《TextBoxes++: A Single-Shot Oriented Scene Text Detector》论文笔记
1. 概述
这篇文章给出的方法是为了解决旋转文本检测的问题,因而文章的方法TextBoxes++是能够检测倾斜文本的,该方法检测文本是通过带角度的矩形框或是四边形框来表示的。由于该方法是源自于SSD的,因而这个网络是直通的,并不是类似Faster R-CNN的谅解网络,自然速度就很快了,作者在分辨率为 1024 ∗ 1024 1024*1024 1024∗1024分辨率的ICDAR 2015数据集上测得11.6FPS且F-Measure=0.817,在 768 ∗ 768 768*768 768∗768的COCO文本数据集上测得19.8FPS且F-Measure=0.5591。
在这之前论文的作者还出了版本叫做TextBoxes,论文的方法相比之前的TextBoxes具有的4点改进:
- 1)原本的TextBoxes支持水平方向的检测,现在支持检测有角度的文本了;
- 2)优化网络结构和训练流程,这使得性能进一步提升;
- 3)为了说明Textboxes++具有更好自然场景下任意角度文本检测的性能,做了更多的对比试验;
- 4)将检测与识别的信息整合来优化文本检测与字符识别;
SSD与TextBoxes++的关系:
TextBoxes++源自于SSD,SSD在检测一些极端长宽比例的文本的时候表现并不好,而在TextBoxes++中使用专门设计过的文件textbox layer去解决了这个问题,因而相比SSD在检测性能上有了进一步提升。
SSD只能产生水平方向的候选框,而TextBoxes++可以产生有旋转角度的矩形文本检测框或是一般四边形检测框去适应带有旋转的文本。
回归的基本思想:
其实TextBoxes++在与GT框进行匹配的时候还是使用的矩形框,anchor形成的候选框与包围GT的水平矩形框及四边形框进行回归,这样带来的好处就是优化的策略简单,对于每个区域产生的候选也少。
文章的主要贡献:
- 1)提出新的弯曲文本检测模型TextBoxes++,具有快速、准确、端到端训练的特点
- 2)提供了在检测框表示、模型配置及不同评价方法效果上的研究;
- 3)使用识别的结果来优化文本检测的结果,这个在之前的研究里面是没有的。
2. 实现方法
2.1 方法网络结构
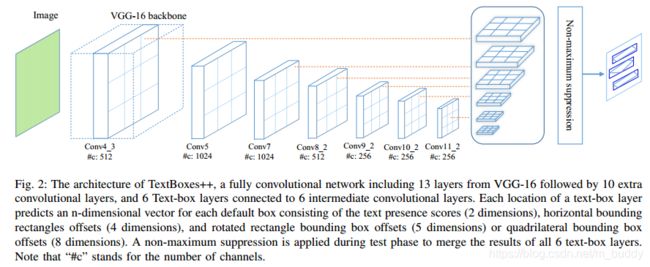
从上面的结构可以看出,这个结构与原SSD方法是很相似的,作者的主要重心在旋转文本的检测优化及极端长宽比例检测框的适应上。由于网络是由卷积与池化层组成的,这带来的好处就是网络可以接受任意尺度的图像作为输入,不用担心输入图像尺寸的问题。
2.2 边界框表达与回归
这里首先定义三个框: q , r , b q,r,b q,r,b。其分别代表四边形预测框,旋转矩形框以及最小水平边界框,其中个最小水平边界框是通过默认边界框回归得到的。这里需要说明的是:旋转矩形框和四边形矩形框是分开回归的,它们都与水平矩形框配对回归。对于这三个框的表达形式为,:
- 1) b 0 = ( x 0 , y 0 , w 0 , h 0 ) b_0=(x_0,y_0,w_0,h_0) b0=(x0,y0,w0,h0), ( x 0 , y 0 ) (x_0,y_0) (x0,y0)代表边界框的中心,后面的自然代表边界框的宽高了。
- 2) q 0 = ( x 01 q , y 01 q , x 02 q , y 02 q , x 03 q , y 03 q , x 04 q , y 04 q ) q_0=(x_{01}^q,y_{01}^q,x_{02}^q,y_{02}^q,x_{03}^q,y_{03}^q,x_{04}^q,y_{04}^q) q0=(x01q,y01q,x02q,y02q,x03q,y03q,x04q,y04q)
- 3) r 0 = ( x 01 r , y 01 r , x 02 r , y 02 r , h 0 r ) r_0=(x_{01}^r,y_{01}^r,x_{02}^r,y_{02}^r,h_0^r) r0=(x01r,y01r,x02r,y02r,h0r)
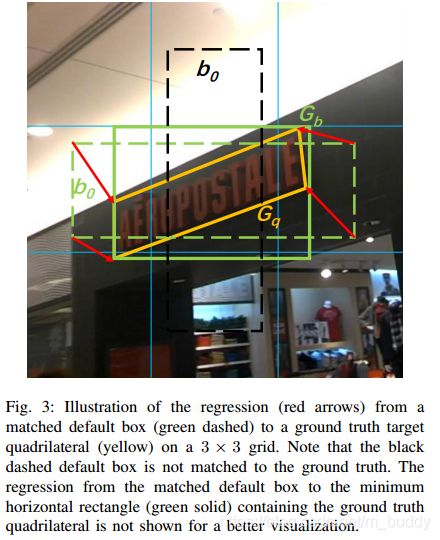
2.2.1 四边形形框的处理
那么对于四边形框它需要回归的变量是: ( Δ x , Δ y , Δ w , Δ w , Δ x 1 , Δ y 1 , Δ x 2 , Δ y 2 , Δ x 3 , Δ y 3 , Δ x 4 , Δ y 4 , Δ c ) (\Delta_{x},\Delta_{y},\Delta_{w},\Delta_{w},\Delta_{x_1},\Delta_{y_1},\Delta_{x_2},\Delta_{y_2},\Delta_{x_3},\Delta_{y_3},\Delta_{x_4},\Delta_{y_4},\Delta_{c}) (Δx,Δy,Δw,Δw,Δx1,Δy1,Δx2,Δy2,Δx3,Δy3,Δx4,Δy4,Δc),其种 c c c是置信度。那么对于一个四边形框 q = ( x 1 q , y 1 q , x 2 q , y 2 q , x 3 q , y 3 q , x 4 q , y 4 q ) q=(x_{1}^q,y_{1}^q,x_{2}^q,y_{2}^q,x_{3}^q,y_{3}^q,x_{4}^q,y_{4}^q) q=(x1q,y1q,x2q,y2q,x3q,y3q,x4q,y4q)的回归可以表示为:

2.2.2 旋转矩形框的处理
这里需要说明的是对于旋转的矩形框,这个的含义就是使用两个点却确定旋转矩形框的上面两个顶点,再加上一个高度就可以表示一个旋转矩形框了。它的四个顶点的表示为:
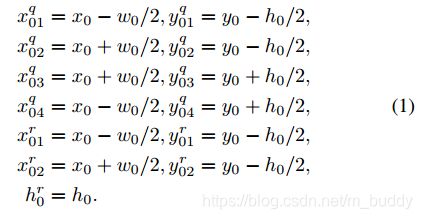
那么对于旋转矩形框它需要回归的变量是: ( Δ x , Δ y , Δ w , Δ w , Δ x 1 , Δ y 1 , Δ x 2 , Δ y 2 , Δ h r , Δ c ) (\Delta_{x},\Delta_{y},\Delta_{w},\Delta_{w},\Delta_{x_1},\Delta_{y_1},\Delta_{x_2},\Delta_{y_2},\Delta_{h^r},\Delta_{c}) (Δx,Δy,Δw,Δw,Δx1,Δy1,Δx2,Δy2,Δhr,Δc),其种 c c c是置信度。
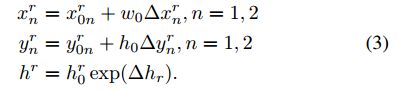
2.2.3 稠密检测区域的处理
论文中对于生成的默认边界框使用的长宽比例是: 1 , 2 , 3 , 5 , 1 2 , 1 3 , 1 5 1,2,3,5,\frac{1}{2},\frac{1}{3},\frac{1}{5} 1,2,3,5,21,31,51。对于一些稠密的情况见下图4,默认的边界框是不能很好框住文本区域的,因而文章在默认的边界框基础上添加了偏移去做相应的适应。

2.2.4 卷积核形状的选择
对于水平框的情况下卷积核的形状是 1 ∗ 5 1*5 1∗5,但是对于带有旋转情况下文章选择的是 3 ∗ 5 3*5 3∗5。
2.3 网络的训练
网络的损失函数: 损失函数是由定位损失与分类损失相加得到的。

这里为了快速收敛设置 α = 0.2 \alpha=0.2 α=0.2。
数据增广: 使用原始的数据随机剪裁会出现图5中(a,b)图的结果,自然这样的结果是很难符合真实场景下文本的呈现形式的,因而文章对其做了改进。

这用 B B B代表剪裁的边界框, G G G代表GT框, J J J代表Jaccard overlap, C C C代表object coverage。则他们之间的关系为:
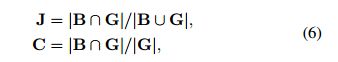
多尺度训练: 在上文中说到由于文章所提出的框架是只包含卷积与池化操作的,这样就可以使用多尺度训练来调配训练数据集中的大小目标的比例,从而对小目标表现出更好的适应性。
**边界框回归加入识别信息:**在下图6中的(a,b)具有相同的IoU但是识别的结果并不相同,因而文章中给的一个思路就是使用识别的结果来进一步优化检测的结果,最后取得像(c)一样的结果。

3. 实验结果
3.1 网络在一些数据集上的表现
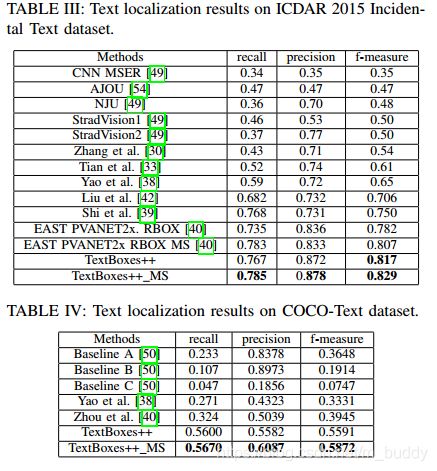
定位性能:

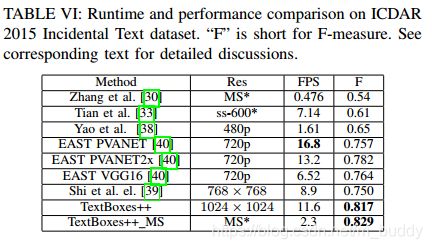
运行时间:
F-measures:

3.2 网络结合识别的表现
