读书笔记9:Spatio-Temporal LSTM with Trust Gates for 3D Human Action Recognition
传统的LSTM是处理时间序列的,是一个一维的问题,而本文提出了spatio-temporal LSTM,其实就是将一维的LSTM改成了二维的。
简介中,可以看出本文是准备探索基于RNN的3D skeleton based action recognition。并且指出本文将把RNN同时延伸到spatio-temporal维度,来同时从两个维度分析数据中的动作信息。受到人体骨架的结构的启发,作者还进一步提出了更加有效的基于树结构的遍历方法。为了解决3D骨架数据中的噪声和遮挡等问题,作者在LSTM中引入了新的gating mechanism来学习序列的稳定信息,并调整它在更新储存在memory cell里的长程上下文信息时候的影响。
作者提出的这个基于树结构的tree structure based skeleton traversal method是因为作者认识到人体各个关节之间的关系不能忽略,人体结构信息不可忽视,不能直接把一串关节信息直接丢到sequence learner里面,所以说这个tree structure其实是个常规操作,现在做skeleton based action recognition就没有忽视人体结构信息而直接把关节排成一串丢到网络中的,除非是直接基于视频做的动作识别,根本不是skeleton based,不需要考虑骨架结构信息。
gating mechanism是因为获取视频序列的depth sensor获取的信息并不总是靠谱的,有时可能不准确,因此搞一个gating mechanism来判断输入的信息的可靠性,这样就能更好地判断什么时候需要更新信息,什么时候需要遗忘或者保留储存在memory cell里的长程上下文信息。
作者将本文的贡献总结如下:1. 设计了时间空间双维度的LSTM网络。 2. 提出skeleton based tree traversal技术,来将skeleton数据的结构信息输入到LSTM序列模型中。3. 引入了gating mechanism。 4. 在数据集上取得了state-of-the-art的成果。
在related work部分,作者介绍了四个相关的,基于RNN或者LSTM的skeleton based recognition的工作。首先是HBRNN,之前的读书笔记写过,是将人体分成五个部分,每一个部分的关节信息都输入到一个单独的bidirectional RNN中,这些RNN的输出被连接在一起得到上半身和下半身两组信息,这两组信息再分别输入到两个RNN,之后全身的信息再由这两部分合并而来,再输入进一个RNN,最后一层RNN的输出输入到softmax分类器中得到最终的分类结果。第二个是Zhu et al.[51]提出的在深度LSTM网络的损失函数中加入mixed-norm regularization term来使网络学习co-occurrence of discriminative joints for action classification(并不太懂是什么意思)。并且这个工作还在LSTM单元中加了一个dropout。第三个是Differential LSTM,在LSTM内加入了一个新的gating,来记录memory states的微分,目的是发现一些明显动作的模式。