', len(words_list))
print(words_list)
4.2绘制词云wordcloud
①老人与海
from wordcloud import WordCloud
import jieba
import imageio
# 绘制词云
text = 'He was an old man who fished alone in a skiff in the Gulf Stream and he had gone eighty-four days now without taking a fish. In the first forty days a boy had been with him. But after forty days without a fish the boy’s parents had told him that the old man was now definitely and finally salao, which is the worst form of unlucky, and the boy had gone at their orders in another boat which caught three good fish the first week. It made the boy sad to see the old man come in each day with his skiff empty and he always went down to help him carry either the coiled lines or the gaff and harpoon and the sail that was furled around the mast. The sail was patched with flour sacks and, furled, it looked like the flag of permanent defeat.'
wc = WordCloud().generate(text)
wc.to_file('老人与海.png')
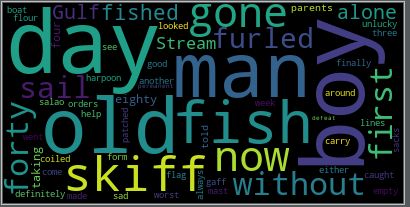
老人与海词云
②三国演义
# 三国演义小说分词
mask = imageio.imread('./china.jpg')
with open('./novel/threekingdom.txt', 'r', encoding='utf-8') as f:
words = f.read()
words_list = jieba.lcut(words)
print(words_list)
novel_words = " ".join(words_list)
print(novel_words)
wc = WordCloud(
font_path='msyh.ttc',
background_color='white',
width=800,
height=600,
mask=mask
).generate(novel_words)
wc.to_file('三国词云.png')

三国演义词云