Jmeter文件的相对路径及编码在Windows和Linux下的兼容性
Jmeter实际上是不需要安装的,只需要有ApacheJMeter.jar、启动批处理文件(jmeter.bat或jmeter)、配置文件(jmeter.properties、user.properties、saveservice.properties等)、lib文件(一堆的jar包)就足够在Windws和Linux下运行了,纯绿色并且是轻量级的(总共不到50M就够用了)。另外Jmeter各个版本中,首先推荐的是Jmeter3.1版本,因为它足够新,而且同时兼容JDK1.7和1.8(但要注意的是,Server端和Client端还是应该保持统一版本的JDK),更高的版本就不再支持JDK1.7了。
既然Jmeter能同时在Windws和Linux下运行,那么我们还需要注意什么呢?有两点,一是路径关系及路径符号,二是字符集编码,解决了这两个问题,我们就能将Windows下调试通过的Jmeter包(包括jmx脚本)全部复制到Linux下并直接就可以用jmeter启动文件调用jmx脚本跑起来,甚至连输出jtl报告、CSV报告、html报告都能完全兼容。
一、路径问题
1、很多人习惯用绝对路径,这样的话兼容性就很差了,把脚本迁移到另一台机器就要重新配置。其实相对路径只要应用得当,可以让脚本的兼容性提升很多。
首先应该理解Jmeter的相对路径是怎么定义的,其实Jmeter的相对路径是指脚本所对应的目录,比如脚本jmx在D:\testJmeter下,那么CSV Data Set Config就可以配成以下相对路径:

这个路径就表示,ID.csv文件对应的绝对路径是D:\testJmeter\dat\ID.csv。
同样如果Beanshell中引用了Java的相对路径如下:
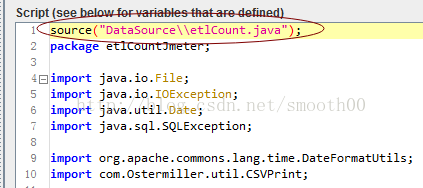
那么就表示对应的绝对路径是D:\testJmeter\etlCount.java
2、以上举的例子是在Windows下的,到了Linux下就会报错,这是因为Linux识别路径的符号不是反斜杆"\",而是正斜杠"/",而且windows下兼容性是最好的,无论正反斜杠都能识别,所以我们filename应该改为dat/ID.csv,同样source引用java文件,也可以改成如下:
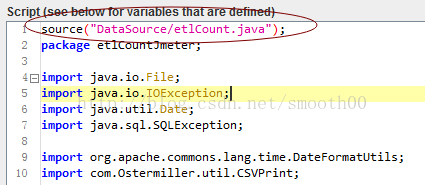
3、第三个问题,也就是jmx脚本文件到底应该放哪比较好,虽然以上的相对路径能够解决换电脑后不需要修改文件路径了,但还是不够可靠,这是因为jmeter执行文件是在bin目录下的,很多时候程序默认是以jmeter的bin目录为根路径的,如果参数文件或是java文件的相对路径不是以bin为开始目录,很可能在分布式测试时,就出现远程代理机所调用的文件路径与本地脚本不一致。
所以最好的方式是,将jmx脚本统一放在bin目录下,然后参数文件或是source文件再以脚本的相对路径进行匹配。比如参数文件的绝对路径为:D:\testJmeter\bin\dat\ID.csv,这样相对路径还会是dat/ID.csv,那么换任何一种环境,或是用任何一种方式调用(比如通过Ant调用)都能保证找到一致路径下的文件。
同时,还要确保所有被调用的jar放到lib/ext目录下(其实放到lib目录下也行),这样就不需要配置jar的路径了,程序会自动找到这个目录并调用jar包。
总结:相对路径只是为了方便代码或脚本的迁移,而将脚本放到bin目录下,只是方便默认路径的引用,否则就要通过配置环境变量(如export)或是在build.xml中配置好jmeter的执行目录、根目录才能保证路径的正确性。
4、另外我们在编码过程中,也有意识的多用一些相对路径(很多程序都具有这样的功能,这能为我们省掉一些麻烦),如下:
/**
* 获得excel文件的路径
* @return
* @throws IOException
*/
public String getPath(String fileName) throws IOException {
File directory = new File(".");
sourceFile = directory.getCanonicalPath() + "/DataSource/"
+ fileName + ".xls";
return sourceFile;
}二、字符编码问题
只要是在我们的参数文件或是java文件中使用了中文,就避免不了编码兼容性的问题。我们经常会碰到在Windows下编辑好的文件,到了linux下就显示中文乱码,甚至通过Jmeter输出的日志、发送的请求都成了乱码。
解决这个问题的最好方式,是统一编码,一般我们都是统一采用UTF-8编码,或者在Linux环境中安装部署更多的中文支持包。
如果当我们的参数文件或是Java文件在Linux下读取时出现乱码,我们最简单的一种方式是用在Windows下用编辑器(如UltraEdit)另存为无BOM的UTF-8格式,记住是无BOM的,否则到了Linux环境就会出现编译错误(如果纯粹只写不读取的文件,是否带BOM头就无所谓了)。从这点来说,Windows对编码格式的处理要比Linux兼容性强(开源的东西,总是要处处踩着坑才能过去)。
关于Jmeter的编码问题,可以参照我的另一篇文章 http://blog.csdn.net/smooth00/article/details/70236638
需要说明的是jmeter响应数据默认编码格式是ISO-8859-1(向下兼容ASCII,自身不显示中文,依赖于平台的编码来显示中文),Windows默认保存的文件编码格式是ANSI/ASCII(但Windows默认以GBK来显示中文),而在Linux我们通常默认以UTF-8编码格式来显示中文。所以这三者如果能统一的话,就可以避免乱码显示。另外就是很多网站是以UTF-8或gb18030(GBK)编码来显示中文的,通过Jmeter来发送邮件时最好注意一下Web展示方面的问题。
jmeter的配置文件jmeter.properties中可以修改sampler响应数据的编码:
# The encoding to be used if none is provided (default ISO-8859-1)
#sampleresult.default.encoding=ISO-8859-1
如果我们不想麻烦,就是说不愿意去花时间统一linux和windows的中文编码,那么除了上面提到的手动将文件(如etlCount.java)另存为UTF-8 -无BOM格式,再传到linux中运行的方法,也可以写个批处理,将从windows传过来的文件强制转为UTF-8格式,具体大家可以灵活应用:
iconv -f gbk -t utf-8 etlCount.java >etlCount.java.bak
mv -f etlCount.java.bak etlCount.java最后再说一种情况:同样是utf-8格式,Linux下创建的文件是不带BOM头的,那么到Windows下用相关软件比如Excel打开就会显示乱码,实际上Excel支持utf-8的中文显示,只是因为没有BOM头,所以导致格式判断和识别错误。解决的办法就是在Java中生成csv之类文件的时候,强制加上BOM头((byte)0xEF, (byte)0xBB, (byte)0xBF):
File file = new File("output.csv");
OutputStream out = new FileOutputStream(file);
out.write(new byte[]{(byte)0xEF, (byte)0xBB, (byte)0xBF});
out.write("date,CountName,业务库,数据中心,国家库,result\r\n".getBytes());
out.close();