输入的每一帧的所有的feature都连接在一起输入到differential LSTM中。第四个是part-aware LSTM,这个工作将LSTM的memory cell分成几个part-based的子cell(sub-cells),然后让网络独立的学习每一个part的长程的上下文信息。最终网络的输出是将part-based memory cell连接起来,然后通过一个正常的输出门(output gate)进行输出。
在介绍本文的模型前,先对LSTM进行一个回顾,一个标准的LSTM单元是包含一个输入门![]() ,遗忘门
,遗忘门![]() ,输出门
,输出门![]() ,memory cell
,memory cell![]() ,和输出的output state
,和输出的output state![]() 。LSTM的转换方程可以写作:
。LSTM的转换方程可以写作:
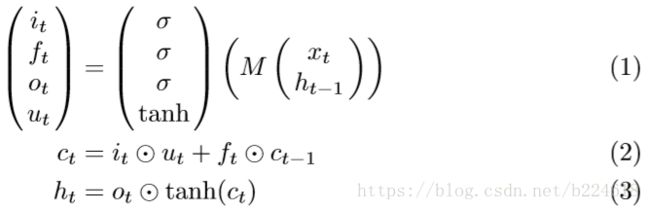
可以直观的理解为:先由这次的输入和上次的hidden state计算出输入门、遗忘门、输出门、以及一个![]() ,这个
,这个![]() 是一个经过调整的输入(modulated input)。然后输入门决定输入信息
是一个经过调整的输入(modulated input)。然后输入门决定输入信息![]() 多大程度山可以加入新的cell state,而遗忘门则考虑要将cell state的哪些旧信息遗忘,最后,输出门决定cell state有多少信息要在当前时刻输出出来。LSTM之所以相比于RNN能够记住很长程的上下文信息,就是因为有一个cell state,有一篇介绍LSTM的博客提供了很好的图示如下:
多大程度山可以加入新的cell state,而遗忘门则考虑要将cell state的哪些旧信息遗忘,最后,输出门决定cell state有多少信息要在当前时刻输出出来。LSTM之所以相比于RNN能够记住很长程的上下文信息,就是因为有一个cell state,有一篇介绍LSTM的博客提供了很好的图示如下:
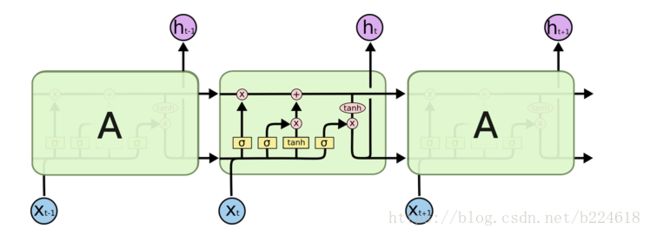
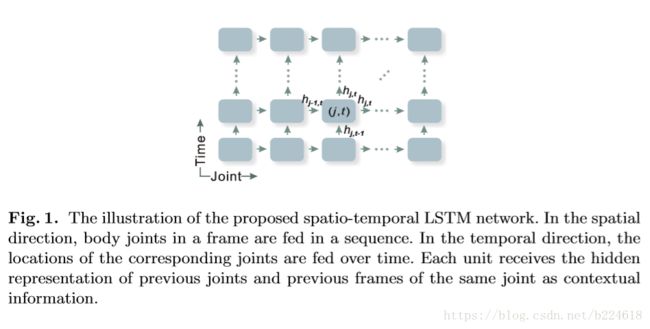
用RNN来处理3D human action recognition已经展示出不错的表现,证明了RNN在这种任务上的能力,但是作者认为,目前的基于RNN的方法都是直接将关节连接在一起,没有太考虑每一帧的静态的空间信息也是很重要的,因此本文准备将每一帧的每一个关节(joint)都视作一个LSTM的单元,同时在时间和空间两个维度进行LSTM的操作。本文采取两种方式设计空间维度上的LSTM,一种是将所有关节排列成一条线,另一种是保留人体的树状结构,设计一个遍历算法来将树状结构输入到spatial temporal LSTM。
第一种方法结构如下:
人体关节排列成一条直线的顺序如下图:
spatial temporal LSTM的公式形式如下
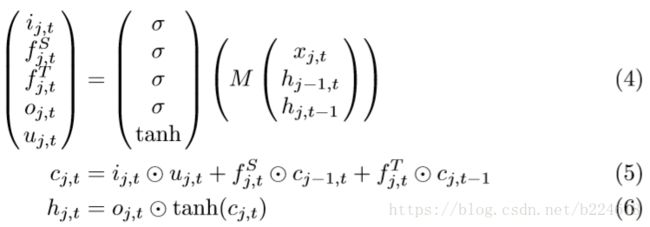
和temporal的LSTM很像,只不过每一次更新的时候,既结合时序上的前一个关节的信息,又要结合空间上上一个关节的信息,但是看到这想到一个问题,如果空间上的关节信息用完了,但是时序上还没用完,那该怎么继续更新?
