写在前面:
R包都有自己的说明书(cheatsheet),俗称小抄。在对包有了一定的了解后,小抄是一个很好的学习操作指南,但是对于新手来说,很有可能完全看不懂。今天的教程有一部分参照了小抄,并作出了通俗的解释。相信跟着教程走下去,就可以学个七七八八,跟着练练,然后自己研究一下小抄,一个R包就学个差不多啦。
准备工作part1:学会获取一个R包的小抄
方法1:去百度/谷歌XX小抄
方法2:找Rstudio的cheatsheet网站(网速好慢的)
https://www.rstudio.com/resources/cheatsheets/
方法2.我们教程里用到的包都可以到生信星球公众号回复相应的包名来获取,比如这个:
。。。
准备工作part2:初步了解tidyr
(从这里开始到分割线以上的部分是我亲爱的谢师姐测试教程的时候提出让我加上的,先介绍一下这个包能干啥)
关于R包的学习不打算系统讲了,直接从这个名叫tidyr的包开始上手。这是一个数据处理的起步,相对来说属于R包里简单的了。
它的功能主要有:
(1)数据框的变形
(2)处理数据框中的空值
(3)根据一个表格衍生出其他表格
(4)实现行或列的分割和合并
这个包是把你要用的数据处理成标准而统一的数据框(Tidy Data,下面有解释),才能进行进一步的数据处理和作图,可以说是万里长征第一步!

准备工作part3--学习极简安装R包:
1.准备好Rstudio(恭喜你跳过了安装的坑),设置好工作目录。
在控制台输入:library(tidyr),如果你没有这个包,就会报错:
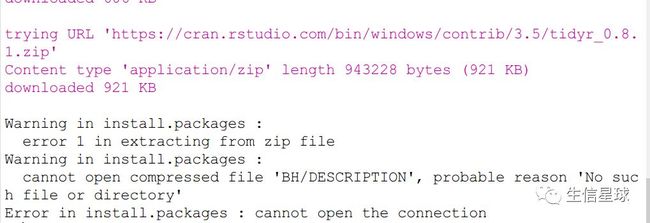
2.下载和安装tydir:install.packages("tidyr")
(这里会默认安装到你的工作目录里,下载很慢,只要控制台不出现>,就一直等着)
可能出现的报错:
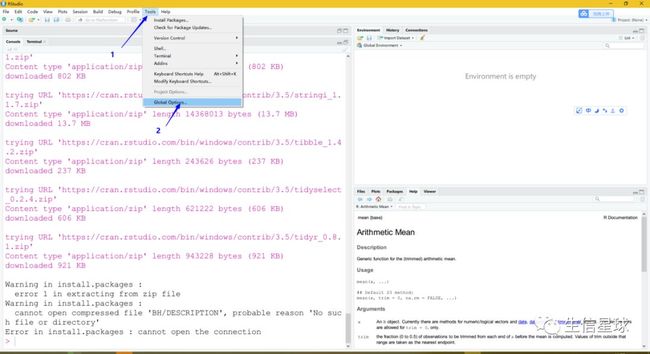
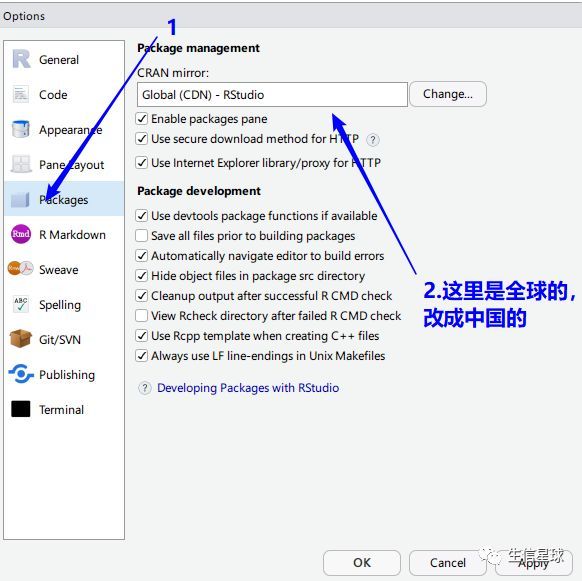
解决方案:换一个国内的镜像
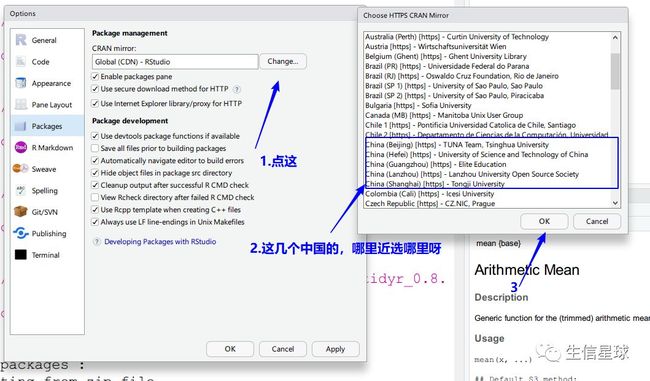
加载tydir:library(tidyr) (没有报错就是成功)
准备工作part2:数据框的小常识
1.新建数据框(这里直接把新建的数据框赋值给了a)
a<-data.frame(GeneId = rep("gene5",times=3),SampleName =paste("Sample",1:3,sep=""),Expression=c(14,19,18))
得到的数据框是

