深度学习必备数学基础 全讲解
文章目录
- 数学基础总览
- 矩阵对角化与SVD分解
- 逆与伪逆和最小二乘与最小范数解
- PCA原理与推导
- 极大似然估计
- 最优化问题
- 无约束最优化
- 有约束最优化
数学基础总览
总结花书1-4章,所必备的数学基础如下
- 矩阵对角化,SVD分解与应用(神经网络加速,图像压缩)
- 逆矩阵,伪逆矩阵,最小二乘解,最小范数解
- PCA原理与推导
- 极大似然估计等估计方法
- 有约束无约束的最优化问题
矩阵对角化与SVD分解
SVD具体内容可参考之前写的博客全面理解奇异值分解,矩阵对角化的内容简述一下:矩阵B的对角化为 P − 1 A P = B P^{-1}AP=B P−1AP=B,这里A是对角矩阵,P是标准正交矩阵。P的每一列叫做B的特征向量,A的每一个对角元素就叫做B的对应位置的特征向量所对应的特征值。关于这个更详细的描述可参考之前写的博客线性代数——特征向量与特征值。一般的矩阵不一定能对角化,但是对称矩阵一定可以对角化。
矩阵对角化后的表达式如下
A = ( u 1 , u 2 , ⋯ , u n ) ( λ 1 λ 2 λ 3 ) ( u 1 T ⋮ u n T ) = λ 1 u 1 u 1 T + λ 2 u 2 u 2 T + λ 3 u 3 u 3 T + ⋯ + λ n u n u n T \begin{aligned} A &=\left(u_{1}, u_{2}, \cdots, u_{n}\right)\left(\begin{array}{ccc} \lambda_{1} & & \\ & \lambda_{2} \\ & & \lambda_{3} \end{array}\right)\left(\begin{array}{c} u_{1}^{T} \\ \vdots \\ u_{n}^{T} \end{array}\right) \\ &=\lambda_{1} u_{1} u_{1}^{T}+\lambda_{2} u_{2} u_{2}^{T}+\lambda_{3} u_{3} u_{3}^{T}+\cdots+\lambda_{n} u_{n} u_{n}^{T} \end{aligned} A=(u1,u2,⋯,un)⎝⎛λ1λ2λ3⎠⎞⎝⎜⎛u1T⋮unT⎠⎟⎞=λ1u1u1T+λ2u2u2T+λ3u3u3T+⋯+λnununT
这个式子就可以用来做许多的事情,比如说图像的压缩,比如说特征值的选取,比如通过协方差矩阵筛选主要特征等等。
逆与伪逆和最小二乘与最小范数解
先看最小二乘的知识,可参考之前写的这篇博客最小二乘学习笔记,里面详细说明了最小二乘的知识,博客中线性回归最小二乘的公式是:
β = ( x T x ) − 1 x T Y \beta =\left(x^{T} x\right)^{-1} x^{T} Y β=(xTx)−1xTY
这里的-1就是逆, ( x T x ) − 1 x T \left(x^{T} x\right)^{-1} x^{T} (xTx)−1xT就是伪逆(想更深入了解逆的相关知识参见之前写的博客矩阵可逆性的理解与总结)。
那么最小范数解又是什么呢?由于 ( x T x ) − 1 \left(x^{T} x\right)^{-1} (xTx)−1不一定存在逆矩阵,所以就引入了最小范数解(最终解的形式其实和岭回归一致)。线性回归最小范数解的形式为
β = ( x T x + λ I ) − 1 x T Y \beta=\left(x^{T} x+\lambda I\right)^{-1} x^{T} Y β=(xTx+λI)−1xTY
这个解是通过解这个目标函数得到的
J = ∥ x a − Y ∥ 2 + λ ∥ a ∥ 2 \mathrm{J}=\|x a-Y\|^{2}+\lambda\|a\|^{2} J=∥xa−Y∥2+λ∥a∥2