接下来是利用tree structure based traversal来设计的spatial temporal LSTM。将关节直接整理成一个简单的链条忽略了关节之间的运动上的关系,并且在有一些并不是关联性很强的关节之间却加入了错误的连接。因此要用tree structure的人体结构图。这个tree structure based traversal的方法并不仅仅是将人体表示成了graph,更重要的是表示成了树,然后利用树的遍历方法进行遍历,用已有的遍历算法就可以。

如上图所示,右边的是遍历树的示意图,其实我不太明白这里为什么要将1作为根节点,人体图本身也是一个树,不扭曲应该也可以吧?作者强调在遍历树的过程中,每一个边都会过两次,保证了每一个节点都既能接收到前任的信息,又能获取后继的信息。
由于类似Kinetic这种摄像机获得的视频数据并不是完全可靠的,有的时候会受到噪声和遮挡的干扰,本文还提出了加入一个gate,通过评估上下文的信息来判断当前输入的信息是否可靠,也就是通过之前的输入来衡量当前的输入是否可靠。这个想法是受到了Sequence to sequence learning with neural networks这篇文章的启发,Sequence to sequence learning with neural networks这篇文章里提出了用LSTM根据之前的单词预测下一个出现的单词。这个想法能够实现是因为在句子中,后面单词和前面单词的依赖性是很高的,类似的,因为人体关节经常是一起运动的,这些运动在每一个spatial temporal step有着相似且复杂的模式(我觉得其实就是因为人体动作是连续的,关节的位置不会突变,所以人体动作具有可预测性),所以当前的输入是可以根据之前的上下文信息进行预测的。这种可预测性启迪我们在LSTM添加新的机制来预测输入,然后与实际的输入进行比较,估计误差输入到trust gate里面,生成的trust value提供信息给长程的memory机制来帮助它判断如何以及什么时候该遗忘或者记住信息。trust若是发现输入的和预测的偏差太大,那么就将输入门关闭,cell state就不会用当前输入的这个不可靠的信息进行更新。这个gate机制的数学表达可以写作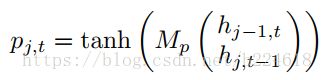 其中
其中![]() 是一个
是一个![]() 的矩阵
的矩阵
根据时间和空间维度上的前面的信息,生成一个p,作为对输入的预测。trust gate τ是如下定义的
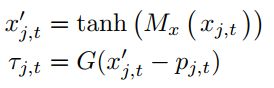
![]()
![]() 是一个仿射变换(affine transformation)(其实不是很懂为什么要用仿射变换,仿射变换可以做到什么?)这里需要注意到,生成的预测维度是d,而输入的维度是D,并不是一致的,输入先经过了一个仿射变换才与预测进行的对比,不是很明白为什么不直接生成D维的预测。以我目前对LSTM的认识,在这个预测中,hidden state是由cell state来生成的,但是对下一帧的预测应该是最近几帧的信息比较有用,所以反推LSTM的cell state主要储存的还是最近的信息?然后这个仿射变换应该是为了不改变原输入表达的空间信息,但是又能改变维度。最终ST-LSTM的cell state的更新可以写作
是一个仿射变换(affine transformation)(其实不是很懂为什么要用仿射变换,仿射变换可以做到什么?)这里需要注意到,生成的预测维度是d,而输入的维度是D,并不是一致的,输入先经过了一个仿射变换才与预测进行的对比,不是很明白为什么不直接生成D维的预测。以我目前对LSTM的认识,在这个预测中,hidden state是由cell state来生成的,但是对下一帧的预测应该是最近几帧的信息比较有用,所以反推LSTM的cell state主要储存的还是最近的信息?然后这个仿射变换应该是为了不改变原输入表达的空间信息,但是又能改变维度。最终ST-LSTM的cell state的更新可以写作
![]()
更新分为三部分,第一个是当前输入添加到cell state,τ越大越好,第二项和第三项作者给出的解释是,当前信息不可靠的话(τ小),我们需要更多地保留历史的cell state,而当前信息可靠的话,就可以使用当前的信息来更新cell state,但是这样会不会有问题?会不会在当前信息很可靠的时候过少的保留了历史信息?要知道有些历史信息是一直要用的,并不是当前信息可靠就不需要了,并不是可以被当前信息取代的。下图给出了加gate后的模型结构图
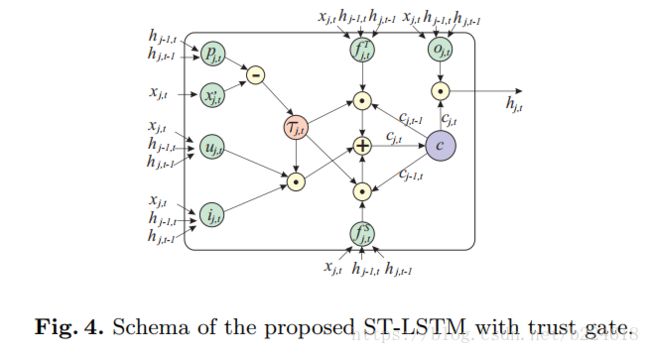
