【一步步学Metal图形引擎5】-《Uniform Buffer》
教程 5
Uniform Buffer
教程源码下载地址: https://github.com/jiangxh1992/MetalTutorialDemos
CSDN完整版专栏: https://blog.csdn.net/cordova/category_9734156.html
一、Uniform Buffer的作用
Uniform Buffer和OpenGL中的一致变量类似,用来定义和传递渲染过程中的一些常量数据,例如:坐标系变换矩阵数据、光照参数以及其他自定义常量数据。Metal中通过一个专门的MTLBuffer来保存和传递这些常量数据,这个buffer就成为Uniform Buffer,buffer中的数据通过一个结构体来定义和组织。
这篇教程我们通过Uniform Buffer将MVP矩阵传递到顶点着色器,实现将模型从模型空间到屏幕空间的变换。关于图形学矩阵变换和坐标系、透视投影相关的基础原理,可以在这个OpenGL教程中的理论部分了解:一步步学OpenGL,这里不再详细分析和推导。
二、Address Spaces地址空间
地址空间属性(address space attribute)
GPU访问内存的方式有多种,不同的地址空间内存数据的访问模式和内存分配方式不同,Metal中向开发者提供了明确定义内存访问模式的语法属性,用来明确声明buffer数据内存分配的区域。开发者要根据数据使用的情景和需求,合理的定义数据的内存分配方式,从而正确高效的实现GPU数据的读写。
Metal中地址空间属性描述主要有以下几种:
- device
- constant
- thread
- threadgroup
- threadgroup_imageblock
GPU访问数据主要是通过图形着色器函数和kernal函数的参数传递,所有这些参数中有指针或引用指向的类型数据都必须要用地址空间属性来描述声明。其中图形着色器函数的指针或引用参数必须用device或者constant来描述。而kernal函数的指针或引用参数则会用到device、threadgroup、threadgroup_imageblock或者constant来描述。
device地址空间
device地址空间存放的是分配在设备内存池的数据对象,可读(readable)亦可写(writeable),没有内存大小限制,内存大小可变,灵活的内存对齐限制。
constant地址空间
constant地址空间存放的是数据对象也是分配在设备内存池的,但是数据是只读(readonly)的。constant修饰的数据在声明的时候必须初始化,初始化后内存大小固定,且在GPU上不可修改。constant地址空间的内存大小是有限制的。GPU上对constant地址空间的数据的访问做了优化,数据高度重用,不同图形或kernal函数访问同一个constant buffer数据更加高效。
thread地址空间
thread修饰的是每个线程各自的内存空间,当前线程地址空间分配的数据对其他线程不可见,属于线程独享数据,主要用在GPU图形函数或kernal函数内部的变量定义。
threadgroup地址空间
threadgroup地址空间针对的是A11的threadgroup memory特性,是一块线程组共享的tile memory。threadgroup memory是在kernal函数中声明和使用的共享内存,也可在fragment函数中访问,但不可在fragment函数中声明,另外不可在vertex函数中访问。
threadgroup的使用通常是在kernal函数中声明和赋值,传递到fragment中访问用于着色计算。例如tile based forward plus的例子中,就是在kernal函数中声明和计算每个tile的光源数据,传递到forward pass中的fragment函数中进行光照计算。
另外threadgroup_imageblock地址空间描述的是只能通过imageblock访问的threadgroup内存数据。
device和constant如何选择
最常用的还是图形着色函数中device地址空间和constant地址空的内存数据,我们要根据需要来选择合理的内存空间,尽可能的优化GPU数据的访问。
在选择这两个地址空间的时候要首先考虑他们的特点:
- device:内存大小灵活可变,内存大小没有限制,可读写,数据访问没有constant高效;
- constant:内存大小固定,只读,数据访问优化高效。
选择流程如下:
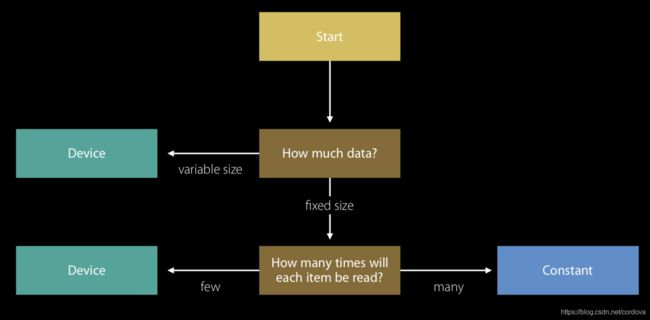
首先如果我们的数据是可能在GPU访问期间改变、增加或减少的,那么只能声明在device地址空间。如果访问期间数据不需要改变,则要考虑数据访问的频率。如何数据频繁的访问,则声明在constant地址空间,提高访问效率,否则生命在device地址空间即可。
因此对于频繁访问的常量数据,例如这篇教程中的Uniform Buffer,传递给GPU后不再需要修改,数据量也不大,但是会被大量着色器频繁重复的访问,所以最好声明在constant地址空间。
二、源码分析
ShaderTypes.h
typedef struct
{
matrix_float4x4 projectionMatrix;
matrix_float4x4 modelViewMatrix;
} Uniforms;
头文件中我们定义了一个Uniforms结构体,组织我们要传递的常量数据,这里我们只定义了用于MVP矩阵变换的模型视图矩阵和投影矩阵。Model-View矩阵将顶点坐标变换到视图空间坐标系,Projection矩阵将其变换到屏幕空间。
Render.m
id _uniformBuffer;
这里定义了一个MTLBuffer专门用来保存我们的一些常量数据,传递给着色器使用。
