2. C++标准库
2.1 IO库

- IO对象无拷贝或赋值,进行IO操作的函数通常以引用方式传递和返回流。
-
IO库条件状态


- 导致缓冲刷新的原因:
1)程序正常结束
2)缓冲区满
3)endl
4)用unitbuf。默认情况下,对cerr是设置unitbuf,因此写到cerr的内容是立即刷新的
5)一个输出流可能被关联到另一个流,关联到的流的缓冲区会被刷新。 - 刷新输出缓冲区
endl
flush 不输出任何额外字符
ends 向缓冲区插入一个空字符,然后刷新缓冲区 - unitbuf
如果想在每次输出操作后都刷新缓冲区,使用unitbuf,告诉流每次操作之后进行一次flush。nounitbuf则是重置流,恢复正常的系统管理的缓冲区刷新机制。
cout << unitbuf;
cout << nounitbuf;
- 如果程序崩溃,输出缓冲区很可能不会被刷新。
- 标准库将cout和cin关联在一起,因此cin >> ival;将导致cout的缓冲区被刷新。
- tie函数,将流关联到输出流。
-
fstream继承了iostream类型的行为,并且还新增了一些新的成员来管理与流关联的文件。

- 当一个fstream对象呗销毁时,close会自动被调用
-
文件模式

-
指定文件模式的限制

默认情况下,与ifstream关联的文件以in模式打开;与ofstream关联的文件以out模式打开;与fstream关联的文件默认以in和out模式打开。
-
sstream头文件定义了三个类型来支持内存IO。

- istringstream使用场景:对整行文本进行处理,而其他一些工作是处理行内的单个单词。
ostringstream使用场景:逐步构造输出,最后一起打印。
- 总结:
1)iostream 处理控制台IO
2)fstream处理命名文件IO
3)stringstream处理内存stringIO
并且fstream和stringstream都继承自类iostream。
2.2 顺序容器

- 与内置数组相比,array是一种更为安全、更容易使用的数组类型
- forward_list的设计目标是达到与最好的手写的单向链表数据结构相当的性能
- 新标准库的容器比旧版本快得多,性能几乎肯定与最精心优化过的同类数据结构一样好(通常会更好)。
-
选择顺序容器的基本原则:

- 容器操作分为三个层次
1)某些操作是所有容器都提供的
2)另外一些操作仅针对顺序容器、关联容器或无序容器
3)还有一些操作只适用于一小部分容器 - 保存没有默认构造函数的类型
// noDefault是一个没有默认构造函数的类型
vector v1(10, init); //提供元素初始化器
错误 vector v2(10);
-
容器的共有操作


迭代器
迭代器范围[begin, end)。这种左闭合区间,使用特定的编程范式:
while (begin != end) {
*begin = val;
++begin;
}
-
容器定义和初始化

当将一个容器初始化为另一个容器的拷贝时,两个容器的容器类型和元素类型必须相同。
使用迭代器范围时,只要能将要拷贝的元素转换为要初始化的容器的元素类型即可。 - array的大小也是类型的一部分。
array
array
- 内置数组不能进行拷贝或对象赋值,但是array可以
array digits = {0, 1,2 ,3, 4, 5, 6, 7, 8, 9};
array copy = digits;
-
容器赋值运算

除array外,swap不对任何元素进行拷贝、删除或插入操作,因此可以保证在常数时间内完成。swap两个array会真正交换它们的元素。
非成员版本的swap在范型编程中是非常重要的,统一使用成员版本的swap是一个好习惯。
-
顺序容器添加元素操作