这里的a是权重,可见这个目标函数比最小二乘的目标函数多出来了后面那一项,这一项就叫做L2正则项,在机器学习里面如果要实现权值衰减也需要添加这一项,相关内容可参考之前写的博客pytorch中的正则化方法和岭回归,Lasso回归,最小角回归以及三者对比分析。
PCA原理与推导
PCA是一种数据压缩的方法,如下图所示
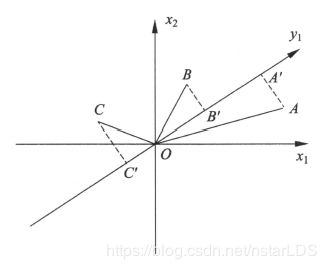
A 点需要 x,y 两个坐标来表示,假设 A 在向量 u 上面的投影点为 A’,则 A’ 仅仅需要一个参数就能表示,就是 OA’ 的长度 即 A’ 在 u 上的坐标 我们就想着用 A’ 来替换 A ,这样N个点原来要 2N 个参数,现在只需要 (N+2) 个参数 (u 也需要 2个参数)
但是此时就带来了误差,如 AA’ 和 BB’, 所以我们要能够找到这样一个方向 u, 使得所有原始点与投影点之间的误差最小,也就是找到最小重构误差。
以A点为例,假设向量AA’为e,向量OA为x,向量OA’为u(其实就叫做主方向),则
e ⃗ = x ⃗ − ⟨ x ⃗ , u ⃗ ⟩ u ⃗ = x − ( x T u ) u ; x , u ∈ R n \begin{aligned} \vec{e} &=\vec{x}-\langle\vec{x}, \vec{u}\rangle \vec{u} \\ &=x-\left(x^{T} u\right) u ; x, u \in \mathbb{R}^{n} \end{aligned} e=x−⟨x,u⟩u=x−(xTu)u;x,u∈Rn
其中
∥ u ∥ = 1 , u T u = 1 \|u\|=1, u^{T} u=1 ∥u∥=1,uTu=1
所以得出损失函数(目标函数)为
J = ∥ e ⃗ ∥ 2 = e T e = [ x − ( x T u ) u ] T [ x − ( x T u ) u ] = [ x T − ( x T u ) u T ] [ x − ( x T u ) u ] = x T x − ( x T u ) ( x T u ) − ( x T u ) ( x T u ) + ( x T u ) 2 u T u = ∥ x ∥ 2 − ( x T u ) 2 − ( x T u ) 2 + ( x T u ) 2 = ∥ x ∥ 2 − ( x T u ) 2 \begin{array}{l} \begin{aligned} J &=\|\vec{e}\|^{2}=e^{T} e=\left[x-\left(x^{T} u\right) u\right]^{T}\left[x-\left(x^{T} u\right) u\right] \\ &=\left[x^{T}-\left(x^{T} u\right) u^{T}\right]\left[x-\left(x^{T} u\right) u\right] \\ &=x^{T} x-\left(x^{T} u\right)\left(x^{T} u\right)-\left(x^{T} u\right)\left(x^{T} u\right)+\left(x^{T} u\right)^{2} u^{T} u \\ &=\|x\|^{2}-\left(x^{T} u\right)^{2}-\left(x^{T} u\right)^{2}+\left(x^{T} u\right)^{2} \\ &=\|x\|^{2}-\left(x^{T} u\right)^{2} \end{aligned} \end{array} J=∥e∥2=eTe=[x−(xTu)u]T[x−(xTu)u]=[xT−(xTu)uT][x−(xTu)u]=xTx−(xTu)(xTu)−(xTu)(xTu)+(xTu)2uTu=∥x∥2−(xTu)2−(xTu)2+(xTu)2=∥x∥2−(xTu)2
我们目的是要让损失函数的值最小,所以也就是令
