项目实战(九) - - Transformer实现与分析
项目实战(九) - - Transformer实现与解读
- 1. Transformer简介
- 2. Encoder-Decoder整体结构
- 2.1 Transformer Encoder
- 2.2 Transformer Decoder
- 3. 核心技巧与代码解析
- 3.1 Positional Encoding
- 3.2 Self Attention Mechanism
- 3.3 Mask矩阵设计
- 3.3.1 Pad mask
- 3.3.2 SubSequence mask
- 3.4 Multi-Head Self Attention
- 3.5 残差连接
- 3.5 Layer Normalization
- 4. Transformer VS Seq2Seq
1. Transformer简介
Transformer 模型主要分为两大部分,分别是 Encoder 和 Decoder
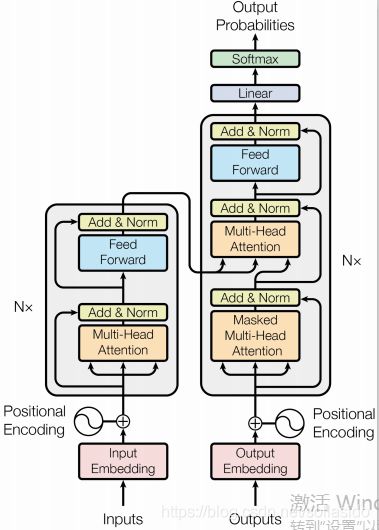
2. Encoder-Decoder整体结构
2.1 Transformer Encoder
6个Block,每个Block为Self-Attention+FFN
2.2 Transformer Decoder
6个Block,每个Block为Self-Attention+Attention+FFN,最后接Linear,经过softmax输出
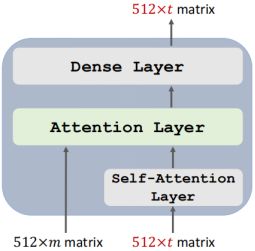
3. 核心技巧与代码解析
3.1 Positional Encoding
Transformers与RNN很大的不同在于RNN编码依赖于时间序列,随着输入序列的增长,模型性能会下降,模型可能会丢失掉较早出现的信息,这是因为编码时输入序列的全部信息压缩到了一个context向量中;Transformers完全丢掉了RNN,采用Self-Attention对输入进行并行编码,这样可能丢失输入的位置信息,因此加入位置编码(Positional Encoding)
注意,我们一般以字为单位训练 Transformer 模型。首先初始化字编码的大小为[vocab_size, embedding_dimension],vocab_size为字库中所有字的数量,embedding_dimension为字向量的维度,对应到 PyTorch 中,其实就是nn.Embedding(vocab_size, embedding_dimension)
![]()
Positional Encoding公式
用不同频率的sine和cosine函数直接计算position
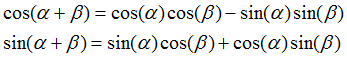
代码实现
class PosEncoding(nn.Module):
def __init__(self, max_seq_len, d_word_vec):
super(PosEncoding, self).__init__()
pos_enc = np.array(
[[pos / np.power(10000, 2.0 * (j // 2) / d_word_vec) for j in range(d_word_vec)]
for pos in range(max_seq_len)])
pos_enc[:, 0::2] = np.sin(pos_enc[:, 0::2])
pos_enc[:, 1::2] = np.cos(pos_enc[:, 1::2])
pad_row = np.zeros([1, d_word_vec])
pos_enc = np.concatenate([pad_row, pos_enc]).astype(np.float32)
# additional single row for PAD idx
self.pos_enc = nn.Embedding(max_seq_len + 1, d_word_vec)
# fix positional encoding: exclude weight from grad computation
self.pos_enc.weight = nn.Parameter(torch.from_numpy(pos_enc), requires_grad=False)
def forward(self, input_len):
max_len = torch.max(input_len)
tensor = torch.cuda.LongTensor if input_len.is_cuda else torch.LongTensor
input_pos = tensor([list(range(1, len+1)) + [0]*(max_len-len) for len in input_len])
return self.pos_enc(input_pos)
3.2 Self Attention Mechanism
定义三个矩阵Wq,Wk,Wv ,使用这三个矩阵分别对所有的字向量进行三次线性变换,得到三个新向量。拼接后得到Q,K,V三个矩阵。论文中Attention的计算采用了scaled dot-product
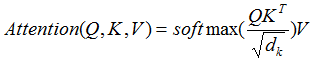
- 在基于RNN的Encoder-Decoder中,Q是decoder部分的隐状态s,K是encoder部分的output,将s与encoder最后一层的状态变量(K)计算相似度分数,经过softmax得到注意力向量α,将α与对应的V相乘求和得到context向量z
- Self-Attention只需要一套输入,将Q,K,V定义为一套输入向量的三次线性变换
计算流程:

代码实现
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V, attn_mask):
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k)
# scores : [batch_size x n_heads x len_q(=len_k) x len_k(=len_q)]
scores.masked_fill_(attn_mask, -1e9)
