iOS界面渲染流程分析
前言
本文阅读建议
1.一定要辩证的看待本文.
2.本文所表达观点并不是最终观点,还会更新,因为本人还在学习过程中,有什么遗漏或错误还望各位指出.
3.觉得哪里不妥请在评论留下建议~
4.觉得还行的话就点个小心心鼓励下我吧~
在最近的面试中,我发现一道面试题,其考点是:围绕iOS App中一个视图从添加到完全渲染,在这个过程中,iOS系统都做了什么?
在进行了大量的文章查阅以及学习以后,将所有较为可靠的资料总结一下供大家参考。
面试题
本文可为以下面试题提供参考:
app从点击屏幕(硬件)到完全渲染,中间发生了什么?越详细越好 要求讲到进程间通信?出处
一个UIImageView添加到视图上以后,内部是如何渲染到手机上的,请简述其流程?
在一个表内有很多cell,每个cell上有很多个视图,如何解决卡顿问题?
简答
iOS渲染视图的核心是Core Animation
其渲染层次依次为:图层树->呈现树->渲染树
CPU阶段
-
布局(Frame)
-
显示(Core Graphics)
-
准备(QuartzCore/Core Animation)
-
通过IPC提交(打包好的图层树以及动画属性)
OpenGL ES阶段
-
生成(Generate)
-
绑定(Bind)
-
缓存数据(Buffer Data)
-
启用(Enable)
-
设置指针(Set Pointers)
-
绘图(Draw)
-
清除(Delete)
GPU阶段
-
接收提交的纹理(Texture)和顶点描述(三角形)
-
应用变换(transform)
-
合并渲染(离屏渲染等)
其iOS平台渲染核心原理的重点主要围绕前后帧缓存、Vsync信号、CADisplayLink
文字简答:
-
首先一个视图由CPU进行Frame布局,准备视图和图层的层级关系,查询是否有重写drawRect:或drawLayer:inContext:方法,注意:如果有重写的话,这里的渲染是会占用CPU进行处理的。
-
CPU会将处理视图和图层的层级关系打包,通过IPC(内部处理通信)通道提交给渲染服务,渲染服务由OpenGL ES和GPU组成。
-
渲染服务首先将图层数据交给OpenGL ES进行纹理生成和着色。生成前后帧缓存,再根据显示硬件的刷新频率,一般以设备的Vsync信号和CADisplayLink为标准,进行前后帧缓存的切换。
-
最后,将最终要显示在画面上的后帧缓存交给GPU,进行采集图片和形状,运行变换,应用文理和混合。最终显示在屏幕上。
以上仅仅是对该题简单回答,其中的原理以及瓶颈和优化,后面会详细介绍。
知识点
-
重新认识Core Animation
-
CPU渲染职能
-
OpenGL ES渲染职能
-
GPU渲染职能
-
IPC内部通信(进程间通信)
-
前后帧缓存&Vsync信号
-
视图渲染优化&卡顿优化
-
Metal渲染引擎
重新认识Core Animation
苹果官方文档-Core Animation
Core Animation并仅仅是字面意思的核心动画,而是整个显示核心都是围绕QuartzCore框架中的Core Animation
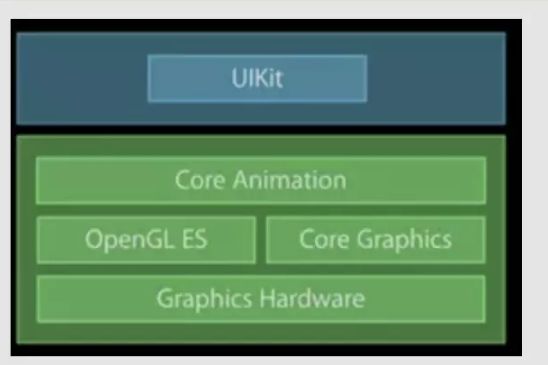
Core Animation是依赖于OpenGL ES做GPU渲染,CoreGraphics做CPU渲染,但在本文中,以及官方文档都是将OpenGL与GPU分开说明。
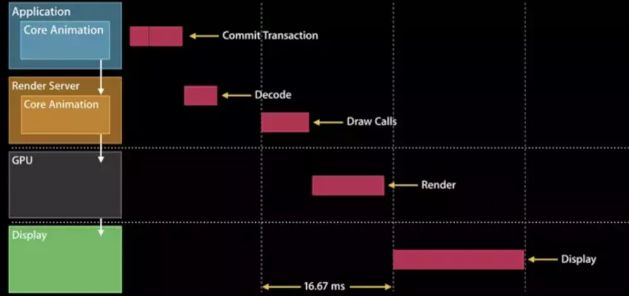