- 容器元素是拷贝
- 使用insert的返回值,insert返回指向所有新加入元素的第一个的迭代器。
list lst;
auto iter = lst.begin();
while (cin >> word) {
iter = lst.insert(iter, word); //等价于调用push_front
}
- emplace_front、emplace、emplace_back这些操作构造而不是拷贝元素。当调用push、insert成员函数时,将对象拷贝到容器中。当调用emplace时,则是将参数传递给元素类型的构造函数。
调用emplace_back,会在容器管理的内存空间中直接创建对象。而调用push_back则会创建一个临时对象,并将其压入容器中。
因此传递给emplace函数的参数必须与元素类型的构造函数相匹配。
正确:c.emplace_back("874-13498901850", 24, 14.88);
错误:c.push_back("874-13498901850", 24, 14.88);
正确:c.push_back(Sales_data("874-13498901850", 24, 14.88));
-
顺序容器的访问操作

-
顺序容器的删除操作

删除元素的成员函数并不检查其参数,在删除元素之前,程序员必须确保它们是存在。
-
forward_list中插入或删除元素的操作

-
改变容器大小

管理迭代器
使用迭代器时,必须保证每次改变容器的操作之后(添加、删除)都正确地重新定位迭代器。
如果在一个循环中插入/删除deque、string或vector中的元素,不要缓存end返回的迭代器。
-
vecotr的元素是连续存储的。

size是指容器已经保存的元素的数量
capacity是在不分配新的内存空间的前提下最多可以保存多少元素。
-
string的其他方法








- 三个顺序容器适配器
stack
queue
priority_queue - 适配器是标准库中的一个通用概念。容器、迭代器和函数都有适配器,本质上,一个适配器是一种机制,能使某种事物的行为看起来像另外一种事物。
-
素有容器适配器都支持的操作和类型

- 默认情况下,stack和queue是基于deque实现的,priority_queue是在vector上实现的。可以在创建一个适配器时将一个命名的顺序容器作为第二个类型参数,来重载默认容器类型。
stack> str_stk; // 在vector上实现栈
-
栈适配器

-
队列适配器


2.3 泛型算法
- 标准库并未给每个容器添加大量功能,而是提供了一组算法,这些算法中的大多数都独立于任何特定的容器。
- 大多数算法定义在algorithm中,numeric定义了一组数值范型算法。
- 一般情况下,这些算法并不直接操作容器,而是遍历由两个迭代器指定的一个元素范围进行操作。
算法永远不改变底层容器的大小,可能改变元素的值,移动元素。 - find——在一个未排序的元素列表中查找一个特定元素
find操作不依赖于容器所保存的元素类型。 - 迭代器令算法不依赖于容器,但算法依赖于元素类型的操作,例如==等比较运算符。
- 理解算法的最基本方法就是了解它们是否读取元素、改变元素或是重拍元素顺序。
1)只读算法——通常使用cbegin()和cend()
find count accumulate
equal 假定第二个序列至少与第一个序列一样长。
那些只接受一个单一迭代器表示第二个序列的算法,都假定第二个序列至少与第一个序列一样长。
2)写算法
fill fill_n copy replace replace_copy
向目的位置迭代器写入数据的算法假定目的位置足够大,能容纳要写入的元素。
一种保证算法有足够元素空间来容纳输出数据的方法是使用插入迭代器。
back_inserter接受一个指向容器的引用,返回一个与该容器绑定的插入迭代器。当我们通过此迭代器赋值时,赋值运算符会调用push_back将一个具有给定值的元素添加到容器中。
3)重排算法
sort unique
vector vec;
auto it = back_inserter(vec);
*it = 42;
vector vec;
fill_n(back_inserter(vec), 10, 0);
-
定制操作——谓词
sort stable_sort find_if for_each
可调用对象:函数、函数指针、重载了函数调用运算符的类、lambda表达式
lambda表达式:
[capture list] (parameter list) -> return type {function body}
capture list是一个lambda所在函数中定义的局部变量的列表。捕获列表只用于局部非static变量,lambda可以直接使用局部static变量和在它所在函数之外声明的名字。
当定义一个lambda时,编译器生成一个与lambda对应的新的(未命名的)类类型。
值捕获:与参数不同,被捕获的变量的值是在lambda创建时拷贝,而不是调用时拷贝。
引用捕获:保证被引用的对象在lambd
a执行的时候是存在,比如IO对象的引用。
隐式捕获:为了指示编译器推断捕获列表,应在捕获列表中写一个&或=。&告诉编译器采用引用捕获方式,=表示采用值捕获方式。