# Fills elements of self tensor with value where mask is one.
attn = nn.Softmax(dim=-1)(scores)
context = torch.matmul(attn, V)
return context, attn
3.3 Mask矩阵设计
3.3.1 Pad mask
对批量内最长的句子,或人工设定maxlen,将每个句子pad到maxlen的长度
3.3.2 SubSequence mask
这里有一个细节,我们要对 Attention Scores 进行 Mask,给定前一个输出如 “”,需要预测后面的句子,因此后面的子向量信息需要被mask掉。表现为一个下三角全 0,上三角全为负无穷的矩阵,然后将其与 Attention Scores 相加
3.4 Multi-Head Self Attention
Multi-Head Self Attention将一个个self-attention输出的context变量进行拼接
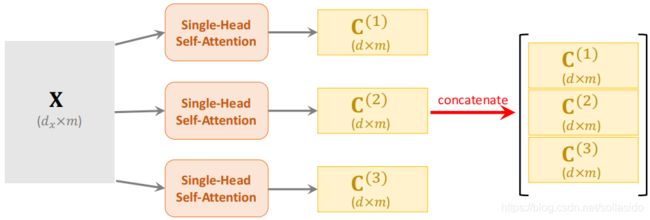
计算公式
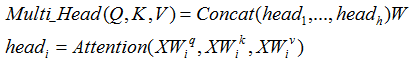
代码实现
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.src_emb = nn.Embedding(src_vocab_size, d_model)
self.pos_emb = nn.Embedding.from_pretrained(get_sinusoid_encoding_table(src_len+1, d_model),freeze=True)
self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)])
def forward(self, enc_inputs): # enc_inputs : [batch_size x source_len]
enc_outputs = self.src_emb(enc_inputs) + self.pos_emb(torch.LongTensor([[1,2,3,4,0]]))
enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs)
enc_self_attns = []
for layer in self.layers:
enc_outputs, enc_self_attn = layer(enc_outputs, enc_self_attn_mask)
enc_self_attns.append(enc_self_attn)
return enc_outputs, enc_self_attns
3.5 残差连接
![]()
3.5 Layer Normalization
Layer Normalization 的作用是把神经网络中隐藏层归一为标准正态分布,以起到加快训练速度,加速收敛的作用
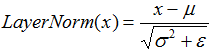
代码实现
class LayerNormalization(nn.Module):
def __init__(self, d_hid, eps=1e-6):
super(LayerNormalization, self).__init__()
self.gamma = nn.Parameter(torch.ones(d_hid))
self.beta = nn.Parameter(torch.zeros(d_hid))
self.eps = eps
def forward(self, z):
mean = z.mean(dim=-1, keepdim=True,)
std = z.std(dim=-1, keepdim=True,)
ln_out = (z - mean) / (std + self.eps)
ln_out = self.gamma * ln_out + self.beta
return ln_out
4. Transformer VS Seq2Seq
-
Seq2Seq 存在问题:串行训练问题;长程依赖问题
-
Transformer丢弃RNN,采用Attention,可以对输入并行训练;Attention机制可以考虑所有信息,无论序列长短,能对重点信息进行保留,无效信息进行丢弃,有效缓解
-
Transformer中的Self-Attention 模块,让源序列和目标序列首先“自关联” 起来,使得源序列和目标序列自身的embedding 所蕴含的信息更加丰富,FFN 层也增强了模型的表达能力