max ( x T u ) 2 ⇔ max ( x T u ) ( x T u ) ⇔ max ( u T x ) ( x T u ) ⇔ max u T ( x x T ) u \begin{array}{l} \max \left(x^{T} u\right)^{2} \\ \Leftrightarrow \max \left(x^{T} u\right)\left(x^{T} u\right) \Leftrightarrow \max \left(u^{T} x\right)\left(x^{T} u\right) \\ \Leftrightarrow \max u^{T}\left(x x^{T}\right) u \end{array} max(xTu)2⇔max(xTu)(xTu)⇔max(uTx)(xTu)⇔maxuT(xxT)u
如果一共有N个样本,那么上式等价于
max ∑ i = 1 N u T ( x i x i T ) u = u T ( ∑ i = 1 N x i T x i ) u , 且 ∥ u ∥ = 1 max u T ( X ) u , s t : ∥ u ∥ = 1 \begin{array}{l} \max \sum_{i=1}^{N} u^{T}\left(x_{i} x_{i}^{T}\right) u=u^{T}\left(\sum_{i=1}^{N} x_{i}^{T} x_{i}\right) u, \text { 且 }\|u\|=1 \\ \max u^{T}(X) u, s t:\|u\|=1 \end{array} max∑i=1NuT(xixiT)u=uT(∑i=1NxiTxi)u, 且 ∥u∥=1maxuT(X)u,st:∥u∥=1
这里就想到用拉格朗日函数来求解,等式罗列如下
L ( u , λ ) = u T X u + λ ( 1 − u T u ) ∂ L ∂ u = 0 ⇒ X u − λ u = 0 X u = λ u ∂ L ∂ u = 0 ⇒ u T u = 1 \begin{array}{c} L(u, \lambda)=u^{T} X u+\lambda\left(1-u^{T} u\right) \\ \frac{\partial L}{\partial u}=0 \Rightarrow X u-\lambda u=0 \\ X u=\lambda u \\ \frac{\partial L}{\partial u}=0 \Rightarrow u^{T} u=1 \end{array} L(u,λ)=uTXu+λ(1−uTu)∂u∂L=0⇒Xu−λu=0Xu=λu∂u∂L=0⇒uTu=1
是否觉得眼熟?这个u就是对X进行特征值分解得到某一个的特征向量,并且每个特征向量都是单位向量。在这样的条件下,最后函数值为 λ u T u \lambda u^Tu λuTu,这里 λ \lambda λ越大越好,所以取最大特征值即可。
需要注意!上面解法的前提是默认只能有一个方向u来表示这些点,也就是说只能选取一个坐标轴作为投影方向。这样的解法没有办法解释保留多个主方向的PCA,如果需要深入了解,可参考之前写的博客主成分分析 所有知识点全解。
也就是说给定N个样本(上式的 x i x_i xi),如果要找一个坐标轴重新投影这些点,使得和原来比起来误差最小,那么这个坐标轴的方向就是X( X = x i x i T X=x_ix_i^T X=xixiT)的某个特征向量的方向。如果把所有特征向量都取过来当作一组新的坐标轴来表示这些点,那么这些点的信息不会有任何损失。如果去掉一些坐标轴甚至只保留一个坐标轴,那么这个坐标轴的方向就是最大特征值对应的特征向量的方向。
最后一定要强调的是,这里的x必须是已经经过中心化之后的x!否则上面的讨论是没有意义的。
极大似然估计
这里就不多说了,可以直接参考之前写的博客:
极大似然估计与贝叶斯估计
简单说就是,模型认为当前样本已经出现了,所以在构造的模型的时候,模型最后计算的结果应该是认为这些样本出现的概率最大。所以就对样本出现概率的乘积求最大值,从而优化模型的参数。
最优化问题
无约束最优化