Core Animation 在 RunLoop 中注册了一个 Observer,监听了 BeforeWaiting 和 Exit 事件。这个 Observer 的优先级是 2000000,低于常见的其他 Observer。当一个触摸事件到来时,RunLoop 被唤醒,App 中的代码会执行一些操作,比如创建和调整视图层级、设置 UIView 的 frame、修改 CALayer 的透明度、为视图添加一个动画;这些操作最终都会被 CALayer 捕获,并通过 CATransaction 提交到一个中间状态去(CATransaction 的文档略有提到这些内容,但并不完整)。当上面所有操作结束后,RunLoop 即将进入休眠(或者退出)时,关注该事件的 Observer 都会得到通知。这时 CA 注册的那个 Observer 就会在回调中,把所有的中间状态合并提交到 GPU 去显示;如果此处有动画,CA 会通过 DisplayLink 等机制多次触发相关流程。
CPU渲染职能
在这里推荐大家去阅读落影loyinglin的文章iOS开发-视图渲染与性能优化
显示逻辑
-
CoreAnimation提交会话,包括自己和子树(view hierarchy)的layout状态等;
-
RenderServer解析提交的子树状态,生成绘制指令
-
GPU执行绘制指令
-
显示渲染后的数据

提交流程
布局(Layout)
-
调用layoutSubviews方法
-
调用addSubview:方法
显示(Display)
-
通过drawRect绘制视图;
-
绘制string(字符串);
准备提交(Prepare)
-
解码图片;
-
图片格式转换;
提交(Commit)
-
打包layers并发送到渲染server;
-
递归提交子树的layers;
-
如果子树太复杂,会消耗很大,对性能造成影响;
CPU渲染职能主要体现在以下5个方面:
布局计算
如果你的视图层级过于复杂,当视图呈现或者修改的时候,计算图层帧率就会消耗一部分时间。特别是使用iOS6的自动布局机制尤为明显,它应该是比老版的自动调整逻辑加强了CPU的工作。
视图懒加载
iOS只会当视图控制器的视图显示到屏幕上时才会加载它。这对内存使用和程序启动时间很有好处,但是当呈现到屏幕上之前,按下按钮导致的许多工作都会不能被及时响应。比如控制器从数据库中获取数据,或者视图 从一个nib文件中加载,或者涉及IO的图片显示,都会比CPU正常操作慢得多。
Core Graphics绘制
如果对视图实现了drawRect:或drawLayer:inContext:方法,或者 CALayerDelegate 的 方法,那么在绘制任何东 西之前都会产生一个巨大的性能开销。为了支持对图层内容的任意绘制,Core Animation必须创建一个内存中等大小的寄宿图片。然后一旦绘制结束之后, 必须把图片数据通过IPC传到渲染服务器。在此基础上,Core Graphics绘制就会变得十分缓慢,所以在一个对性能十分挑剔的场景下这样做十分不好。
解压图片
PNG或者JPEG压缩之后的图片文件会比同质量的位图小得多。但是在图片绘制到屏幕上之前,必须把它扩展成完整的未解压的尺寸(通常等同于图片宽 x 长 x 4个字节)。为了节省内存,iOS通常直到真正绘制的时候才去解码图片。根据你加载图片的方式,第一次对 图层内容赋值的时候(直接或者间接使用 UIImageView )或者把它绘制到 Core Graphics中,都需要对它解压,这样的话,对于一个较大的图片,都会占用一定的时间。
图层打包
当图层被成功打包,发送到渲染服务器之后,CPU仍然要做如下工作:为了显示 屏幕上的图层,Core Animation必须对渲染树种的每个可见图层通过OpenGL循环 转换成纹理三角板。由于GPU并不知晓Core Animation图层的任何结构,所以必须 要由CPU做这些事情。这里CPU涉及的工作和图层个数成正比,所以如果在你的层 级关系中有太多的图层,就会导致CPU没一帧的渲染,即使这些事情不是你的应用 程序可控的。
