Python对象序列化
引言
我们知道在Python中,一切皆为对象,实例是对象,类是对象,元类也是对象。本文正是要聊聊如何将这些对象有效地保存起来,以供后续使用。
pickle与cPickle
pickle模块可以将Python对象转化成一系列字节,这些代表对象的字节流可以被传输或存储,然后再重构出一个拥有相同特征的新的对象。
cPickle模块的作用与pickle模块一样,只不过cPickle模块使用C而不是Python进行实现,因此比pickle要快好几倍。值得注意的是,cPickle不允许用户从cPickle派生子类,如果我们并不用从中派生子类的话,那么cPickle是个更好的选择。
警告:pickle不提供安全保证。如果我们在多线程通信或者数据存储中使用pickle,一定要小心,不要信任我们不能确定为安全的数据。
举例
一般来说,我们倾向于使用cPickle,不过为了一致性,我们可以这么写:
try:
import cPickle as pickle
except:
import pickle如果cPickle模块导入不成功,则导入pickle模块。下面我们以pickle为例,看看如何将Python对象序列化。
序列化
我们可以通过pickle.dumps(object)或者pickle.dump(object, file)将对象进行序列化。其中dumps返回一个字符串,它包含一个pickle格式对象;而dump则是将对象写到文件,这个文件可以是真实的物理文件,或者是任何类似于文件的对象,只需要具有write()方法,并接收单个的字符串参数即可。
>>> x = [{'a':1, 'b':2, 'c':3}, 'This is a string', 100]
>>> str = pickle.dumps(x)
>>> print str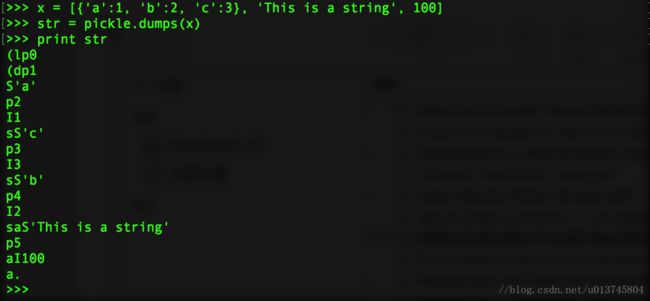
>>> x = [{'a':1, 'b':2, 'c':3}, 'This is a string', 100]
>>> file_1 = file('temp.pkl', 'wb')
>>> pickle.dump(x, file_1)
>>> file_1.close()
使用dump方法将对象写入文件其实就是将pickle格式对象写入文件了。这里有一点值得注意的,就是要记得file_1.close()。当然,为了避免我们忘了将文件关闭,也可以这么写:
>>> with open('temp.pkl', 'wb') as file_1:
... pickle.dump(x, file_1)反序列化
我们可以通过pickle.loads(string)或者pickle.load(file)将pickle格式对象变为Python中的一般对象,比如元组、字典、类实例等。其中loads返回包含在pickle字符串中的对象;load返回在pickle文件中的对象。
>>> y = pickle.loads(str)
>>> print y
>>> with open('temp.pkl', 'rb') as file_2:
... y = pickle.load(file_2)
...
>>> print y
需要注意的是,在load的时候,要让Python能够找到对象的类的定义,否则会报错。
多次序列化与反序列化
我们可以将多个Python对象序列化到同一个文件中:
>>> x1 = [{'a':1, 'b':2, 'c':3}, 'This is a string', 100]
>>> x2 = (1, 2, 3)
>>> x3 = 1024
>>> pickle.dump(x1, file_1)
>>> pickle.dump(x2, file_1)
>>> pickle.dump(x3, file_1)
>>> file_1.close()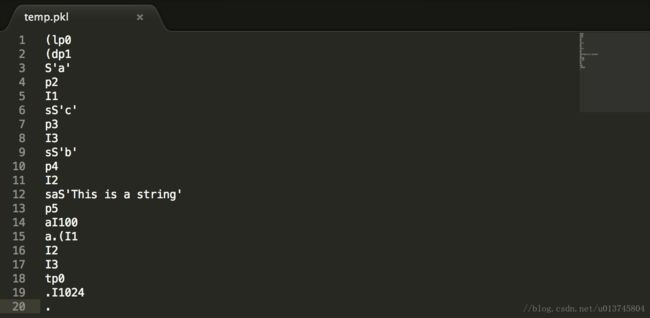
然后再将这些数据读取出来:
>>> file_2 = file('temp.pkl', 'rb')
>>> y1 = pickle.load(file_2)
>>> y2 = pickle.load(file_2)
>>> print y1
[{'a': 1, 'c': 3, 'b': 2}, 'This is a string', 100]
>>> print y2
(1, 2, 3)
>>> file_2.close()这里我们只读取pickle文件中的前两个数据对象。
联想
我们知道,在利用TensorFlow训练好模型之后,通常想将模型保存起来,这时候我们就可以用pickle模块了。当然,在保存和载入数据集的时候也可以用pickle模块,比如:
with open(pickle_file, 'rb') as file:
data = pickle.load(file)
train_dataset = data['train_dataset']
train_labels = data['train_labels']
test_dataset = data['test_dataset']
test_labels = data['test_labels'] 这里的file文件中保存的是一个字典,所以使用pickle.load(file)之后,data将以字典的形式存在,此时我们可以用Key-Value的方法对数据进行读取。
关于pickle模块更进一步的学习,大家可以阅读《Python pickle模块学习》。