新建一个数据框并赋值给bioplanet这个变量(赋值符号<-还记得嘛)括号里是“列名”=列值,这里列名要加双引号。这里涉及的几个给列填充数值的函数有
rep,重复,括号中填要重复的字符和重复次数。
paste,连接两个字符串,括号要填两个代连接字符并指定分隔符(sep),没有分隔符就填sep=“”。
1:3表示从1到三。如需一列中需要填入三个无规律的数字,可以用向量c(1,3,4),同样如果填的是字符串也需要加双引号,例如c("doudou","huahua","xiaoyu")。
2.了解概念:key-value--“键值对” ,表示一种对应关系。“键”和“值”都是列名,如SampleName和Expression的对应。
3.函数后面一般都要加括号,括号里第一个参数是都数据框名
4.字符串要加双引号(行名和列名也是字符串,但是可以不用加),其他单元格(姑且这么叫了)里出现的字符串要加。
行 raw
列 column,简化写法为col
准备工作part3:认识Tidy Data
TidyData?泰迪数据是神马数据?我想到了如下两坨:

皮一下我就是很开心!皮完查字典去:

这是一种组织表格数据的方式,提供了一种能够跨包使用的“统一”的数据格式。
什么叫“统一”?
每个变量(variable)占一列,每个情况(case,姑且这么翻译)和观测值(observation)占一行。
举个栗子
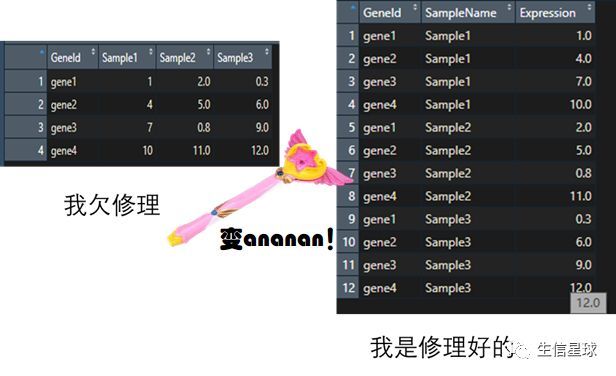
看到吗?一列是一列,是魔鬼的步伐。不要让sample1,2,3当列名,让他们多重复几遍,合并到一列。
数据由九宫格变成了一列,就可以用来跨包处理啦。
这就是实现了数据框的变形。
终于准备完了我的妈呀

1.Reshape Data
哦,我知道你想要魔法棒,来。
gather:我就是刚才的魔法棒
spread:我能让tidy data一夜回到解放前。
(下面的类似截图都是来自小抄)

在这里如何复制上图中的数据?(比较特殊的一点是列名是数字,这个还没碰见过,因此对它这个列名动了一点手脚,不管给他们加双引号、单引号还是反引号(英文模式下的1前面那个键),都没有报错!但是不加引号是不行滴。

但是我发现这个显示表格的时候,会自动在数字列名前面加上个x(大写的),就像这样
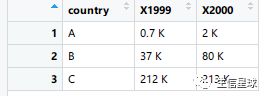
由于它自动加了X,写列名的时候就不能按照小抄上面写,而是:
gather(a,X1999,X2000,key = "year",value = "cases")
gather括号里的分别是:
数据框名,需合并的列名(两个),合并后的key列名,value列名。
其中,需合并的列名也可以列在最后(其实个顺序才是默认的),key=和value=也可以省略(我爱偷懒),如果按照上面小抄的命令括号里那个顺序,省略了就会报错。
gather(a,"year","cases",X1999,X2000) #推荐的偷懒做法