OpenGL ES渲染职能
这里推荐大家去看《OpenGL ES应用开发实践指南:iOS卷》,因为篇幅过长,就不赘述OpenGL的原理。

简单来说,OpenGL ES是对图层进行取色,采样,生成纹理,绑定数据,生成前后帧缓存。
1)生成(Generate)— 请 OpenGL ES 为图形处理器制的缓存生成一个独一无二的标识符。
2)绑定(Bind)— 告诉 OpenGL ES 为接下来的运算使用一个缓存。
3)缓存数据(Buffer Data)— 让 OpenGL ES 为当前定的缓存分配并初始化 够的内存(通常是从 CPU 制的内存复制数据到分配的内存)。
4)启用(Enable)或者(Disable)— 告诉 OpenGL ES 在接下来的渲染中是 使用缓存中的数据。
5)设置指(Set Pointers)— 告诉 Open-GL ES 在缓存中的数据的类型和所有需 要的数据的内存移值。
6)绘图(Draw) — 告诉 OpenGL ES 使用当前定并启用的缓存中的数据渲染 整个场景或者某个场景的一部分。
7)删除除(Delete)— 告诉 OpenGL ES 除以前生成的缓存并释相关的资源。
当显示一个UIImageView时,Core Animation会创建一个OpenGL ES纹理,并确保在这个图层中的位图被上传到对应的纹理中。当你重写-drawInContext方法时,Core Animation会请求分配一个纹理,同时确保Core Graphics会将你在-drawInContext中绘制的东西放入到纹理的位图数据中。
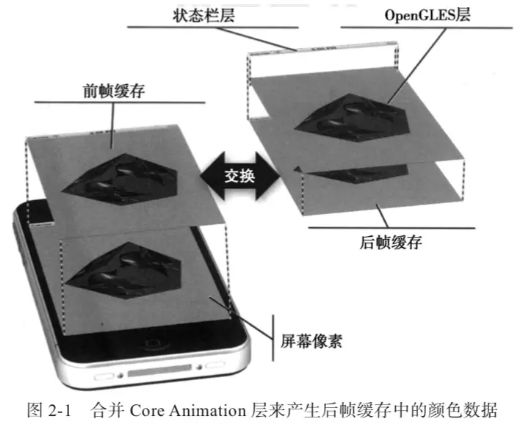
iOS 操作系统不会让应用直接向前帧缓存或者 后帧缓存绘图,也不会让应用直接复制前帧缓存和后帧缓存之间的切换。操作系统为自 己保留了这些操作,以便它可以随时使用 Core Animation 合成器来控制显示的最终外观
最终,生成前后帧缓存会再交由GPU进行最后一步的工作。
GPU渲染职能
GPU会根据生成的前后帧缓存数据,根据实际情况进行合成,其中造成GPU渲染负担的一般是:离屏渲染,图层混合,延迟加载。

普通的Tile-Based渲染流程
-
CommandBuffer,接受OpenGL ES处理完毕的渲染指令;
-
Tiler,调用顶点着色器,把顶点数据进行分块(Tiling);
-
ParameterBuffer,接受分块完毕的tile和对应的渲染参数;
-
Renderer,调用片元着色器,进行像素渲染;
-
-RenderBuffer,存储渲染完毕的像素;
离屏渲染 —— 遮罩(Mask)
-
渲染layer的mask纹理,同Tile-Based的基本渲染逻辑;
-
渲染layer的content纹理,同Tile-Based的基本渲染逻辑;
-
Compositing操作,合并1、2的纹理;
-
离屏渲染 ——UIVisiualEffectView
-
渲染等待
-
光栅化
-
组透明度
GPU用来采集图片和形状,运行变换,应用文理和混合,最终把它们输送到屏幕上。
太多的几何结构会影响GPU速度,但这并不是GPU的瓶颈限制原因,但由于图层在显示之前要通过IPC发送到渲染服务器的时候(图层实际上是由很多小物体组成的特别重量级的对象),太多的图层就会引起CPU的瓶颈。
重绘。主要由重叠的半透明图层引起。GPU的填充比率(用颜色填充像素的比率)是有限的,所以要避免重绘。
IPC内部通信(进程间通信)
在研究这个问题的过程中,我有想过去看一下源码,试着去理解在视图完全渲染之前,IPC是如何调度的,可惜苹果并没有开源绘制过程中的代码。这里推荐官方文章给大家了解一下iOS中IPC是如何运作的。
苹果官方文档-Mach内核编程 IPC通信
前后帧缓存&Vsync信号