stable_sort(words.begin(), words.end(), [] (const string &a, const string &b) {return a.size() < b.size()} );
auto wc = find_if(words.begin(), words.end(), [sz](const string &a) {return a.size() >= sz;});
for_each(wc, word.end(), [](const string &s){cout << s << " ";} );
- 对于一个值拷贝的变量,lambda不会改变其值,如果希望改变一个被捕获的变量的值,就必须在参数列表首加上关键字mutable。
- 如果一个lambda体包含return之外的任何语句,则编译器假定此lambda返回void。此时,必须使用尾置返回类型:
transform(vi.begin(), vi.end(), vi.begin(),
[](int i) -> int
{if (i < 0) return -i; else return i;} );
- 如果lambda的捕获列表为空,通常可以用函数来代替它;对于捕获局部变量的lambda,用函数来替代它就不那么容易了。
- functional中的bind函数,看作一个通用的函数适配器,它接受一个可调用对象,生成一个新的可调用对象来适应原对象的参数列表。
auto newCallable = bind(callable, arg_list);
当调用newCallable时,会调用callable,并传递给它arg_list参数。_n表示占位符,表示newCallable的参数,占据了传递给newCallable的参数位置,n表示生成可调用对象中参数的位置:_1为newCallable的第一个参数,_2第二个,依此类推。 - ref和cref定义在头文件functional中
bool check_size(const string &s, string::size_type sz) {
return s.size() >= sz;
}
auto check6 = bind(check_size, _1, 6); // bind调用只有一个占位符,表示check6
//只接受单一string参数,6赋值给了check_size的sz。
auto wc = find_if(words.begin(), words.end(),
bind(check_size, _1, sz));
sort(words.begin(), words.end(), isShorter); // 由短到长排序
sort(words.begin(), words.end(), bind(isShorter, _2, _1); //由长到短排序
for_each(words.begin(), words.end(),
bind(print, ref(os), _1, ' ')); //对于ostream,只能返回一个引用,此对象可拷贝
- 名字_n都定义在placeholders的命名空间中,而这个命名空间本身定义在std命名空间中。placeholders定义在functional头文件中。
- 除了为每个容器定义的迭代器之外,标准库在iterator头文件中还定义了其他迭代器
1)插入迭代器:这些迭代器被绑定到一个容器上,可以用来向容器插入元素
2)流迭代器:这些迭代器被绑定到输入或输出流上,可用来遍历所关联的IO流
3)反向迭代器:这些迭代器向后面不是向前移动,除了forward_list之外的标准库容器都有反向迭代器
4)移动迭代器:这些专用的迭代器不是拷贝其中的元素,而是移动它们。 -
插入迭代器

back_inserter创建一个使用push_back的迭代器;
front_inserter创建一个使用push_front的迭代器
inserter创建一个使用insert的迭代器。此函数接受第二个参数,这个参数必须是一个指向给定容器的迭代器。元素被插入到给定迭代器之前。
front_inserter和inserter迭代器的行为截然相反:
list lst = { 1, 2, 3, 4 };
list lst2, lst3;
copy(lst.cbegin(), lst.cend(), front_inserter(lst2));
copy(lst.cbegin(), lst.cend(), inserter(lst3, lst3.begin()));
for_each(lst2.cbegin(), lst2.cend(), [](const int s){cout << s << " "; });
cout << endl; // 4 3 2 1
for_each(lst3.cbegin(), lst3.cend(), [](const int s){cout << s << " "; });
cout << endl; // 1 2 3 4
-
iosream迭代器
istream_iterator和ostream_iterator将对应的流当作一个特定类型的元素序列来处理。
1)istream_iterator
一个istream_iterator使用>>来读取流,因此要读取的类型必须定义了输入运算符。

