Actional-Structural Graph Convolutional Networks for Skeleton-based Action Recognition(CVPR2019)
Introduction
过去方法的最大问题:
1.based on fixed skeleton among joints.
2.only capture local physical dependencise among joints
本篇文章的几个突出点:
1.introduce an encoder-decoder structure to capture action-specific latene dependencies named actional links
利用actional links 去捕捉任何结点之间的潜在关系
2.extend the existing skeleton graphs to represent higherorder dependencies named structural links
利用 structural links 去捕捉一些 high order features
3.combing above to form a basic building block
paper follow 了ST-GCN的工作,解决了以下ST-GCN的缺点:
- extracts the features of joints directly connected via bones but ignore the distant joints which may cove key patterns
- hierarchical GCNs to aggregate wider-range features but node features may be weaken during long diffusion (朴素GCN对于长距离的结点的信息的聚合效果很差)
2. Actional-Strcutural GCN

2.1.Defined generalized graph
Actional-structural graph is defined as G g ( V , E g ) G_g(V,E_g) Gg(V,Eg),where V V V is the original set of joints and E g E_g Egis the set of generalized links 。(V是谷歌的骨骼结点组成的集合,而 E g E_g Eg分为两类:1.S-links,2.A-links。其实就是有两个显示权重的邻接矩阵)
2.2 Actional Links (A-links)
思路想法:在人做一个动作的时候,我们的动作并不一定仅仅是一些邻近结点的合作,很可能是一些在物理结构上没有联系的关节结点的互动。比如拍手,我们的两只手的关节结点在物理上并没有邻接,但是针对拍手这个动作而言,两只手的关联性是非常高的。而为了捕捉到这样的Non-local的联系,我们就引入了Actional links,去通过数据自动去发现一些潜在的有联系的节点。
训练A-links的模块称为:A trainable A-link inference module (AIM),其中主要包括两个部分:encoder 和decoder。

Encoder
作用:用于学习评估任意节点与其他结点之间的联系重要性程度。作为A-Links 的状态矩阵 A ∈ R n ∗ n ∗ C A\in R^{n*n*C} A∈Rn∗n∗C,公式简写为:
A = e n c o d e ( X ) ∈ [ 0 , 1 ] n ∗ n ∗ C A=encode(X)\in[0,1]^{n*n*C} A=encode(X)∈[0,1]n∗n∗C
其中C表示A-links的类型数。Each element A i , j , c A_{i,j,c} Ai,j,c denotes the probability that the i , j i,j i,j-th joints are connected with the c-th type.
encoder步骤:
1.求出任意节点之间的联系特征(link features)。
2.将结点之间的这种联系特征转化为两者连接关联性的可能(link probabilities)
Details:
1.求link features:
对于 x i = v e c ( X i , : , : ) ∈ R d T x_i=vec(X_{i,:,:})\in R^{dT} xi=vec(Xi,:,:)∈RdT 是 i i i个节点所有T帧的结点特征,我们将节点初始特征作为该encoder的初始输入,即 P i ( 0 ) = x i P_i^{(0)}=x_i Pi(0)=xi。为了获得更高阶的link features,我们试图迭代 k k k次,则在迭代 k k k次后我们的传播过程如下:
l i n k f e a t u r e s : Q i , j ( k + 1 ) = f e ( k ) ( f v ( k ) P i ( k ) ⊕ ( f v ( k ) P j ( k ) ) ) link features: Q_{i,j}^{(k+1)}=f_e^{(k)}(f_v^{(k)}P_i^{(k)}\oplus(f_v^{(k)}P_j^{(k)})) linkfeatures:Qi,j(k+1)=fe(k)(fv(k)Pi(k)⊕(fv(k)Pj(k)))
j o i n t f e a t u r e s : P i ( k + 1 ) = F ( Q i , : ( k + 1 ) ⊕ P i ( k ) ) joint features: P_i^{(k+1)}=F(Q_{i,:}^{(k+1)} \oplus P_i^{(k)}) jointfeatures:Pi(k+1)=F(Qi,:(k+1)⊕Pi(k))
其中 f f f均为MLP, ⊕ \oplus ⊕是向量的拼接, F F F是一个aggregate link features 得到joint features 的操作,例如averaging ,max 等
2.link probabilities
在进行了 K K K次传播后,利用以下公式输出节点与节点之间联系的紧密程度(link probabilities)
A i , j , : = s o f t m a x ( Q i , j ( K ) + r τ ) ∈ R C A_{i,j,:}=softmax(\frac{Q_{i,j}^{(K)}+r}{\tau}) \in R^C Ai,j,:=softmax(τQi,j(K)+r)∈RC
其中 r r r是一个随机向量,服从Gumbel(0,1) 分布; τ \tau τ控制了 A i , j , : A_{i,j,:} Ai,j,: 的离散化程度(discretization).这里我们设置 τ = 0.5 \tau=0.5 τ=0.5。
Decoder
这里主要针对的是:我们利用前T 帧的结点features以及A(link probabilities)去预测t+1帧的节点位置:
X t + 1 = d e c o d e ( X t , . . . , X 1 , A ) ∈ R n ∗ 3 X_{t+1}=decode(X_t,...,X_1,A) \in R^{n*3} Xt+1=decode(Xt,...,X1,A)∈Rn∗3
decoder 步骤:
1.提取基于A_links的节点特征(joint features)
2.利用这些来预测未来的节点
details:

与上面一样, f ( ∗ ) f(*) f(∗)都是MLPs.
-
step(a)
Q i , j t Q_{i,j}^t Qi,jt代表了节点 i , j i,j i,j之间在t帧时的联系程度
-
step(b)
aggregates i i i节点与其他结点的 Q i , j t Q_{i,j}^t Qi,jt,并和 x i t x_i^t xit进行拼接,得到 i i i结点的joint features P i t P_i^t Pit
-
step©
利用GRU对时序上的结点进行预测,其中 S i t + 1 S_i^{t+1} Sit+1代表在t+1的隐藏状态
-
step(d)
预测 the mean of future joint positions.
Note:我们让joint position x i t + 1 ∈ R 3 x_i^{t+1} \in R^3 xit+1∈R3 ,满足Gaussian 分布,即 x i t + 1 N ( u i t + 1 , σ 2 I ) x_i^{t+1}~N(u_i^{t+1},{\sigma}^2I) xit+1 N(uit+1,σ2I).
我们就可以定义一个loss function 去预训练
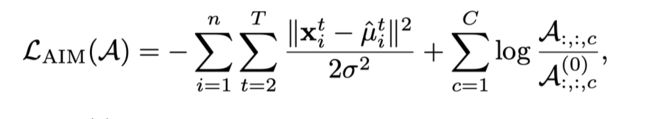
Analysis:
依据实验分析,发现了A越是稀疏对于模型的能力提升越大。原因:因为太多的捕获没用的边依赖导致了动作识别学习时的困难。
依据以上softmax公式后得到的link probabilities ,有 ∑ c = 1 C A i , j , c = 1 \sum_{c=1}^C{A_{i,j,c}}=1 ∑c=1CAi,j,c=1,即我们将i与j的关系联系分配到了C种关系连接类型上。
显然,如果link types©数量很少的话很难到达有效的稀疏性,为了能实现,这里我们引入一种边叫 ghost link ,这种边类型没有实际意义,仅仅用于占用 large probability,表示两个节点没有任何的A-link 关系。
因此有: A i , j , 0 + ∑ c = 1 C A i , j , c = 1 A_{i,j,0}+\sum_{c=1}^C{A_{i,j,c}}=1 Ai,j,0+∑c=1CAi,j,c=1,其中 A i , j , 0 A_{i,j,0} Ai,j,0表示i和j没有联系的可能性。