虽然我们不能看到苹果内部是如何实现的,但是苹果官方也提供了我们可以参考的对象,也就是VSync信号和CADisplayLink对象。
iOS 的显示系统是由 VSync 信号驱动的,VSync 信号由硬件时钟生成,每秒钟发出 60 次(这个值取决设备硬件,比如 iPhone 真机上通常是 59.97)。iOS 图形服务接收到 VSync 信号后,会通过 IPC 通知到 App 内。App 的 Runloop 在启动后会注册对应的 CFRunLoopSource 通过 mach_port 接收传过来的时钟信号通知,随后 Source 的回调会驱动整个 App 的动画与显示。

帧缓存:接收渲染结果的缓冲区,为GPU指定存储渲染结果的区域
帧缓存可以同时存在多个,但是屏幕显示像素受到保存在前帧缓存(front frame buffer)的特定帧缓存中的像素颜色元素的控制。
程序的渲染结果通常保存在后帧缓存(back frame buffer)在内的其他帧缓存,当渲染后的后帧缓存完成后,前后帧缓存会互换。(这部分操作由操作系统来完成)
前帧缓存决定了屏幕上显示的像素颜色,会在适当的时候与后帧缓存切换。
Core Animation的合成器会联合OpenGL ES层和UIView层、StatusBar层等,在后帧缓存混合产生最终的颜色,并切换前后帧缓存;
OpenGL ES坐标是以浮点数来存储,即使是其他数据类型的顶点数据也会被转化成浮点型;
视图加载
那么在了解iOS视图渲染流程以后,再来看一下第二题:
一个UIImageView添加到视图上以后,内部是如何渲染到手机上的,请简述其流程?
我查看了较为流行的第三方库源码,例如YYImage、SDWebImage、FastImageCache,其中加载一个图片的流程大致为:
-
查看UIImageView的API我们可以发现,UIImage封装了一个CoreGraphics/CGImage的对象。
1.+[UIImage imageWithContentsOfFile:]使用Image I/O创建CGImageRef内存映射数据。此时,图像尚未解码。
-
返回的图像被分配给UIImageView。
-
如果图像数据为未解码的PNG/JPG,解码为位图数据
-
隐式CATransaction捕获到UIImageView layer树的变化
-
在主运行循环的下一次迭代中,Core Animation提交隐式事务,这会涉及创建已设置为层内容的所有图像的副本,根据图像:
-
缓冲区被分配用于管理文件IO和解压缩操作。
-
文件数据从磁盘读入内存。
-
压缩的图像数据被解码成其未压缩的位图形式
-
Core Animation使用未压缩的位图数据来渲染图层。
再看一下YYImage的源码,其流程也大致为:
-
获取图片二进制数据
-
创建一个CGImageRef对象
-
使用CGBitmapContextCreate()方法创建一个上下文对象
-
使用CGContextDrawImage()方法绘制到上下文
-
使用CGBitmapContextCreateImage()生成CGImageRef对象。
-
最后使用imageWithCGImage()方法将CGImage转化为UIImage。
当然YYImage不止做了这些,还有解码器编码器,支持webP等多种格式,并且还写了自定义的操作队列,对网络加载图片进行了优化。在此不赘述。
推荐文章:
苹果官方文档-CGImage位图
iOS图片加载速度极限优化—FastImageCache解析
Image I/O详解的文章
在这里同时推荐Y大的两篇文章
移动端图片格式调研
iOS 处理图片的一些小 Tip
视图渲染优化&卡顿优化
接下来我们看一下最后一题:
在一个表内有很多cell,每个cell上有很多个视图,如何解决卡顿问题?
