1. 正则表达式的概念及特点:
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,
这个“规则字符串”用来表达对字符串的一种过滤逻辑。规定一些特殊语法表示字符类、数量限定符和位置关系,然后用这些特殊语法和普
通字符一起表示一个模式,这就是正则表达式(Regular Expression)。
给定一个正则表达式和另一个字符串,我们可以达到如下的目的:
1. 给定的字符串是否符合正则表达式的过滤逻辑(称作“匹配”);
2. 可以通过正则表达式,从字符串中获取我们想要的特定部分。
2. 正则表达式与通配符的关系
通配符用来匹配符合条件的文件名,通配符是完全匹配。ls、find、cp这些命令不支持正则表达式,所以只能使用shell自己的通配符来进行匹配了。
| 元字符 | 作用 |
|---|---|
| * | 匹配0个或任意多个字符,也就是可以匹配任何内容 |
| ? | 匹配任意一个字符 |
| [] | 匹配[ ]中任意一个字符 |
| [-] | 匹配括号中任意一个字符,-代表一个范围,例如:[a-z]代表匹配一个小写字母 |
| [^] | 逻辑非,表示匹配不是中括号内的一个字符,例如[^0-9]代表匹配一个不是数字的字符 |
| [!] | 逻辑非,表示匹配不是中括号内的一个字符,例如[!0-9]代表匹配一个不是数字的字符,同上 |
正则表达式用来在文件中匹配符合条件的字符串,正则是包含匹配。grep、awk、sed等命令可以支持正则表达式。以下以grep为例对正则表达式进行说明。
3. grep的主要参数:
-n : 输出结果开头显示匹配的行在源文件中的行号

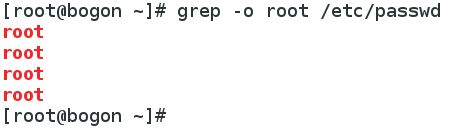
-o : 只显示匹配的内容
-q : 静默模式,没有任何输出。可用$?来判断执行成功没有,即有没有过滤到想要的内容。

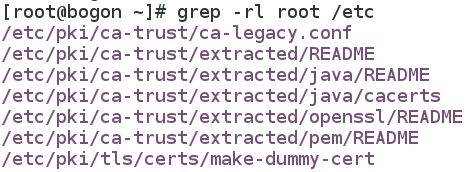
-l:如果匹配成功,则只将文件名打印出来,失败则不打印,通常-rl一起用
-A : 如果匹配成功,则将匹配行及其后n行一起打印出来

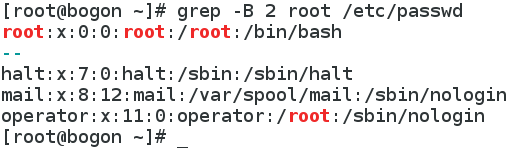
-B : 如果匹配成功,则将匹配行及其前n行一起打印出来
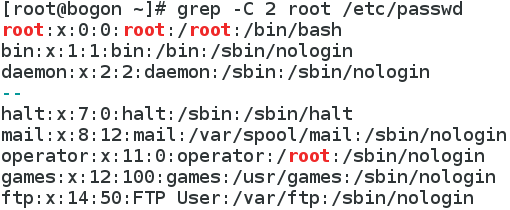
-C : 如果匹配成功,则将匹配行及其前后n行一起打印出来
--color:匹配的内容显示时的着色方式,系统默认是自动(auto)
![]()
-c : 如果匹配成功,则将匹配到的行数打印出来
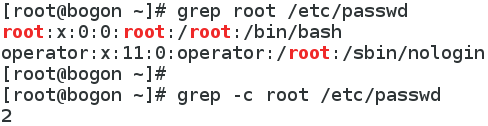
-E :等于egrep,扩展的正则表达式

-i :忽略大小写

-v :取反,不匹配

-w:匹配单词

4. 基础正则表达式和拓展正则表达式
grep一般情况下支持基本正则表达式;
可以通过参数-E支持扩展正则表达式,grep单独提供了一个扩展命令叫做egrep用来支持扩展正则表达式,其和grep -E等价;
此外,通过grep -P可支持Perl语言的正则匹配模式,更能更加灵活和强大;
本文以egrep或grep -E来进行总结,不具体区分基本正则表达式和拓展正则表达式,建议使用egrep或grep -E。
5. 正则表达式说明:
^ 行首

$ 行尾

. 除了换行符以外的任意单个字符

* 前导字符的零个或多个

.* 所有字符

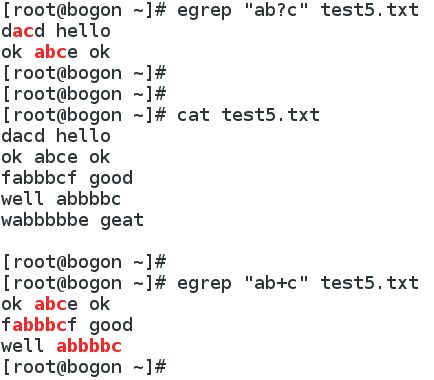
? 匹配前面的字符0次或1次

+ 匹配前面的字符1次或多次
{m} 匹配前面的字符m次

{m,n}匹配前面的字符m到n次

{m,}配置前面的字符至少m次

{,n}匹配之前的字符最多n次

[] 字符组内的任一字符,[a-z]匹配一个小写字母

[^] 对字符组内的每个字符取反(不匹配字符组内的每个字符)

| 匹配"|"左边的模式或者"|"右边的模式

()将多个字符视为整体,提高优先级