初始化:
初始时,我们假设所有节点之间都没有A-link,则:
A : , : , 0 ( 0 ) = P 0 A_{:,:,0}^{(0)}=P_0 A:,:,0(0)=P0, A ; , : , c ( 0 ) = P 0 / C A_{;,:,c}^{(0)}=P_0/C A;,:,c(0)=P0/C
初始化后依据上述步骤进行训练。
Actional graph convolution (AGC)
在 经过预训练后得到可以在图卷积用的 A a c t A_{act} Aact, 且有 A a c t ( c ) = A : , : , c ∈ [ 0 , 1 ] n ∗ n A_{act}^{(c)}=A_{:,:,c} \in {[0,1]}^{n*n} Aact(c)=A:,:,c∈[0,1]n∗n,代表在第c个link type 上的linking probability。
convolution
先进行归一化,其中 D a c t ( c ) D_{act}^{(c)} Dact(c)为为第c个的出度所形成的对角矩阵。
A a c t ( c ) ^ = D a c t ( c ) − 1 A a c t ( c ) \hat{A_{act}^{(c)}}={D_{act}^{(c)}}^{-1}A_{act}^{(c)} Aact(c)^=Dact(c)−1Aact(c)
对于给定的卷积输入 X i n X_{in} Xin,我们有输出
KaTeX parse error: No such environment: split at position 8: \begin{̲s̲p̲l̲i̲t̲}̲ X_{act}&=AGC(X…
Note:这里其实就相当于图卷积了,只是我们的邻接矩阵不再仅仅表示边的连接,还表示links probabilities
在后续的数据训练过程中,我们的A还会根据encoder中的AIM来进行前反向传播更新参数
Structural Links (S-links)
思路想法:在ST-GCN中我们仅仅用了D=1,即只考虑邻居。而为了得到long-range links .我们可以采用邻接矩阵的L步可达作为卷积核,达到扩大感受野的目的。note;这里的L步可达详见图论,即若 A L A^L AL不为0,我们就成节点i会L步可达j.
Normaliza,avoid the magnitude explosion
A ^ = D − 1 A \hat{A}=D^{-1}A A^=D−1A
定义Structural graph convolutio(SGC):利用L来增加感受野
有
KaTeX parse error: No such environment: split at position 8: \begin{̲s̲p̲l̲i̲t̲}̲ X_{struc}&=SGC…
其中我们按照ST-GCN中,将A分为三个部分,分别为{self,离心,向心},即用p来表示,M为引入的注意力机制矩阵


Actional-Structural Graph Convolution Block
就是将AGC 和SGC 结合起来
KaTeX parse error: No such environment: split at position 8: \begin{̲s̲p̲l̲i̲t̲}̲ X_{out} &=ASGC…
λ \lambda λ是一个超参数,对Structural features 和Actional features 之间做一个平衡,达到最好的效果。
TCN (temporal convolution)
对于每个节点,提取他在时间轴上的features,具体实现细节我们可以参考ST-GCN中的细节部分
综上:
我们将ASGC和TCN结合在一起,构造出一个block 名字是 AS-GCN
Multitasking of AS-GCN
AS-GCN可以做两个任务:
1.Action recognition head
2.Future pose prediction head
Note :一般在实验中,我们将两个任务一起训练,且实验结果表明这样会提高动作识别的准确度,原因:对未来动作的预测可以促进模型更加了解潜在的关系,减少在识别时出现的过拟合
关于实验部分,就是利用控制变量法对照自己做比较,和前沿的模型做比较,证明自己特别优秀。
reference:
[1]S. Yan, Y. Xiong, and D. Lin. Spatial temporal graph convolutional networks for skeleton-based action recognition. In AAAI Conference on Artificial Intelligence, pages 74447452, Feb 2018.
[2]Actional-Structural Graph Convolutional Networks for Skeleton-based Action Recognition(CVPR2019)