模型的预测结果是通过对每一个ST-LSTM unit的输出求平均得到的,而loss函数是这样的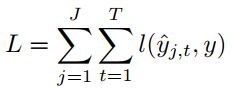 。
。![]() 采用的是negative log-likelihood loss。
采用的是negative log-likelihood loss。
实验部分:首先简介用了哪些数据集,都做了什么实验,本文是进行了将关节排列成一条线然后应用ST-LSTM的实验,tree-traversal + ST-LSTM的实验,以及Tree traversal + trust gate + ST-LSTM的实验。然后介绍了数据集。之后是implementation details,作者并不是将所有帧都输入模型,而是将每个序列分成T个子序列,每个子序列都随机抽取一帧。
之后就是介绍实验结果,本文的实验结果很丰富,按照数据集不同分了几个部分。NTU-RGBD首先就是按照官方推荐的cross view和cross subject两种设置进行了试验,然后简单分析了结果,说了trust gate带来了提升,因为Kinetic提供的数据总会有噪声或遮挡。然后作者还单独将易于产生遮挡的side view的数据提取出来,将有无trust gate的结果进行对比,进一步证明了trust gate的好处,为了验证多层网络的好处,作者提供了一层网络和两层网络结果的对比,作者还比较了不同neuron size(d,也就是hidden state的维度)和trust gate不同λ对准确率的影响。最后作者做了一件事

这个地方没太懂,early stopping不是训练时候用的吗?测试的时候给的数据多少影响准确率是什么意思?
其余几个数据集就是简单比较了结果准确率,然后最后还再次强调trust gate的重要性,手段是选了两个数据集中有噪声的样本,展示了有噪声时trust gate的激活程度就低,除此之外,作者还手动加了噪声。
整个实验部分玩的花样大概是:模型添加了不同机制,结果层层递进;用不同的网络参数,对比结果(包括层数,neuron size,参数λ之类的),用能够体现某些机制优势的数据集单独验证某些机制的优势,例如噪声的数据去测试trust gate机制。
文章写作总结:文章在介绍技术部分的时候思路很清晰,先介绍了最简单的joint chain ST-LSTM,然后说joint chain不能反映空间运动,要用tree structure,最后又说需要加trust gate,整个过程层层递进,条理清晰。分析一下abstract和introduction,abstract部分先是一句话介绍了3D动作识别因为某某原因很火,然后说最近关于这个领域有RNNbased method,在temporal domain,然后引出本文,我们延伸了这个想法到spatio-temporal domain,同时从时间空间两个维度来分析序列,之后又说考虑到人体的结构,提出了tree structure的method,之后为了解决噪声等问题,加入gating mechanism,最后一句说state-of-the-art。这几句介绍自己工作的话其实并未涉及到具体细节,只是说了名字,或者大体意思,我们将其延伸到时间空间两个domain,我们提出more powerful tree structure based traversal method,我们引入了一个新的gating mechanism这种很笼统的话,其实好多abstract好像都是这么写的,让人看的时候可能并不知道是怎么做的,不过abstract应该也就是这个特点。
introduction部分的结构是由大到小,首先说3D action识别很火,不同的提取特征和分类器学习的方法有很多,然后列举一大堆,不过确实是按照特征提取和分类器学习这两个方面介绍的。然后缩小范围,提出RNN,先说RNN的小背景,比如大概是个什么东西,成功的应用到什么方面,然后也成功地用到3D action recognition了。RNN用到3D action识别作者没给例子,直接就说RNNbased model都主要是模拟长程上下文信息,在temporal domain,但是spatial domain的信息也很重要,然后引出了下文对自己模型的介绍,对自己模型的介绍条理和技术部分一致,首先介绍最简单的ST-LSTM,然后层层递进,说明这个方法还有什么局限性,然后加一点东西,再有什么不足,再加一点东西,得到最高配置的模型。最后一段总结contribution。related work分析价值不大,文章最主要的应该就是abstract introduction和技术部分,然后是实验部分,实验部分要丰富,清晰。其与几个部分要专业,技术部分要有清晰的条理,适当的图片,必要的数学语言。