2)ostream_iterator
ostream_iterator可以提供第二参数,它是一个字符串,在输出每个元素后都会打印此字符串。
ostream_iterator不允许空的或表示尾后位置的ostream_iterator.

istream_iterator in_iter(cin);
istream_iterator eof;
while (in_iter != eof) {
vec.push_back(*in_iter++);
}
等价于:
istream_iterator in_iter(cin), eof;
vector vec(in_iter, eof);
//////////////////////////////////////////////////////////////////////////
ostream_iterator out_iter(cout, " ");
for (auto e:vec) {
*out_iter++ = e; //运算符*和++实际上对ostream_iterator对象不做任何事情
}
cout << endl;
-
反向迭代器
不能从forward_list或流迭代器创建反向迭代器,因为不支持递减运算符。
reverse_iterator的base成员函数可以将反向迭代器转换成一个普通迭代器。

auto rcomma = find(line.crbegin(), line.crend(), ',');
cout << string(rcomma.base(), line.cend()) << endl;
- 五类迭代器

1)输入迭代器必须支持:
用于比较两个迭代器的相等和不相等运算符(==、!=);
用于推进迭代器的前置和后置递增运算符(++);
用于读取元素的解引用运算符(),解引用只会出现在赋值运算符的右侧;
->等价于(*it).member。
输入迭代器只用于顺序访问,不能保证输入迭代器的状态可以保存下来并访问元素。因此,输入迭代器只能用于单遍扫描算法。
find accumulate要求输入迭代器,istream_iterator是一种输入迭代器。
2)输出迭代器必须支持:
用于推进迭代器的前置和后置递增运算符(++);
用于写入元素的解引用运算符(),解引用只会出现在赋值运算符的左侧。
只能向一个输出迭代器赋值一次。只能用于单遍扫描算法。
copy函数的第三个参数就是输出迭代器。ostream_iterator是输出迭代器。
3)前向迭代器
只能在序列中沿一个方向移动,支持输入和输出迭代器的操作,可以多次读写同一个元素。可以保存前向迭代器的状态,可以进行多遍扫描。
replace要求前向迭代器。forward_list上的迭代器时前向迭代器。
4)双向迭代器
支持所有前向迭代器操作,还支持前置和后置递减运算符(--)。
reverse要求双向迭代器,除forward_list外其他标准库都提供符合双向迭代器要求的迭代器。
5)随机访问迭代器
支持双向迭代器的操作,还支持:
用于比较两个迭代器相对位置关系运算符(<、<=、>和>=);
迭代器和一个整数值的加减运算(+、+=、-和-=),计算结果是迭代器在序列中前进(或后退)给定整数个元素后的位置;
用于两个迭代器上减法运算符(-),得到两个迭代器的距离;
下标运算符(iter[n]),与*(iter[n])等价。
sort要去随机访问迭代器,array、deque、string和vector的跌大气都是随机访问迭代器,用于访问内置数组元素的指针也是。 - 算法形参模式,四种形式:
alg(beg, end, other args);
alg(beg, end, dest, other args);
alg(beg, end, beg2, other args);
alg(beg, end, beg2, end2,other args);
1)dest
向输出迭代器写入数据的算法都假定目标空间足够容纳写入的数据。
dest一般绑定到一个插入迭代器或是一个ostream_iterator。
2)beg2或beg2,end2
接受beg2的算法假定从beg2开始的序列与beg和end所表示的范围至少一样大。 - 算法命名规范
一些算法使用重载形式传递一个谓词。unique(beg, end, comp);
接受谓词参数的算法都附加有_if前缀。find find_if
区分拷贝和不拷贝版本。 reverse reverse_copy
-
特定容器算法——list、forward_list
对于list和forward_list,应该优先使用成员函数版本的算法而不是通用算法。