其中,合并前的列名如果比较多,可以用排除法来偷懒,在上图例子中可用
gather(a,year,cases,-country) #-country的意思就是合并除country外剩下的列。
2.Handle Missing Values
处理丢失的数据。就是某些单元格有空值的情况。
三种处理方式:
(1).删除整行
(2).根据上下文(瞎)蒙一个
(3).同一列的空值填上同一个数。

将示例数据放在你的RData文件夹下(!!!重要)
NA表示空值,所以新建的时候像我一样空着就好。
用以下命令即可获得图示数据框X
X<-read.csv('doudou.txt')
可能别人不会这么教,但我在这里之所以选择了csv,是因为这个神奇的支持R和Excel,默认参数好的很(默认分隔符是“,”,导出时也不会默认加引号。如果你用read.table试试就知道默认参数多笨了),并且转换txt也不会变乱码!(我自己发现的,想夸我千万别忍着)
在这里补充下csv的导入和导出方式。(默认参数好,学R没烦恼)
导入:X<-read.csv('doudou.csv')
导出:write.csv(X,'doudou.csv')
drop_na():有空值的,整行删除掉
括号里填数据框名,依据的列名(有空值那一列的列名)
drop_na(X,X2)
fill(),根据上一行的数值填充上(好应付的感觉)
fill(X,X2)
replace_na(),空值填进去特定的一个数值(还是在应付)
括号里填数据框名,要填的列名=要填的值
replace_na(X,list(X2=2))
3. Expand Tables

这个地方,好像就是凑数,目前我并不知道他有啥用。这部分的代码删掉了,在截图里面有。请手打哦
complete(把空值的位置补全)
可以直接用刚才的数据框X填充一下试试。比如填5

我用的数据是com.csv:
读取的命令是com <- read.csv("com.csv")
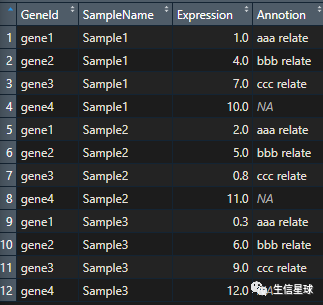
其中有三个空值,我要填充上ddd relate
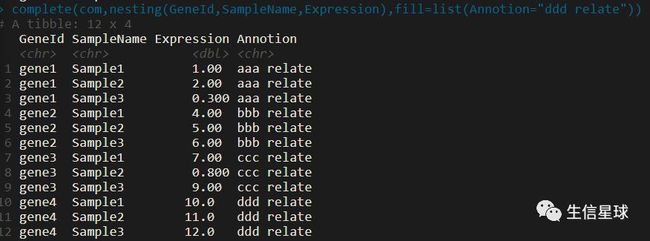
expand
(列出每列值所有可能的组合--根据下面的示例来理解这句话)
来看示例(以前年纪小不懂事,数据框名胡乱取的):
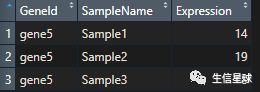
示例数据(就是刚才新建出来的数据框a):
pin2<-data.frame(GeneId = rep("gene5",times=3),SampleName =paste("Sample",1:3,sep=""),Expression=c(14,19,18))
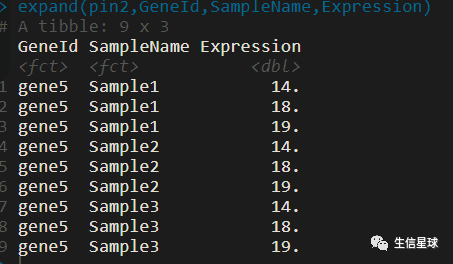
我是看到了结果才知道我干了啥的。就是选中的列中的值各种组合,成为一个新表。(明白?)
4.split cells(选修)
把一列拆成两列。目测原列必须要有分隔符才行啊好像。
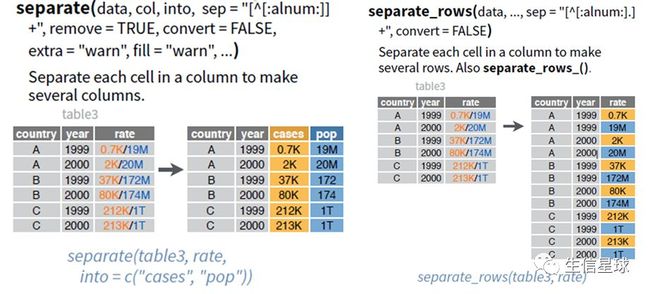
separate:按列分割
separate_rows:按行分割

unite:分割完了再合并回去