const MTLResourceOptions storageMode = MTLResourceStorageModeShared;
_uniformBuffer = [_device newBufferWithLength:sizeof(Uniforms)
options:storageMode];
在loadMetalWithMetalKitView函数中对_uniformBuffer进行了初始化,通过device申请一块buffer内存,buffer长度即Uniforms结构体的内存大小。MTLResourceStorageModeShared表示的是buffer保存在system memory上,但是被CPU和GPU共享,都可以访问。实际我们一般是在CPU上更新buffer的值,在GPU上访问buffer数据。
- (void) mtkView:(nonnull MTKView *)view drawableSizeWillChange:(CGSize)size
{
float aspect = size.width / (float)size.height;
float _fov = 65.0f * (M_PI / 180.0f);
float _nearPlane = 1.0f;
float _farPlane = 1500.0f;
_projectionMatrix = matrix_perspective_left_hand(_fov, aspect, _nearPlane, _farPlane);
}
另外我们还定义了一个临时的_projectionMatrix投影矩阵变量,投影矩阵在当前view的drawableSizeWillChange代理函数回调中设置更新,这样view尺寸变化时会自动调整视口大小。这里是采用了透视投影的方法来将物体投射到屏幕上,使用了matrix_perspective_left_hand工具函数来生成透视投影矩阵。透视相机参数_fov表示视口的角度,aspect表示屏幕宽高比,_nearPlane和_farPlane分别表示近裁面和远裁面。
/// Update app state for the current frame.
- (void)updateGameState
{
Uniforms * uniforms = (Uniforms*)_uniformBuffer.contents;
uniforms->projectionMatrix = _projectionMatrix;
matrix_float4x4 viewMatrix = matrix_multiply(matrix4x4_translation(0.0, 0, 1000.5),
matrix_multiply(matrix4x4_rotation(-0.5, (vector_float3){1,0,0}),
matrix4x4_rotation(_rotation, (vector_float3){0,1,0} )));
vector_float3 rotationAxis = {0, 1, 0};
matrix_float4x4 modelMatrix = matrix4x4_rotation(0, rotationAxis);
matrix_float4x4 translation = matrix4x4_translation(0.0, 0, 0);
modelMatrix = matrix_multiply(modelMatrix, translation);
uniforms->modelViewMatrix = matrix_multiply(viewMatrix, modelMatrix);
_rotation += 0.002f;
}
这里自定义了一个updateGameState函数,里面更新我们的Uniform Buffer数据。ViewMatrix我们将相机往后拉开1000的距离,然后绕x轴逆时针渲染一定角度略微抬高相机俯视原点,然后绕y轴旋转_rotation角度,是相机围绕原点旋转。ModelMatrix保持模型在原点不动,当然也可以让相机固定,让模型自身旋转。
这个函数每一帧开始前都会调用,buffer更新后每一帧会传递给着色器。此外我们定义个一个_rotation参数,每一帧递增,用于旋转视角,让相机围着模型360度旋转观察模型的各个角度,让画面动起来。
//...
[renderEncoder setVertexBuffer:_uniformBuffer offset:0 atIndex:1];
//...
每一帧开始前,我们会先在drawInMTKView中调用updateGameState函数更新buffer的值。此处我们的Uniform Buffer只需要传递给顶点着色器,因此调用setVertexBuffer将buffer传递进去,buffer index为1。
Shaders.metal
vertex ColorInOut vertexShader(Vertex in [[ stage_in ]],
constant Uniforms & uniforms [[ buffer(1) ]])
{
ColorInOut out;
float4 position = float4(in.position, 1.0);
out.position = uniforms.projectionMatrix * uniforms.modelViewMatrix * position;
out.texCoord = in.texCoord;
return out;
}
着色器我们只修改了顶点着色器。使用[[buffer(n)]]属性绑定语义接收顶点buffer数据,由于我们的Uniform Buffer在GPU上是只读数据,因此声明在constant地址空间。
四、运行效果
运行程序可以看到一个3D的模型在旋转,实际上是相机在围着模型旋转。