FlinkX Launcher 原理解析
FlinkX模式
local
本机启动一个flink的LocalStreamEnvironment
standalone
flink集群的standalone模式
yarn-perjob
在已经启动在yarn上的flink session里上运行
yarn-session
在yarn上单独启动flink session运行
配置
https://blog.csdn.net/u013076044/article/details/106392437
实现原理
Flink 提交作业流程
ClusterDescriptor
ClusterDescriptor: 表示部署到集群所需的描述信息,并且返回一个与集群通信的客户端

ClusterClient
ClusterClient 集群客户端封装了将程序提交到远程集群所需的功能。
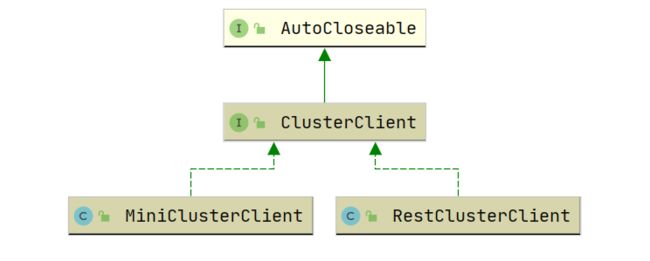
- RestClusterClient 将一个作业元数据通过HTTP REST 方式上传的到集群。底层的RestClient使用的是Netty。
- MiniClusterClient 本地集群客户端
以上就是Flink的提交原理,对应的我们看一下FlinkX是如何适配的。
FlinkX Launcher 入口
public static void main(String[] args) throws Exception {
setLogLevel(Level.DEBUG.toString());
OptionParser optionParser = new OptionParser(args);
Options launcherOptions = optionParser.getOptions();
findDefaultConfigDir(launcherOptions);
List<String> argList = optionParser.getProgramExeArgList();
switch (ClusterMode.getByName(launcherOptions.getMode())) {
case local:
com.dtstack.flinkx.Main.main(argList.toArray(new String[0]));
break;
case standalone:
case yarn:
ClusterClient clusterClient = ClusterClientFactory.createClusterClient(launcherOptions);
argList.add("-monitor");
argList.add(clusterClient.getWebInterfaceURL());
ClientUtils.submitJob(clusterClient, buildJobGraph(launcherOptions, argList.toArray(new String[0])));
break;
case yarnPer:
String confProp = launcherOptions.getConfProp();
if (StringUtils.isBlank(confProp)) {
throw new IllegalArgumentException("per-job mode must have confProp!");
}
String libJar = launcherOptions.getFlinkLibJar();
if (StringUtils.isBlank(libJar)) {
throw new IllegalArgumentException("per-job mode must have flink lib path!");
}
argList.add("-monitor");
argList.add("");
PerJobSubmitter.submit(launcherOptions, new JobGraph(), argList.toArray(new String[0]));
}
}
通过一个 switch 语句根据不同模式启动不同的环境。
本地模式
com.dtstack.flinkx.Main.main(argList.toArray(new String[0]));
Main.main
StreamExecutionEnvironment env = (StringUtils.isNotBlank(monitor)) ?
StreamExecutionEnvironment.getExecutionEnvironment() :
new MyLocalStreamEnvironment(flinkConf);
创建一个 MyLocalStreamEnvironment
Yarn-Session / Standalone
ClusterClient clusterClient = ClusterClientFactory.createClusterClient(launcherOptions);
argList.add("-monitor");
argList.add(clusterClient.getWebInterfaceURL());
ClientUtils.submitJob(clusterClient, buildJobGraph(launcherOptions, argList.toArray(new String[0])));
- 创建一个client
- 指定monitor地址
- 提交
其中的重点方法就是第一步骤:
创建 Standalone 客户端
public static ClusterClient createStandaloneClient(Options launcherOptions) throws Exception {
Configuration flinkConf = launcherOptions.loadFlinkConfiguration();
StandaloneClusterDescriptor standaloneClusterDescriptor = new StandaloneClusterDescriptor(flinkConf);
ClusterClient clusterClient = standaloneClusterDescriptor.retrieve(StandaloneClusterId.getInstance()).getClusterClient();
return clusterClient;
}
- 获取flink-conf.yaml => Configuration
- 返回 standaloneClusterDescriptor.retrieve(StandaloneClusterId.getInstance()).getClusterClient()
创建 YarnSession 客户端
public static ClusterClient createYarnClient(Options launcherOptions) {
Configuration flinkConfig = launcherOptions.loadFlinkConfiguration();
String yarnConfDir = launcherOptions.getYarnconf();
if(StringUtils.isNotBlank(yarnConfDir)) {
try {
FileSystem.initialize(flinkConfig);
// 根据job配置的yarn路径获取yarn的配置文件
YarnConfiguration yarnConf = YarnConfLoader.getYarnConf(yarnConfDir);
// 初始化yarnClient
YarnClient yarnClient = YarnClient.createYarnClient();
yarnClient.init(yarnConf);
yarnClient.start();
ApplicationId applicationId;
// 获取正在运行Flink-Yarn-Session的ApplicationMaster的ID
if (StringUtils.isEmpty(launcherOptions.getAppId())) {
// 通过api获取
applicationId = getAppIdFromYarn(yarnClient, launcherOptions);
if(applicationId == null || StringUtils.isEmpty(applicationId.toString())) {
throw new RuntimeException("No flink session found on yarn cluster.");
}
} else {
applicationId = ConverterUtils.toApplicationId(launcherOptions.getAppId());
}
// 判断是否是ha模式
HighAvailabilityMode highAvailabilityMode = HighAvailabilityMode.fromConfig(flinkConfig);
if(highAvailabilityMode.equals(HighAvailabilityMode.ZOOKEEPER) && applicationId!=null){
flinkConfig.setString(HighAvailabilityOptions.HA_CLUSTER_ID, applicationId.toString());
}
// 构建 YarnClusterDescriptor(Flink)
YarnClusterDescriptor yarnClusterDescriptor = new YarnClusterDescriptor(
flinkConfig,
yarnConf,
yarnClient,
YarnClientYarnClusterInformationRetriever.create(yarnClient),
true);
// 返回flink的ClusterClient
return yarnClusterDescriptor.retrieve(applicationId).getClusterClient();
} catch(Exception e) {
throw new RuntimeException(e);
}
}
throw new UnsupportedOperationException("Haven't been developed yet!");
}
- 根据job配置的yarn路径获取yarn的配置文件
- 初始化yarnClient,并与Yarn集群建立连接
- 获取正在运行Flink-Yarn-Session的ApplicationMaster的ID
- 判断是否是ha模式,如果是的话,设置集群标识
- 构建 YarnClusterDescriptor( 部署到Yarn集群所需的描述信息并且返回一个客户端用于和Yarn集群通信),
- 从yarn上获取appId的相关信息,并更新
flinkConfiguration的jobManager地址与rest.address,返回new RestClusterClient<>(flinkConfiguration, report.getApplicationId())
Per-Job
/**
* submit per-job task
* @param launcherOptions LauncherOptions
* @param jobGraph JobGraph
* @param remoteArgs remoteArgs
* @return
* @throws Exception
*/
public static String submit(Options launcherOptions, JobGraph jobGraph, String[] remoteArgs) throws Exception{
LOG.info("start to submit per-job task, launcherOptions = {}", launcherOptions.toString());
Properties conProp = MapUtil.jsonStrToObject(launcherOptions.getConfProp(), Properties.class);
// 初始化 ClusterSpecification
ClusterSpecification clusterSpecification = FlinkPerJobUtil.createClusterSpecification(conProp);
clusterSpecification.setCreateProgramDelay(true);
// 获取配置的jar
String pluginRoot = launcherOptions.getPluginRoot();
File jarFile = new File(pluginRoot + File.separator + getCoreJarFileName(pluginRoot));
// 设置flink-conf.yaml的配置
clusterSpecification.setConfiguration(launcherOptions.loadFlinkConfiguration());
// 设置作业所需的plugin
clusterSpecification.setClasspaths(analyzeUserClasspath(launcherOptions.getJob(), pluginRoot));
// 设置入口类 com.dtstack.flinkx.Main
clusterSpecification.setEntryPointClass(MAIN_CLASS);
// 设置作业类
clusterSpecification.setJarFile(jarFile);
if (StringUtils.isNotEmpty(launcherOptions.getS())) {
clusterSpecification.setSpSetting(SavepointRestoreSettings.forPath(launcherOptions.getS()));
}
clusterSpecification.setProgramArgs(remoteArgs);
clusterSpecification.setCreateProgramDelay(true);
// 设置yarn 配置
clusterSpecification.setYarnConfiguration(YarnConfLoader.getYarnConf(launcherOptions.getYarnconf()));
PerJobClusterClientBuilder perJobClusterClientBuilder = new PerJobClusterClientBuilder();
perJobClusterClientBuilder.init(launcherOptions, conProp);
// 部署
YarnClusterDescriptor descriptor = perJobClusterClientBuilder.createPerJobClusterDescriptor(launcherOptions);
ClusterClientProvider<ApplicationId> provider = descriptor.deployJobCluster(clusterSpecification, jobGraph, true);
String applicationId = provider.getClusterClient().getClusterId().toString();
String flinkJobId = jobGraph.getJobID().toString();
LOG.info("deploy per_job with appId: {}}, jobId: {}", applicationId, flinkJobId);
return applicationId;
}
- Perjob 与以上的几种模式的设置类似。区别在于它的YarnClusterDescriptor的sharedYarnClient为false,即每个任务都会创建一个ApplicationMaster
以上讲的是几种集群的执行模式,但是其只是构建Flink对应的Client而已,仅仅是一层层包装而已。
被包装的逻辑参考 FlinkX 实现原理(全局总览) 中的流程图。
总结
其实FlinkX的启动器是和Flink强相关的,请参考Flink Runtime 核心机制剖析-读后总结中的【一个作业是如何提交到Flink上并被执行的?】和Flink on Yarn/K8s 原理剖析及实践,而我们就是需要把Flink集群运行期间所需要的所有信息(ClusterDescriptor)都准备好即可。在FlinkX中,包括如flink-conf、作业配置、依赖的jar包等。
个人看法: 可以通过适配flink-clients的api(不是重写一些底层类)从而减少与flink的耦合性(减少代码升级导致的不兼容问题,目前flinkx-launcher不兼容1.11.1与 k8s ,以及gpu)。