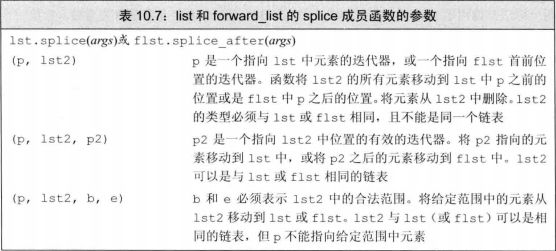
链表特有版本与通用版本间的一个至关重要的区别是链表版本会改变底层容器。
2.4关联容器
- 关联容器中的元素是按关键字来保存和访问的。与之相对,顺序容器中的元素是按它们在容器中的位置来顺序保存和访问的。
-
八个关联容器,三个维度:
1)set or map
2)关键字是否重复
3)是否有序

- 关联容器的迭代器都是双向的,关联容器不支持顺序容器的位置相关的操作,如push_front等
-
关联容器的关键字map multimap set multiset必须定义元素比较的方法。默认使用<来比较两个关键字。
定义的比较函数必须具备如下基本性质(严格弱序):

-
标准库utility中的pair类型

- map和set的关键字都是const,不能修改
-
关联容器操作

关联容器定义的专用的find成员会比调用泛型find快得多。
如果真要对一个关联容器使用算法,要么将它当作一个源序列,要么当作一个目的位置。





如果容器中没有指定的元素,lower_bound将指向第一个关键字大于k的元素。lower_bound和upper_bound可以一起指定范围。
lower_bound和upper_bound一起指定范围等价于equal_range。
-
无序容器
无序容器使用一个哈希函数和关键字类型的==运算符。
无序容器组织为一组桶,容器将具有一个特定哈希值的所有元素都保持在相同的桶中。无序容器的性能依赖于哈希函数的质量和桶的数量和大小。

标准库为内置类型(包括指针)、string、智能指针定义了hash,因此可以定义这些类型的无序容器。
自定义类类型的无序容器必须提供自己的hash模板版本。
2.5 动态内存
- new delete
- 为了更容易、更安全地使用动态内存,标准库头文件memory提供了两种智能指针来管理动态对象。智能指针负责自动释放所指向的对象。
shared_ptr允许多个指针指向同一个对象,weak_ptr是一种弱引用,指向shared_ptr所关联的对象;unique_ptr独占所指向对象. -
shared_ptr类

可以认为每个shared_ptr都有一个关联计数器,称为引用计数,拷贝一个shared_ptr,计数器会递增。
当给shared_ptr赋予一个新值或是shared_ptr被销毁时,计数器会递减。
一旦一个shared_ptr的计数器变为0,就会自动释放自己所管理的对象。
由于在最后一个shared_ptr销毁前内存都不释放,保证shared_ptr在无用之后不再保留很重要。
如果shared_ptr存放在一个容器中,而后不再需要全部元素,只使用其中的一部分,要记得用erase删除不再需要的那些元素。 - 使用动态内存的三个原因:
1)程序不知道自己需要使用多少对象——容器
2)程序不知道所需对象的准确类型
3)程序需要在多个对象间共享数据 - new/delete
对动态的对象进行初始化通常是个好主意。
内存耗尽new会抛出bad_alloc异常,可以传递给new一个nothrow对象,不抛出异常,此时返回一个空指针。
返回指向动态内存的指针(而不是指针)的函数给其调用者增加了一个额外的负担——调用者必须记得释放内存。 - new/delete管理动态内存存在三个常见问题
1)内存泄漏,忘记delete
2)使用已经释放掉的对象
3)同一块内存释放两次 - delete指针后,将指针置为nullptr;但是这对其他指向该内存的指针没有效果。
-
可以使用new返回的指针来初始化智能指针,接受指针参数的智能指针构造函数是explicit,必须使用直接初始化形式,不能使用赋值。
默认情况下,一个用来初始化智能指针必须指向动态内存,智能指针默认使用delelte释放它所关联的对象。可以将智能指针绑定到一个指向其他类型资源的指针上,此时必须提供自己的操作来替代delete。