一般采用梯度下降法,是标量(函数值)对矢量(多元函数的各个元)求导的问题(矢量对矢量求导就得雅各比矩阵),得到一个矢量,这个矢量就是梯度。梯度是函数值增长最快的方向,所以要找最小值就对梯度取负值,在这个负方向上更新一小步(这步迈多长就是学习率),最后要寻找的就是梯度各维都为0的点。
还可以使用牛顿法。
第一种解释是找函数一阶导的0点(找到导数的0点就是找到了极值点),来逐步逼近。
第二种解释是在某一点,采用一个二次函数来近似这个点周围的函数(为什么可以用二次函数近似可由泰勒公式证明),然后来找二次函数的最低点,最低点就是对称轴所在的位置,也就是 − b 2 a -\frac{b}{2a} −2ab,最后就导出牛顿法的迭代公式 x 0 − f ( x 0 ) ′ f ( x 0 ) ′ ′ x_0-\frac{f(x_0)^{'}}{f(x_0)^{''}} x0−f(x0)′′f(x0)′。
拟牛顿法就是简化二阶矩阵的逆矩阵,因为要求上面迭代公式里面的二阶导在高维的情况下是很麻烦的,拟牛顿法就利用另外一个矩阵来逼近逆矩阵,从而加速计算的过程。
比较:梯度下降是一次收敛,牛顿法是二次收敛,相比而言,牛顿法的收敛速度快,但是计算复杂,同时需要在比较接近最优点的时候才能收敛,否则就可能发散。
所以两者是有点互补的,最理想的就是先用梯度下降法来逼近,然后用牛顿法来找到精确的最优点。
有约束最优化
如果如下情况的等式约束:
max x , y f ( x , y ) s . t . g ( x , y ) = 0 \begin{array}{c} \max _{x, y} f(x, y) \\ s . t . g(x, y)=0 \end{array} maxx,yf(x,y)s.t.g(x,y)=0
可参考这张图
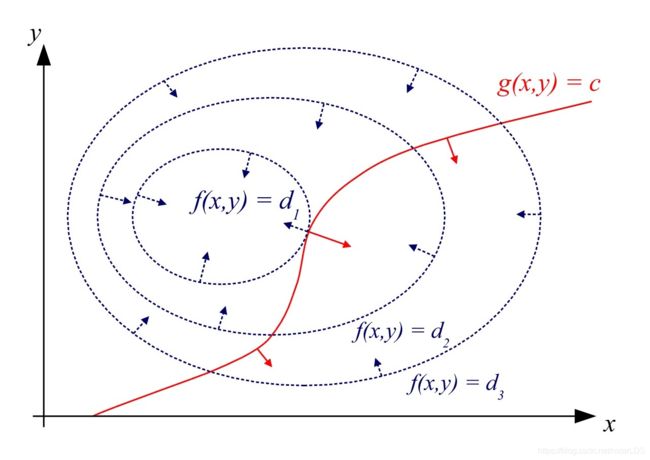
这张图说明,其实等式约束代表的就是一条直线,上图的一圈圈的椭圆虚线就是函数值的等高线,如果希望函数值越大或越小,同时x和y必须满足要在这条红色的直线上,那就只有一种情况:就是等高线和红色线相切,这时候函数值达到极值。相切就有f的梯度和g的梯度在一条直线上,所以有
{ ∇ f ( x , y ) = λ ∇ g ( x , y ) g ( x , y ) = c (1) \left\{\begin{array}{l} \nabla f(\boldsymbol{x, y})=\lambda \nabla g(\boldsymbol{x, y}) \\ g(\boldsymbol{x, y})=c \end{array}\right.\tag{1} {∇f(x,y)=λ∇g(x,y)g(x,y)=c(1)
引入拉格朗日函数
L ( x , y , λ ) = f ( x , y ) + λ g ( x , y ) L(x,y, \lambda)=f(x, y)+\lambda g(x, y) L(x,y,λ)=f(x,y)+λg(x,y)
对拉格朗日函数分别求偏导,解导数为0时的解,达到的效果就和公式(1)一样。
如果是不等式约束,就不是一条线了,而是一条线划分出的空间的某个范围,这时候在前面等式约束的基础上,就要加上一个KKT条件了。什么是KKT条件?如果想深入了解可参考之前写过的博客最大熵模型与学习算法附加拉格朗日对偶性详解中拉格朗日对偶性的讲解部分。如果简单了解,就看如下条件:
λ g ( x , y ) = 0 \lambda g(x, y) = 0 λg(x,y)=0
这个条件叫做互补松弛条件,可以将它近似理解成KKT条件。其意思就是,当原问题中不等式约束条件不等于0时(也就是小于0),也就是说在原问题中这个g(x, y)没有取到边界上,所以这个不等式约束是没有用的,那就要令其系数 λ \lambda λ为0来代表这个约束没用。如果有用了,取到边界上了,这时候g(x, y)=0, λ \lambda λ可以取任意值,就不对 λ \lambda λ做限制了。
总结一下就是对不起作用的约束,让 λ \lambda λ为0。注意这里的 λ \lambda λ是大于等于0的。