什么是卡顿?苹果官方文章-显示帧率
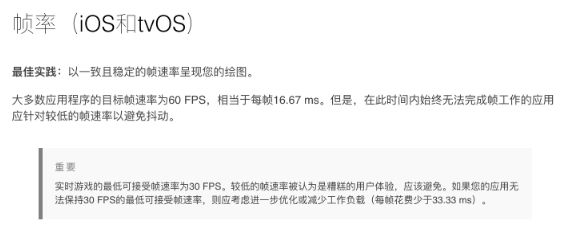
当你的主线程操作卡顿超过16.67ms以后,你的应用就会出现掉帧,丢帧的情况。也就是卡顿。
一般来说造成卡顿的原因,就是CPU负担过重,响应时间过长。主要原因有以下几种:
-
隐式绘制 CGContext
-
文本CATextLayer 和 UILabel
-
光栅化 shouldRasterize
-
离屏渲染
-
可伸缩图片
-
shadowPath
-
混合和过度绘制
-
减少图层数量
-
裁切
-
对象回收
-
Core Graphics绘制
-
-renderInContext: 方法
其中最常见的问题就是离屏渲染:
离屏渲染:离屏绘制发生在基于CPU或者是GPU的渲染,或者是为离屏图 片分配额外内存,以及切换绘制上下文,这些都会降低GPU性能。对于特定图 层效果的使用,比如圆角,图层遮罩,阴影或者是图层光栅化都会强制Core Animation提前渲染图层的离屏绘制。
如果视图绘制超出GPU支持的2048×2048或者4096×4096尺寸的 纹理,就必须要用CPU在图层每次显示之前对图片预处理,同样也会降低性能。
那么如何在需要渲染大量视图的情况下,还能保证流畅度,也就是保证FPS。
在这里推荐阅读郭曜源前辈的iOS 保持界面流畅的技巧
以及indulge_in的YYAsyncLayer剖析
我参考了YYAsyncLayer,他其中的原理大致是这样的:
YYAsyncLayer原理
YYAsyncLayer 是 CALayer 的子类,当它需要显示内容(比如调用了 [layer setNeedDisplay])时,它会向 delegate,也就是 UIView 请求一个异步绘制的任务。在异步绘制时,Layer 会传递一个 BOOL(^isCancelled)() 这样的 block,绘制代码可以随时调用该 block 判断绘制任务是否已经被取消。
当 TableView 快速滑动时,会有大量异步绘制任务提交到后台线程去执行。但是有时滑动速度过快时,绘制任务还没有完成就可能已经被取消了。如果这时仍然继续绘制,就会造成大量的 CPU 资源浪费,甚至阻塞线程并造成后续的绘制任务迟迟无法完成。我的做法是尽量快速、提前判断当前绘制任务是否已经被取消;在绘制每一行文本前,我都会调用 isCancelled() 来进行判断,保证被取消的任务能及时退出,不至于影响后续操作。
AsyncDisplayKit原理
ASDK 在此处模拟了 Core Animation 的这个机制:所有针对 ASNode 的修改和提交,总有些任务是必需放入主线程执行的。当出现这种任务时,ASNode 会把任务用 ASAsyncTransaction(Group) 封装并提交到一个全局的容器去。ASDK 也在 RunLoop 中注册了一个 Observer,监视的事件和 CA 一样,但优先级比 CA 要低。当 RunLoop 进入休眠前、CA 处理完事件后,ASDK 就会执行该 loop 内提交的所有任务。
Tips
优化方案围绕着 使用多线程调用,合理利用CPU计算位置,布局,层次,解压等,再合理调度GPU进行渲染,GPU负担常常要比CPU大,合理调度CPU进行计算可以减轻GPU渲染负担,使应用更加流畅。
Metal渲染引擎
当你现在再去查阅官方文档时,你会发现苹果官方已经使用Metal去替代OpenGL ES作为Core Animation的渲染。

苹果将Metal作为新的渲染引擎,更好的利用了GPU的性能,同时保证了低内存占用和省电,但我个人并没有深入研究Metal,这里可以有兴趣的同学可以看一下落影前辈的文章:
Metal入门教程总结
Metal入门教程(八)Metal与OpenGL ES交互
OpenGL 专题
参考
本文大量借助了引用文章的文字描述,在此感谢各位作者的文章对本问题的理解起了很大的帮助。也希望各位能去原文发表自己的看法。谢谢~
-
苹果官方视频-WWDC2014-Session419
-
苹果官方文章-显示帧率
-
落影loyinglin的文章iOS开发-视图渲染与性能优化
-
郭曜源前辈的文章:iOS 保持界面流畅的技巧
-
iOS 事件处理机制与图像渲染过程
-
推荐阅读:《iOS和MacOS性能优化》对于图像I/O方面,书中最后有详细解释。
总结
iOS开发要学的东西还有很多,因为时间的推移,每年的iOS岗位要求都在提高,导致我们在iOS开发岗位的同学要学习很多知识。例如Runtime、Runloop、音视频处理、视图渲染等,各位一起加油吧。
作者:筑梦师Winston