shared_ptr p1(new int(1024));
shared_ptr clone(int p) {
return shared_ptr(new int(p));
}
- 当将一个shared_ptr绑定到一个普通指针时,就将内存的管理责任交给shared_ptr。一旦这样做,就不应该使用内置指针来访问shared_ptr所指向的内存了。
- 智能指针的get函数,返回内置指针,指向智能指针管理的对象。
应用情况:需要向不能使用智能指针的代码传递一个内置指针。使用get返回指针的代码不能delete该指针。特别是,不能将另一个智能指针绑定到此指针。 - 改变shared_ptr对象,如果不是唯一用户,需要拷贝一份新的进行改变
if(!p.unique()) {
p.reset(new string(*p));
}
*p += newVal;
- 智能指针可以确保发生异常之后,资源被正确地释放。但是直接管理的内存时不会自动释放的。
对于不具良好定义的类,如果在资源分配和释放之间发生了异常,程序会发生资源泄漏。可以使用shared_ptr来避免资源泄漏。
//存在内存泄漏风险的代码
struct destination;
struct conneciton;
connection connect(destination*);
void disconnect(connection);
void f(destination &d) {
connection c = connect(&d);
}
//使用shared_ptr防止内存泄漏
void end_connection(connection *p) {
disconnect(*p);
}
void f(destination &d) {
connection c = connect(&d);
shared_ptr p(&c, end_connection);
}
- 智能指针必须坚持的基本规范
1)不适用相同的内置指针初始化(或reset)多个智能指针
2)不delete get()返回的指针
3)不适用get() 初始化或reset另一个智能指针
4)如果使用get()返回的指针,记住当最后一个对应的智能指针销毁后,你的指针就变为无效了
5)如果使用智能指针管理的资源不是new分配的内存,记住传递给它一个删除器。
-
unique_ptr
某个时刻只能有一个unique_ptr指向一个给定对象。
unique_ptr不支持普通的拷贝或赋值操作,可以通过release或reset将指针的所有权从一个(非const)unique_ptr转移到另一个。

- 不能拷贝unique_ptr的规则有一个例外:可以拷贝或赋值一个将要销毁的unique_ptr
unique_ptr clone(int p) {
return unique_ptr(new int(p));
}
unique_ptr clone(int p) {
unique_ptr ret(new int (p));
return ret;
}
- unique_ptr管理删除器的方式与shared_ptr不同。
void f(destination &d) {
connection c = connect(&d);
unique_ptr
p(&c, end_connection);
}
-
weak_ptr
不控制所指向对象生存期的智能指针,它指向一由一个shared_ptr管理的对象。
将一个weak_ptr绑定到一个shared_ptr不会改变shared_ptr的引用计数。

不能使用weak_ptr直接访问对象,必须调用lock。
if (shared_ptr np = wp.lock()) {
}
- 两种分配对象数组的方法
1)new表达式语法
2)allocator类,将分配和初始化分类,通常会提供更好的性能和更灵活的内存管理能力 - 大多数应用应该使用标准库容器而不是动态分配的数组。使用容器更为简单,更不容易出现内存管理错误并且可能有更好的性能。
-
管理new分配数组的unique_ptr

unique_ptr up(new int[10])
up.release() //自动调用delete[]销毁其指针
- 与unique_ptr不同,shared_ptr不直接支持管理动态数组,需要提供自定义的删除器。
shared_ptr未定义下标运算,且智能指针不支持指针算术运算。 -
allocator类——头文件memory
new将内存分配和对象构造组合在一起,同样,delete将对象析构和内存释放组合在一起。
当分配一大块内存时,统计计划在这块内存上按需构造对象,即内存分配和对象构造分离。
allocator将内存分配和对象构造分离开,分配的内存时原始的、未构造的。

-
allocator伴随算法——拷贝和填充未初始化内存的算法
头文件memory中:
